#SWE Bench
7 related articles
·2 min
ViBench: A Benchmark Designed Specifically for Evaluating AI Application Building Capabilities
Deep dive into ViBench, a benchmark addressing SWE-bench's gaps in evaluating AI application building through end-to-end generation, visual quality, and functional completeness.
Read more →
·2 min
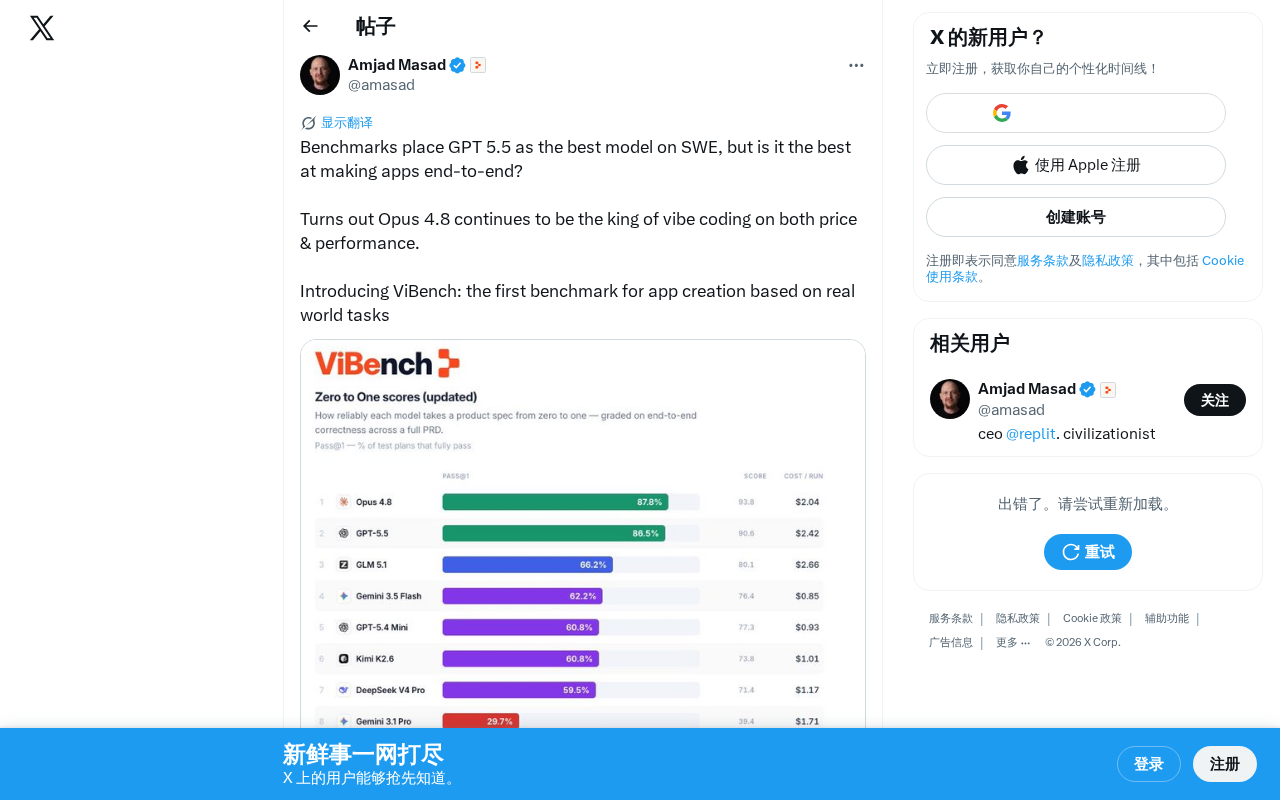
ViBench Benchmark: End-to-End App Creation Evaluation Reveals the True Level of AI Programming
ViBench is the first end-to-end app creation benchmark based on real-world tasks. Results show Claude Opus 4.8 leads in performance and cost-effectiveness, revealing gaps between SWE-bench scores and actual development capability.
Read more →
 Product Reviews
Product Reviews·1 min
Claude Haiku 4.5 Hands-On: Coding Ability Rivals Sonnet 4 at One-Third the Cost
Hands-on testing of Claude Haiku 4.5's coding ability, comparing it with Sonnet 4.5 and Opus 4.1 across weather cards, physics simulation, and 3D rendering tasks.
Read more →
 Product Reviews
Product Reviews·2 min
GPT-5.5 vs DeepSeek-V4: Who Wins in a Four-Round Head-to-Head Test?
GPT-5.5 vs DeepSeek-V4 in four comprehensive rounds covering world knowledge, context memory, logical reasoning, and coding — a detailed comparison of real performance differences.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
AI Weekly: Kimi K2.6 Tops Open-Source Rankings, Qwen 3.6 and Google TTS Launch Together
Weekly AI roundup: Kimi K2.6 tops open-source rankings, Anthropic launches Opus 4.7 and Claude Design, Alibaba rolls out Qwen 3.6 series, Google releases emotion-controllable TTS model.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
DeepSeek OCR2, Kimi K2.5, and Microsoft Maia 200 All Launched on the Same Day
DeepSeek releases OCR2 replacing CLIP with an LLM as visual encoder; Moonshot AI launches Kimi K2.5 with 100+ sub-agent cluster mode; Microsoft deploys 3nm Maia 200 chip; Alibaba releases Qwen3 Max Thinking.
Read more →