Claude Haiku 4.5 Hands-On: Coding Ability Rivals Sonnet 4 at One-Third the Cost
Claude Haiku 4.5 delivers near-flagship coding performance at a fraction of the cost
Anthropic released Claude Haiku 4.5 with coding performance approaching flagship Claude 4 at one-third the price. It scored 73.3% on SWE Bench, surpassing Sonnet 4 in tool use and computer use. Hands-on tests show stable performance with outstanding cost-effectiveness for everyday development. Anthropic's prior quota cuts for premium models appear to have been strategic preparation for this launch.
Overview: Anthropic's Strategic Release
Anthropic recently released Claude Haiku 4.5, claiming its coding performance approaches that of the flagship Claude 4 model from five months ago—at one-third the price and more than double the speed. Combined with Anthropic's recent drastic cuts to compute quotas, this release is clearly a calculated product strategy: create pain points first, then offer a cost-effective solution.
Before launching Haiku 4.5, Anthropic significantly reduced Sonnet and Opus usage quotas for Pro subscribers, with many users reporting over 50% cuts to their daily usage. This "create the problem, then offer the solution" approach isn't uncommon in SaaS—restricting free/low-cost access to premium products to guide users toward more cost-effective alternatives or higher-priced subscription tiers. This also reflects the commercialization pressure facing large model companies in the AI arms race, as they seek balance between user experience and operational costs.
Impressive Benchmark Performance
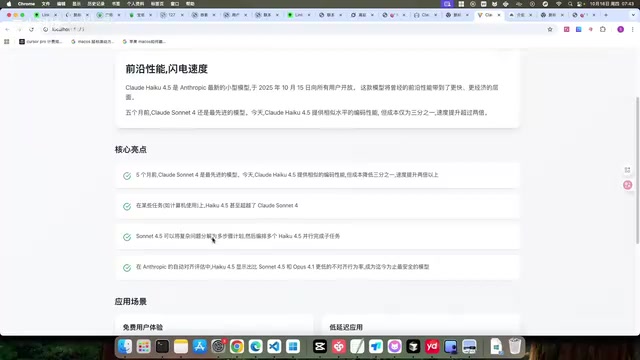
Haiku 4.5 scored 73.3% on SWE Bench, slightly above Sonnet 4 and approaching GPT-5 Codex levels. SWE Bench (Software Engineering Benchmark) is a standardized evaluation developed by Princeton University researchers, specifically testing AI models' ability to solve real-world GitHub issues. It extracts 2,294 real bug-fix tasks from 12 popular Python open-source projects, requiring models to autonomously modify codebases after understanding problem descriptions. A 73.3% score means the model can independently solve nearly three-quarters of real software engineering problems—a level unimaginable just a year ago.
Key highlights:
- Agent Coding score approximately 5 percentage points above Claude 4
- Agent tool use at 83%, far exceeding Claude 4's 9.6%
- Computer use at 50.7%, surpassing Sonnet 4's 42.2%
- Lowest misalignment behavior rate in safety evaluations
Agent Coding refers to AI models' programming ability when operating in autonomous agent mode—not just generating code snippets, but autonomously planning tasks, reading file systems, executing commands, debugging errors, and iterating improvements. The Tool Use score measures accuracy and efficiency in calling external tools (file I/O, terminal commands, browser operations, etc.). Haiku 4.5's 83% versus Claude 4's 9.6% represents a qualitative leap in understanding when and how to invoke tools—critical for building autonomous coding assistants.
Notably, Alignment (a coding tool) has also incorporated Haiku 4.5 into its software, with evaluations showing it reaches 90% of Sonnet 4.5's performance. Alignment is a development tool platform focused on AI-assisted programming that evaluates different models through standardized code generation tasks. Reaching 90% of Sonnet 4.5's performance means that in actual development workflows, the cheaper Haiku 4.5 sacrifices only about 10% in code quality while saving significant API costs. This third-party independent evaluation provides important cross-validation of official benchmarks.
Practical Coding Test Comparisons
The video author used Claude Code to complete three programming tasks with Haiku 4.5, Sonnet 4.5, and Opus 4.1:
Weather Card
Haiku 4.5 produced simpler styling but fully functional output with working animations; Sonnet 4.5 had better styling but animation bugs; Opus 4.1 delivered the best results.
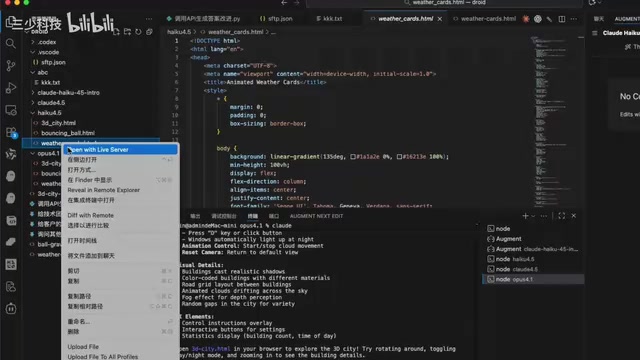
Ball Drop Physics Simulation
Haiku 4.5's balls had bounce effects and performed well; Sonnet 4.5 actually underperformed compared to Haiku; Opus 4.1 had the most realistic physics.
3D Scene Rendering
Haiku 4.5 was functional but average in aesthetics; Sonnet 4.5's scene was non-interactive—a complete failure; Opus 4.1 was near-perfect, including clouds, window details, and day/night cycling.
Cost-Effectiveness Analysis
Overall, Haiku 4.5's coding ability genuinely approaches and in some scenarios surpasses Sonnet 4, at roughly one-tenth the cost of Opus 4.1. Anthropic uses a three-tier model architecture: Haiku (lightweight/fast), Sonnet (balanced), and Opus (flagship), similar to OpenAI's GPT-4o mini/GPT-4o/o1 series. Haiku 4.5's input price is $0.80 per million tokens with $4 output; Opus-level models can reach $15/million tokens input and $75/million tokens output. For high-frequency development scenarios, this 10x+ price difference means monthly costs could drop from thousands to hundreds of dollars—decisive for small teams and indie developers.
For everyday development tasks, Haiku 4.5 offers extremely competitive value. Complex multi-file projects still warrant Sonnet or GPT-5, but for simple to moderate coding tasks, Haiku 4.5 is more than sufficient.
Key Takeaways
- Claude Haiku 4.5 costs one-third of Claude 4, runs twice as fast, with coding ability approaching Sonnet 4
- SWE Bench score of 73.3%, surpassing Sonnet 4 in computer use and tool calling
- In hands-on testing, Haiku 4.5 performed consistently across 3 coding tasks, outperforming Sonnet 4.5 in some scenarios
- Opus 4.1 delivers the best results but costs 10x+ more; Haiku 4.5 offers outstanding value
- Anthropic's prior quota cuts appear to have been groundwork for promoting Haiku 4.5
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.