Deep Dive into Three Major LLM Career Paths: Requirements, Tech Stacks, and Career Prospects
Deep Dive into Three Major LLM Career …
Comprehensive breakdown of three core LLM career paths: requirements, tech stacks, and career outlook
This article systematically analyzes three core LLM roles: Application Engineer (lowest barrier, focused on agent and RAG development, 1-2 year window), Development Engineer (requires fine-tuning and inference optimization skills, strong demand for 3-5 years), and Algorithm Engineer (requires top-tier Master's degree plus publications, 10-20 year golden period). It also highlights that qualified developers must master six model types, enterprise deployment requires distributed inference frameworks like vLLM rather than Ollama, and advises choosing a direction that matches your positioning.
Introduction
As LLM-related positions explode across the job market, more and more developers are eyeing career opportunities in this field. However, information about LLM roles is scattered and often misleading—many people lack a clear understanding of job requirements, technical barriers, and growth prospects. Based on insights shared by a seasoned industry practitioner, this article systematically breaks down the three core roles in the LLM space to help you make smarter career decisions.
Overview of Three Core LLM Roles
After comprehensive research across major recruitment platforms, current LLM-related development positions can be categorized into three types:
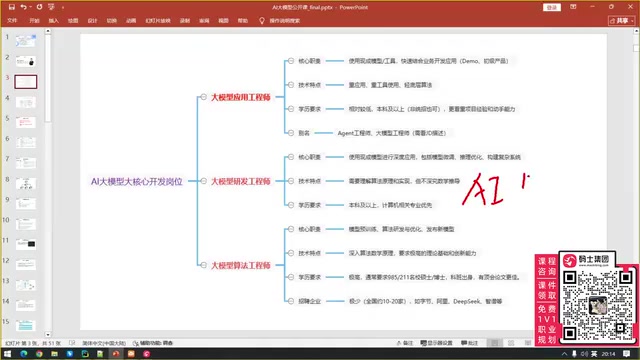
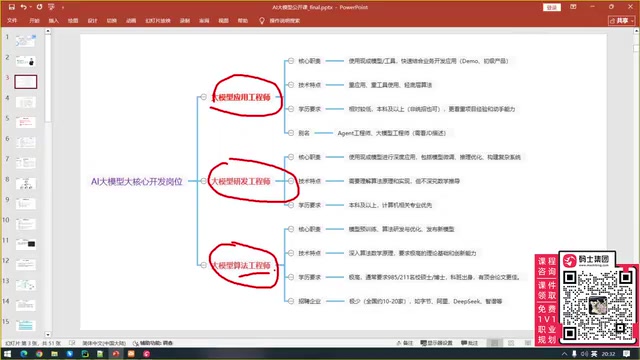
- LLM Application Engineer: Lowest barrier to entry, primarily responsible for agent development, RAG construction, and workflow building
- LLM Development Engineer: Medium barrier, encompasses all application engineer capabilities plus model fine-tuning and inference optimization
- LLM Algorithm Engineer: Highest barrier, minimum requirement of a Master's degree from a top university plus publications in top-tier journals
It's worth noting that job titles on recruitment platforms are often inconsistent. Some positions labeled "LLM Engineer" are actually application engineer roles, while some listed as "LLM Development Engineer" are actually algorithm engineer positions. Focus on the job responsibilities and technical requirements, not the title.
Detailed Tech Stack for Each Role
LLM Application Engineer
This is the most accessible entry point, with a minimum education requirement of a bachelor's degree. Core tech stack includes:
- Low-code platform tools: Dify, Coze, Cosor, RGFlow, N8N, etc.
- Development frameworks: LangGraph, Streamlit, etc.
- Core competency: No need to learn AI algorithms—the focus is on using various LLMs to build agents and RAG systems
The value of low-code platforms in practice lies in rapid validation—when leadership or clients demand to see a working agent within three days, quickly building a prototype through drag-and-drop is an essential skill. However, these tools suffer from slow response times, insufficient concurrency, and poor data security, making them unsuitable for production environments.
RAG Technical Background: RAG (Retrieval-Augmented Generation) is a technical architecture that combines external knowledge bases with large language models. The core idea is: before the model generates an answer, it first retrieves relevant document fragments from an external vector database, then injects these fragments as context into the prompt, enabling the model to respond based on the most current and accurate information. RAG effectively mitigates two major pain points of LLMs—"knowledge cutoff dates" and "hallucinations"—and is currently one of the most mainstream technical approaches for enterprise AI deployment. Vectorized data is typically stored in vector databases like Milvus, Weaviate, or Chroma, supporting efficient Approximate Nearest Neighbor (ANN) retrieval and forming the underlying infrastructure for agent knowledge bases.
LLM Development Engineer
This role fully encompasses the application engineer's skill requirements, while additionally requiring:
- Machine learning and deep learning algorithms (not extremely deep, but must be mastered)
- PyTorch, TensorFlow, and similar frameworks
- HuggingFace ecosystem (various model libraries, inference frameworks)
- Model fine-tuning techniques (LoRA, QLoRA, and other fine-tuning algorithms)
- Reinforcement learning, MoE pre-training, and other advanced knowledge
- Ability to integrate LLMs with traditional AI models (e.g., YOLO object detection)
LoRA and QLoRA Fine-tuning Background: LoRA (Low-Rank Adaptation) is a parameter-efficient fine-tuning method proposed by Microsoft Research in 2021. Its core idea is: freeze the pre-trained model's original weights and only inject low-rank matrices at specific layers for training, dramatically reducing the memory and compute resources needed for fine-tuning. QLoRA builds on LoRA by introducing 4-bit quantization, making it possible to fine-tune 7-billion-parameter models on a single consumer-grade GPU (such as an RTX 3090). These two techniques have significantly lowered the barrier for enterprise private deployment and model customization, and represent the core competitive advantage that distinguishes LLM development engineers from application engineers.
MoE Architecture Background: MoE (Mixture of Experts) is a sparsely-activated neural network architecture. Unlike traditional dense models that activate all parameters during every inference pass, MoE models consist of multiple "expert" sub-networks, with only a few experts dynamically selected by a Gating Network for each inference. This allows models to maintain extremely large total parameter counts while keeping per-inference computation relatively low. Top models like DeepSeek-V3 and Mixtral use MoE architecture to balance parameter scale with inference efficiency. Understanding MoE pre-training principles is essential advanced knowledge for LLM development engineers.
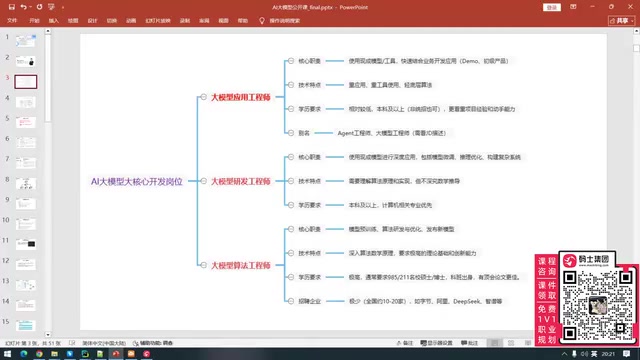
LLM Algorithm Engineer
The most demanding and highest-paying role. Requires deep mastery of mathematical derivations behind algorithms, and even understanding of underlying mathematical principles and C++/CUDA-level optimization implementations. Currently, approximately 20 companies nationwide are actively recruiting or headhunting for these positions, including Alibaba, DeepSeek, Moonshot AI, Zhipu AI, Huawei, Xiaohongshu, and others.
LLM Developers Need to Master at Least Six Model Types
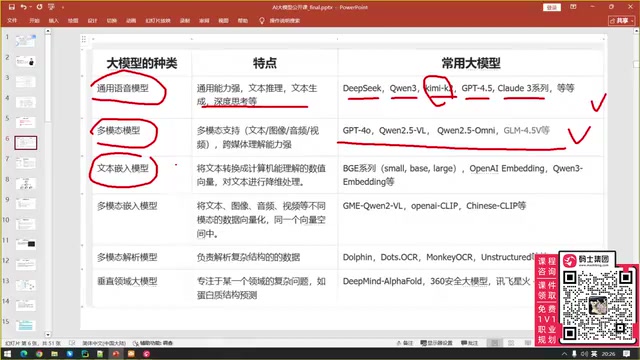
Many people think "knowing how to use DeepSeek" equals understanding LLMs—this is a serious misconception. As an LLM developer, you need to master at least six model types:
- General language models: DeepSeek, Qwen, K2, GPT-4.5, Claude 3, etc., for text understanding and logical reasoning
- Multimodal models: Processing images, audio, video, and other data types
- Text embedding models: BGE, OpenAI Embedding, Qwen Embedding, etc., for dimensionality reduction of text
- Multimodal embedding models: Vectorizing images, audio, and video (offered by Qwen, OpenAI, Zhipu, etc.)
- Multimodal parsing models: Docling, Dotter OCR (ByteDance), MinerU OCR (Xiaohongshu), etc., specialized in parsing complex unstructured data
- Vertical domain LLMs: Specialized models for specific industries
Text Embedding Models and Vector Database Background: Text embedding models convert natural language text into numerical representations in high-dimensional vector space, where semantically similar texts are positioned closer together. This process is essentially "semantic encoding" and serves as the foundational infrastructure for RAG systems, semantic search, and recommendation systems. BGE (BAAI General Embedding) is an open-source Chinese embedding model from the Beijing Academy of Artificial Intelligence, excelling in Chinese semantic understanding tasks and widely adopted in enterprise knowledge base retrieval scenarios in China. Notably, embedding models and generative models are two completely different technical directions—the former outputs vectors rather than text, a distinction beginners often confuse.
"Mastering" a model means not just knowing how to call its API, but also knowing how to deploy it for inference and fine-tune it.
Enterprise Inference Frameworks: Why Ollama Isn't Enough
Many people have used Ollama to run models locally, but Ollama doesn't support distributed deployment and cannot meet enterprise-level concurrency demands. True enterprise-grade inference frameworks include:
- vLLM
- SGLang
- HuggingFace Transformers library family
- Other inference engines supporting distributed computing
Ollama is essentially a tool that bundles an inference framework—it handles model inference while also providing web services and API endpoints. But when 300 people in a company need simultaneous access, Ollama's lack of distributed support makes it completely inadequate.
vLLM and SGLang Inference Framework Background: vLLM is a high-throughput LLM inference engine developed by UC Berkeley. Its core innovation is PagedAttention technology—borrowing the paged memory management concept from operating systems to dynamically allocate KV Cache (key-value cache), significantly improving GPU memory utilization and concurrent throughput. Compared to native HuggingFace inference, it can deliver several to tens of times better serving throughput. SGLang (Structured Generation Language), developed by a Stanford team, focuses on efficient execution of structured outputs and complex reasoning chains, performing particularly well in scenarios requiring JSON-formatted output or multi-turn conversations. Both support multi-GPU tensor parallelism and multi-node distributed deployment, making them the mainstream choices for enterprise LLM inference services and essential tools that LLM development engineers must master.
Career Prospects and Lifecycle Predictions
LLM Algorithm Engineer: 10-20 Year Golden Period
Current AI LLMs update approximately every three months (Qwen 2.5→3, DeepSeek V3→V3.1, GPT 4→4.5→5.0, Claude 3→3.5→3.7), with the world's top talent and capital flooding into this direction. This is the next definitive direction for human society's development, with no age limitations.
LLM Development Engineer: 3-5 Years of Strong Demand
The LLM "hallucination" problem won't be completely solved in the short term. Improving model accuracy from 70%-80% to above 95% requires development engineers to continuously work on inference optimization and fine-tuning. This role will maintain strong demand for the next 3-5 years.
LLM Hallucination Background: LLM "hallucination" refers to models generating content that appears reasonable but is actually inaccurate or entirely fabricated. The fundamental cause is that language models are trained to predict the probability distribution of the next token, not to guarantee factual accuracy—models are essentially performing "statistically plausible continuation" rather than "fact-checking." Hallucination is particularly critical in high-precision domains like healthcare, law, and finance. Current mitigation approaches include: RAG (grounding with external knowledge), RLHF (Reinforcement Learning from Human Feedback), Chain-of-Thought prompting, domain-specific fine-tuning, and Self-Consistency verification during inference. However, the industry generally agrees that under the current Transformer architecture, hallucination cannot be fundamentally eliminated—this is precisely the core technical reason why development engineer positions will maintain strong long-term demand.
LLM Application Engineer: 1-2 Year Window
Due to the relatively low technical barrier, this space isn't expected to become oversaturated immediately, but may enter a highly competitive phase afterward—similar to the trajectory of Android/iOS development years ago.
Advice on Work Experience
Since LLM positions in China truly exploded only recently, LLM work experience on your resume should not exceed one year. Claiming two or three years of experience will actually raise red flags with interviewers—prior to recently, LLM inference costs in China were extremely high, and only a handful of large companies were working in this space. Interviewers will inevitably probe for specific company and project details.
Conclusion
Regardless of your current technical direction, LLMs have become an unavoidable technology trend. Even if you don't transition to a full-time LLM engineer role, mastering basic LLM application capabilities has already become a differentiator across all positions. The key is to clearly understand your positioning, choose a matching career direction, and develop a reasonable learning path—rather than being misled by fragmented information.
Key Takeaways
- LLM development roles are divided into three categories—Application Engineer, Development Engineer, and Algorithm Engineer—with progressively higher barriers and compensation
- A qualified LLM developer needs to master at least six model types, not just API calls
- Enterprise inference frameworks (vLLM, SGLang, etc.) are fundamentally different from personal tools (Ollama)—distributed capabilities and core technologies like PagedAttention are critical
- Lifecycle predictions for the three roles: Algorithm Engineer 10-20 years, Development Engineer 3-5 years, Application Engineer 1-2 year window
- LLM hallucination stems from the statistical prediction nature of the Transformer architecture and cannot be completely solved in the short term—this is precisely the fundamental reason for sustained demand for development engineer positions
Related articles
 Industry Insights
Industry InsightsAI Product Development in Practice: Model Selection, Building Moats, and Paths to Commercialization
Practical strategies for AI product development: why not to train models from scratch, when to use APIs vs. fine-tuning, building product moats, and the full path from evaluation systems to commercialization.
 Industry Insights
Industry InsightsNo Product Fits Your Needs? Building It Yourself Is the Best Starting Point for Indie Developers
Can't find a product that fits? Building from personal pain points is the best entry for indie developers. Niche needs + AI tools = rapid product creation.
 Industry Insights
Industry InsightsOpenAI Codex Tutorials Mass-Copied on Bilibili, Highlighting AI Content Farm Problem
At least 9 Bilibili accounts mass-published identical OpenAI Codex tutorial videos, exposing content farm operations in the AI tools space.