CosyVoice v3.5 in Practice: Solving the Performance Direction Challenge in AI Voice Acting
Testing CosyVoice v3.5 as a more stable alternative to Doubao TTS for AI multi-character voice acting.
A Bilibili creator shares hands-on experience switching from Doubao TTS to Alibaba's CosyVoice v3.5 for AI voice acting. The article covers Doubao's frustrating bug of reading performance directions aloud, CosyVoice v3.5's natural language instruction control and pronunciation correction (HotFix) features, the surprisingly simple voice design workflow, and a practical demo-first debugging methodology for integrating AI speech services.
Introduction: The "Train Wreck" Dilemma of AI Voice Acting
In real-world AI multi-character voice acting production, stability often matters more than quality. Bilibili creator "PoWang" encountered a maddening problem during his long-term use of Doubao TTS for video voiceovers — the AI would literally read the performance direction text aloud. This seemingly absurd bug is a real headache for every power user of AI voice acting.
In this video, he turned to testing Alibaba's CosyVoice v3.5 and discovered what may be a more stable technical approach.
Doubao TTS: The Stability Pain Points
Performance Directions Get "Read Aloud"
When using Doubao for AI voice acting, users typically include performance direction information in the text — for example, annotating that a particular line should be read in a "joyful, excited" tone. Under normal circumstances, Doubao correctly interprets these instructions over 90% of the time, synthesizing speech that matches the emotional requirements.
However, roughly 1 out of every 100 lines goes off the rails — instead of adjusting the tone according to the instructions, the AI reads the direction text like "joyful, excited" aloud as part of the script. For a 10-minute video with approximately 100 lines of dialogue, this means almost every episode gets hit.
The root cause lies in the architectural design of modern TTS systems. TTS (Text-to-Speech) technology has evolved through three stages: concatenative synthesis, parametric synthesis, and today's deep learning-based neural network synthesis. Modern TTS systems typically employ end-to-end neural network architectures that can directly generate high-quality speech waveforms from text. "Performance direction" refers to appending control information such as emotion, tone, and speaking rate to the input text, so the synthesis engine can reference this metadata to adjust prosody and expressiveness during generation. The technical challenge of this mechanism is that the model must accurately distinguish between "text that needs to be read aloud" and "meta-information used to control synthesis behavior" — this is essentially an Instruction Following problem. When the model's instruction comprehension falters, it ends up reading the control information as if it were part of the script.
Extremely High Debugging Costs
What makes this even trickier is that these errors appear completely at random, with no way to predict which line will fail. Creators are forced to listen through every single synthesized audio clip, checking them one by one. Once a problem is found, re-synthesizing usually fixes it, but this "Schrödinger's Bug" makes the entire workflow extremely inefficient.
Additionally, Doubao has an "over-responsiveness" issue with speed control. When performance directions simultaneously specify a slower pace and emphasis requirements, the synthesized result can become abnormally slow, with adjustments far exceeding expectations. This lack of controllability is the core reason driving creators to seek alternatives.
CosyVoice v3.5: Alibaba's Instruction Control Approach
Version Differences: v3 vs v3.5
Alibaba's CosyVoice series comes in multiple versions, and the capability differences between them are worth noting:
- CosyVoice v3: Supports system-preset voice profiles, ready to use out of the box, but with limited performance control — users can only choose from predefined emotion tags (joy, sadness, frustration, etc.), and the speech output tends to sound stiff.
- CosyVoice v3.5 Plus: Supports free-form voice instruction control with significantly improved performance flexibility, but does not support system-preset voice profiles — users need to design voices themselves.
CosyVoice is a large-scale speech synthesis model developed by Alibaba's Tongyi Lab. Its technical approach combines Large Language Models (LLMs) with diffusion models. Unlike traditional TTS systems, CosyVoice adopts a "speech tokenization" approach — first encoding speech signals into discrete speech tokens, then leveraging the sequence generation capabilities of large language models to predict these tokens, and finally using a vocoder to convert the tokens back into continuous speech waveforms. This architecture gives the model an inherent ability to understand natural language instructions, since its core inference engine is itself a language model. The v3.5 version further strengthens instruction control capabilities, allowing users to fine-tune emotion, speaking rate, timbre, and other dimensions through natural language descriptions, rather than relying on predefined discrete labels.
The reason the creator hadn't previously explored v3.5 in depth was precisely because it requires an additional voice design step. But after thorough research, this process turned out to be simpler than expected.
Voice Design: Simpler Than You'd Think
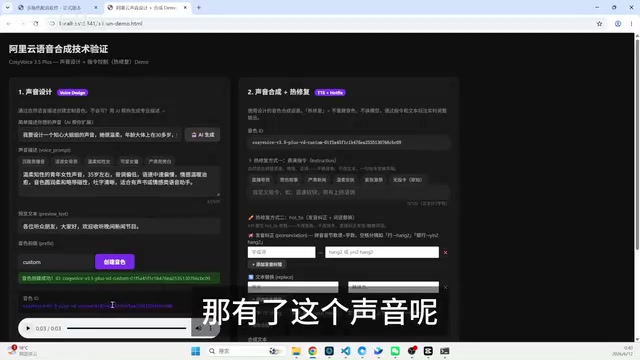
The voice design workflow can be completed through natural language descriptions. For example, describing to the system "a voice of a sophisticated older-sister type, gentle, in her 30s, with a white-collar executive vibe and a mature feminine style" will prompt the system to generate corresponding voice parameters.
Voice Design is an alternative approach to obtaining voice profiles compared to Voice Cloning. Voice cloning requires providing reference audio of the target speaker, with the model extracting a Speaker Embedding to reproduce their tonal characteristics. Voice design, on the other hand, generates entirely new voice profiles based purely on text descriptions — no reference audio needed. This relies on the "semantic-to-timbre mapping" the model has learned from large-scale speech data — the model understands the correspondence between descriptive terms like "gentle," "mature feminine," and "in her 30s" and their acoustic features, enabling it to synthesize voices that match expectations based on descriptions. The advantage of this approach is its extreme flexibility and the fact that it doesn't involve copyright issues with real human voices, making it particularly suitable for content creation scenarios requiring numerous fictional characters.
In testing, the system generated a voice profile for a "gentle, confident female voice, age 35" based on the description, and the synthesized output was natural and fluid. The generated voice ID can be directly embedded into the voice acting workflow.
Instruction Control and Pronunciation Correction
Two practical capabilities of CosyVoice v3.5 stand out:
Voice Instruction Control: Tone and emotion can be controlled through natural language descriptions. For example, setting instructions like "gentle and soothing" or "nervous" will cause the same text to exhibit noticeably different performance styles under different instructions. In testing, the sentence "The weather is so nice today, let's go queue at the bank together" showed significant yet natural tonal differences under the "gentle and soothing" versus "nervous" instructions.
Pronunciation Correction (HotFix): This is a practical feature the creator uncovered. When encountering polyphonic characters or special pronunciation needs, users can directly specify the pronunciation. For example, specifying that "行" should be read in the second tone (xíng), or replacing the pronunciation of "天天" with "dayday." This level of fine-grained control is very difficult to achieve in Doubao.
A classic challenge for Chinese TTS systems is Polyphone Disambiguation. Chinese contains numerous polyphonic characters — for instance, "行" can be read as háng or xíng, and "缝" can be read as féng or fèng — with the correct pronunciation depending on contextual semantics. Traditional approaches rely on part-of-speech tagging and language models in the front-end text analysis module to automatically determine pronunciation, but these still frequently fail in complex contexts or uncommon usages. The HotFix mechanism provides a "manual fallback" solution, allowing users to directly specify the pronunciation of a character or word at the API level, bypassing the model's automatic judgment. This design philosophy embodies the "AI + Human" collaborative engineering approach — letting AI handle the majority of routine cases while preserving a fine-grained intervention interface for humans, striking a balance between automation efficiency and controllability.
The creator specifically mentioned a classic case encountered while using Doubao — a pronunciation issue with the word "裂缝" (crack/fissure) that couldn't be resolved no matter how adjustments were made (the system kept reading it incorrectly). CosyVoice v3.5's pronunciation correction parameter can directly solve this type of problem.
LLM Debugging Methodology: Demo First, Then Integrate
The video also shared an engineering practice worth adopting:
- Read the documentation first: Thoroughly understand the API docs and the capability boundaries of each parameter
- Build demos for validation: Write individual test scripts for each distinctive parameter to quickly verify results
- Integrate into the project: Only after demo validation passes, integrate into the complete voice acting workflow
- Feedback and fix: Record issues encountered during actual use and iterate promptly
This "small steps, fast iterations" debugging strategy avoids the high cost of troubleshooting bizarre LLM issues within a complete project. Especially for AI services like TTS that have numerous parameters and not entirely predictable behavior, a demo-driven development approach can significantly boost efficiency. This methodology aligns with the "Prototyping" concept in software engineering — validating core assumptions at minimal cost before investing heavily in integration work. For AI services, given the inherent randomness and opacity of model behavior, this incremental validation strategy is particularly important. It helps developers quickly build intuitive understanding of model capability boundaries, avoiding hard-to-diagnose systemic issues during the integration phase.
Conclusion and Outlook
Based on hands-on experience, CosyVoice v3.5 demonstrates advantages over Doubao in the precision and predictability of instruction control. While it requires an additional voice design step, the trade-off is more stable performance control and more precise pronunciation correction capabilities.
For power users of AI voice acting, a "dual-engine" strategy may be the most pragmatic choice right now — leveraging the respective strengths of different TTS services to find the optimal balance between stability and quality. The Chinese AI speech synthesis space is currently highly competitive, with major players including ByteDance (Doubao/Volcano Engine TTS), Alibaba (CosyVoice/Tongyi Speech), iFlytek (Spark Speech Synthesis), Baidu (ERNIE Speech), and a wave of startups and open-source projects like Fish Audio and ChatTTS. Each has different technical approaches and product positioning: Doubao TTS excels in rich preset voice profiles and ease of use, CosyVoice focuses on instruction control and open-source ecosystem development, while open-source solutions like ChatTTS offer developers greater customization freedom. For content creators, different TTS services have varying strengths and weaknesses across dimensions like voice naturalness, emotional expressiveness, stability, latency, and cost — adopting a multi-engine combination strategy has become common industry practice.
As CosyVoice v3.5 continues to iterate, Alibaba's competitiveness in the AI speech synthesis space is rapidly growing.
Key Takeaways
Related articles
Microsoft Build 2026: In-Depth Analysis of the In-House Reasoning Model MAI Thinking-E and the Full AI Product Suite
Microsoft Build 2026 unveils MAI Thinking-E, its first in-house reasoning model with 1T MoE architecture, plus 6 vertical AI models. Deep dive into performance, strategy, and industry trends.
Deep Dive into Claude Sonnet 4: Replicating Lovable with Just Two Prompts
Deep dive into Claude Sonnet 4: replicate Lovable with two prompts, generate McKinsey-grade reports, build 2D games, and explore the AI Agent building block economy.
Replit's Domain-Specific Agents: One-Click Batch Fixes for SEO and Security Vulnerabilities
Deep dive into Replit's domain-specific AI Agents: Growth Agent for SEO issues and Security Agent for vulnerability detection, with select-all one-click batch fixing.