Complete AI Large Language Model Learning Roadmap: From Beginner to Production-Ready

A complete LLM learning roadmap covering fundamentals, RAG, Agents, fine-tuning, and enterprise projects.
This guide breaks down a systematic learning path for AI large language models, structured in three stages: fundamentals (Transformer architecture, prompt engineering, API usage), advanced topics (RAG, AI Agents, model fine-tuning with LoRA/QLoRA, LangChain/LangGraph), and hands-on enterprise projects (knowledge bases, AI customer service, medical Q&A, digital humans).
Why Systematic Learning Matters for LLMs
With the rapid development of large language model technology, more and more people want to break into this field. However, while platforms like YouTube already have countless related tutorials — ranging from a few dozen views to millions — they commonly share one problem: they're not systematic or comprehensive enough. Many tutorials either focus solely on theory without hands-on practice, or cover scattered knowledge points without providing a complete path from beginner to expert.

Recently, a systematic LLM tutorial series claiming to contain "749 episodes total" appeared online, reportedly taking three months to produce and covering three major stages: fundamentals, advanced topics, and hands-on projects. Setting aside the marketing language, the knowledge architecture of this course is genuinely worth dissecting — even if you don't plan to follow along, understanding a complete LLM learning roadmap is valuable in itself.
Fundamentals: Building Your LLM Knowledge Foundation from Scratch
According to the course introduction, the foundational stage covers these core modules:
- LLM Basic Concepts: Understanding what large language models are, their capability boundaries, and application scenarios
- AI Development Environment Setup: Python environment configuration, relevant library installation, and other preparatory work
- Transformer Core Architecture: The cornerstone of all modern large models — understanding attention mechanisms, encoder-decoder structures
- Prompt Engineering: Learning how to communicate effectively with large models
- API Integration: Mastering the use of APIs from OpenAI and other major model providers

The design philosophy of this foundational stage is sound. For absolute beginners, understanding Transformer architecture is a watershed moment — many people give up at this point. If these concepts like self-attention mechanisms and positional encoding can be explained in accessible terms, it can genuinely save newcomers from many detours.
The Transformer architecture was first introduced by a Google team in the landmark 2017 paper Attention Is All You Need, originally designed for machine translation tasks. It completely abandoned the sequential processing approach of the then-dominant Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs), instead relying entirely on attention mechanisms to capture dependencies between any two positions in an input sequence. This parallelized design not only dramatically improved training efficiency but also enabled the model to better handle long-range dependencies. Self-Attention is its core component, allowing every element in a sequence to "attend" to all other elements and dynamically assign weights based on relevance. Positional Encoding compensates for Transformer's lack of inherent sequence order awareness by assigning unique identifiers to each position through sinusoidal functions or learnable embedding vectors. Later, the GPT series adopted a Decoder-only architecture, BERT adopted an Encoder-only architecture, and models like T5 retained the full encoder-decoder structure — understanding the differences between these variants is an important foundation for deeper LLM study.
The Importance of Prompt Engineering
It's worth noting that prompt engineering is placed in the fundamentals section rather than the advanced section, and this arrangement is correct. In practice, the vast majority of people interact with large models through prompts. Mastering prompt engineering can dramatically boost productivity even without writing a single line of code.
Prompt Engineering is a systematic discipline studying how to design and optimize input prompts to guide large models toward desired outputs. Its core principle is that a model's output quality largely depends on the quality and structure of the input. Common prompt techniques include: Zero-shot prompting, which directly describes the task for the model to complete; Few-shot prompting, which provides several examples to guide the model in understanding task patterns; Chain-of-Thought (CoT) prompting, which asks the model to reason step by step to improve accuracy on complex problems; and more advanced strategies like Tree-of-Thought and Self-Consistency. Companies like OpenAI and Anthropic have published official prompt engineering best practice guides covering dimensions such as role assignment, task decomposition, and output format constraints. In enterprise settings, prompt engineer has already emerged as a new job role, responsible for designing and iterating prompt templates for specific business scenarios — which is exactly why placing it in the foundational stage is a wise decision.
Advanced: The Three Core Technology Pillars — RAG, Agents, and Fine-tuning
The advanced stage focuses on three key directions: RAG (Retrieval-Augmented Generation), Agents, and Model Fine-tuning.
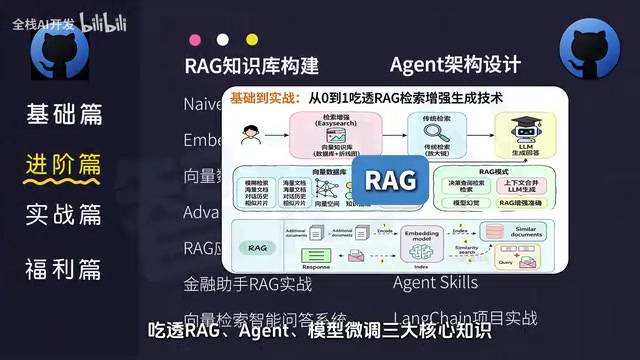
RAG: Giving LLMs Their Own Knowledge Base
RAG technology is currently one of the most mainstream approaches for enterprise LLM deployment. By combining external knowledge bases with large models, it solves the problems of model "hallucination" and knowledge currency. Learning RAG requires mastering a series of technologies including vector databases, document chunking, and embedding models.
It's necessary to explain the concept of LLM "hallucination" here — it refers to the model generating content that appears plausible but is actually incorrect or entirely fabricated. This is an inherent flaw of large language models, rooted in the fact that the model's training objective is to predict the next most likely token rather than verify factual accuracy. Hallucination problems are particularly dangerous in fields with high accuracy requirements such as healthcare, law, and finance, which is precisely the important context behind RAG's creation.
RAG (Retrieval-Augmented Generation) was first proposed by Meta AI in 2020. Its core idea is to retrieve relevant information from an external knowledge base before the model generates an answer, then inject the retrieved content into the prompt as context, allowing the model to generate responses based on this real information. This technology stack involves several key components: first, document processing and chunking, which requires splitting long documents into retrieval-friendly segments by semantic meaning or fixed length; second, embedding models (such as OpenAI's text-embedding-ada-002, open-source BGE series, etc.) that convert text into high-dimensional vector representations; third, vector databases (such as Milvus, Pinecone, Chroma, Weaviate, etc.) for efficient storage and retrieval of these vectors; and finally, optimization steps like reranking and context compression. RAG's advantages over model fine-tuning include: no need to retrain the model, real-time knowledge updates, traceable information sources, and lower costs. The industry is currently exploring advanced approaches like GraphRAG (knowledge graph-based RAG) and Agentic RAG (adaptive RAG combined with Agents) — these are all evolving directions worth continued attention.
Agents: Giving LLMs Execution Capabilities
Agents transform large models from mere "chatbots" into intelligent entities capable of calling tools, executing tasks, and performing multi-step reasoning. This is one of the hottest technology directions currently and the core form of future AI applications.
The concept of AI Agents originates from classical artificial intelligence theory but has been given entirely new meaning in the LLM era. Modern AI Agents use large language models as their "brain," possessing the ability to perceive environments, make autonomous decisions, invoke tools, and execute actions. Their core architecture typically includes four modules: Planning — decomposing complex tasks into executable sub-steps; Memory — including short-term conversation context and long-term experience storage; Tool Use — calling external tools such as search engines, code executors, and database queries; Action — executing specific operations and observing results. Since 2023, open-source projects like AutoGPT and BabyAGI ignited the Agent trend, while OpenAI's Function Calling and Anthropic's Tool Use capabilities have provided standardized interfaces for Agent development. Multi-Agent collaboration is a current frontier direction, where multiple Agents with different roles and capabilities can work together to complete complex tasks, with frameworks like Microsoft's AutoGen and CrewAI driving the development of this paradigm.
Fine-tuning: Building Domain-Specific Models
When general-purpose large models can't meet the needs of specific scenarios, fine-tuning becomes necessary. The course mentions covering mainstream frameworks like LangChain and LangGraph, which are indeed the de facto standards for current LLM application development.
Model fine-tuning refers to further training a pre-trained large model using domain-specific or task-specific data to improve the model's performance in that domain. Current mainstream fine-tuning methods have shifted from full parameter fine-tuning to Parameter-Efficient Fine-Tuning (PEFT), with the most representative being LoRA (Low-Rank Adaptation), which achieves efficient fine-tuning by injecting low-rank decomposition matrices into the model's weight matrices, requiring only 0.1%-1% of the original model's parameter count for training, dramatically reducing computational resource requirements. QLoRA further combines 4-bit quantization technology, making it possible to fine-tune 7B or even 13B parameter models on consumer-grade GPUs — a significant breakthrough for individual developers and SMEs.
Regarding development frameworks, LangChain is currently the most popular LLM application development framework, providing modular components including Chains, Agents, Memory, and Retrieval, greatly simplifying the development process for RAG and Agent applications. LangGraph is an advanced framework from the LangChain team, based on the concept of directed graphs to orchestrate complex multi-step AI workflows, supporting loops, conditional branching, and state management — particularly suitable for building complex Agent systems and multi-turn interaction applications. Mastering these two frameworks essentially equips you with the technical capability to develop mainstream LLM applications.
Hands-On Projects: Real-World Enterprise Applications
The hands-on stage is the critical phase for validating learning outcomes. The course lists several typical projects:
- Enterprise RAG Knowledge Base: The most common enterprise-level application scenario
- AI-Powered Customer Service: A comprehensive project combining RAG and dialogue management
- AI Medical Q&A System: A specialized application in a vertical domain
- Agent-Based Digital Human: A cutting-edge project integrating multimodal technologies

These project selections cover the most mainstream LLM application directions in the current market. Enterprise RAG knowledge bases and AI customer service in particular are scenarios that virtually every company integrating LLMs will prioritize, offering strong practical value and job market competitiveness. According to reports from multiple consulting firms, RAG knowledge bases and intelligent customer service are the two scenarios with the highest enterprise LLM deployment penetration rates. The former transforms massive internal documents, manuals, and regulations into instantly queryable intelligent knowledge systems, while the latter significantly reduces customer service labor costs and improves response speed and consistency. The AI medical Q&A system represents the typical challenges of vertical domain applications — requiring handling of professional terminology, ensuring answer accuracy and safety, and meeting healthcare industry compliance requirements. The Agent-based digital human project combines large language models, text-to-speech (TTS), automatic speech recognition (ASR), and even digital avatar generation — making it the most technically comprehensive hands-on project.
A Realistic Perspective: Learning Recommendations and Caveats
While this course's knowledge architecture appears fairly comprehensive, we need to maintain a realistic perspective:
First, 749 episodes require a massive time investment. Learners need to assess their own time and energy, develop a reasonable study plan, and avoid blindly bookmarking content that will never be revisited.
Second, LLM technology iterates extremely fast. Some content may become outdated quickly. When studying, focus on understanding underlying principles rather than memorizing the usage of specific tools. Taking 2024 as an example, from GPT-4 Turbo to Claude 3.5 to open-source Llama 3.1 and Qwen 2.5, the pace of model capability advancement far exceeded expectations, and the accompanying toolchains and best practices continue to evolve. Therefore, building solid theoretical foundations (such as Transformer principles, attention mechanisms, training paradigms) holds more long-term value than mastering a specific API version.
Third, practice always trumps theory. Completing tutorials is just the first step — real skill improvement comes from building projects, encountering problems, and solving them. It's recommended to immediately put each module into practice after completing it.
Fourth, free resources require quality discernment. The advantage of free online tutorials is zero cost, but you should also be careful to evaluate content quality and cross-reference multiple sources and official documentation when necessary. It's recommended to also follow official documentation from major model providers (such as OpenAI Cookbook, LangChain official docs), the latest papers on arXiv, and quality open-source projects on GitHub, forming a multi-dimensional learning resource matrix.
Conclusion
From a knowledge architecture perspective, this course covers the complete path of LLM learning from fundamentals to hands-on projects. The three-stage structure of "Fundamentals → Advanced → Hands-on" also follows the general pattern of technical learning. For beginners who want to systematically study large language models, it can at minimum serve as a solid learning roadmap reference. But whether you ultimately succeed in your learning depends on your own execution and sustained commitment.
Related articles
AI Agent Core Architecture Breakdown: From Concept to Enterprise-Grade Intelligent Agent Development
Deep dive into AI Agent architecture: perception, brain, and action modules. Covers RAG memory systems, tool calling mechanisms, Chain of Thought reasoning, and enterprise agent development roadmap.
Hands-On Tutorial: Build an AI Agent from Scratch with 200 Lines of Python
Build an AI Agent from scratch with 200 lines of Python, covering prompts, memory, tool calling, RAG, and Skills — a practical guide for developers.
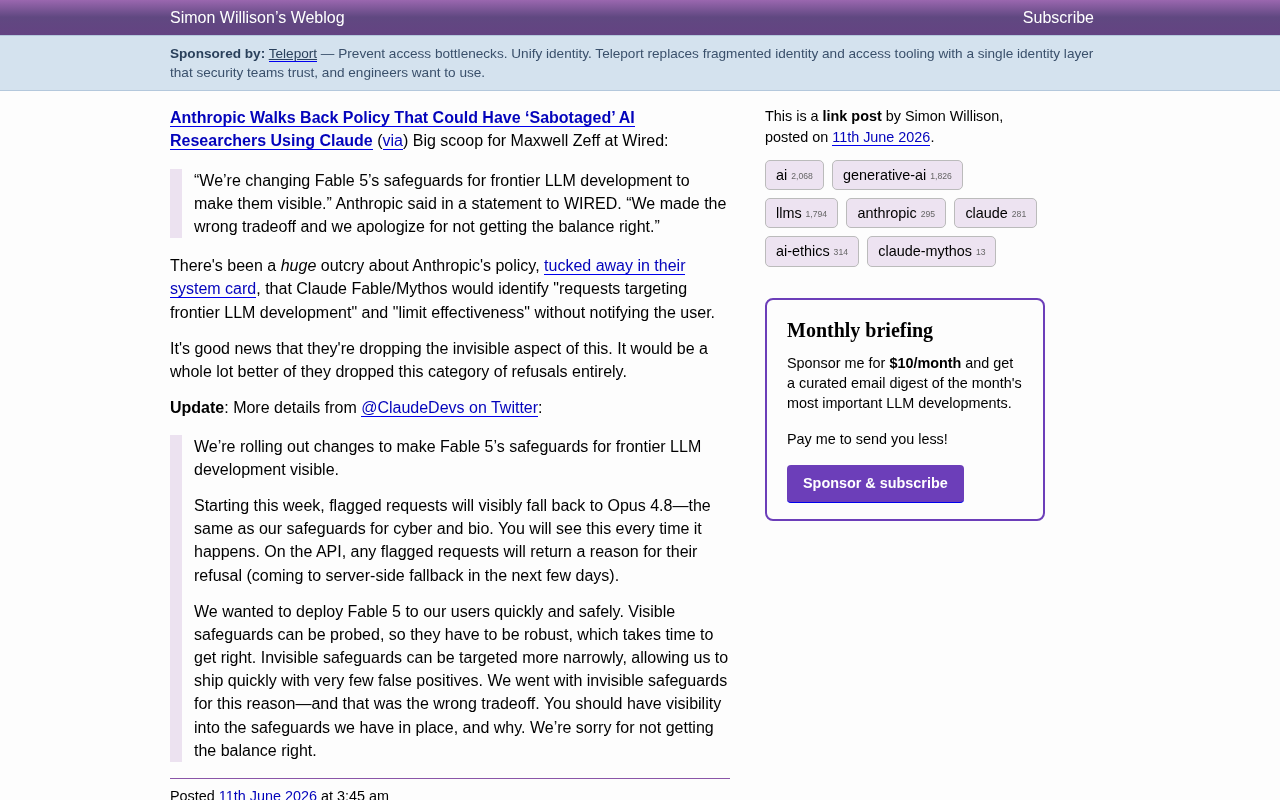
Anthropic Reverses Controversial Policy of Secretly Throttling AI Researchers Using Claude
Anthropic reverses its controversial policy of secretly throttling Claude Fable/Mythos responses to frontier LLM development requests after community backlash, raising critical questions about AI transparency.