Enterprise AI Agent Architecture in Practice: Sandbox Isolation and Skill Management Explained
A practical guide to enterprise AI agent architecture with sandbox isolation and Skill management.
This article analyzes an enterprise AI agent architecture built on the HARIS framework and DeepAO, covering task decomposition for complex problems, MCP tool integration via community ecosystems, Docker-based sandbox isolation for secure execution, a two-tier Skill persistence strategy that separates storage from execution, and user-level memory systems using MongoDB for personalized experiences.
Introduction
As AI agents move from concept to production, designing a stable and scalable enterprise-grade architecture is a core challenge every developer must face. Recently, a developer on Bilibili live-streamed a complete demonstration of an agent project built on the HARIS architecture and DeepAO framework, covering key design elements such as sandbox management, Skill persistence, and user memory systems. This article distills and analyzes the core architectural ideas from that demonstration.
Overall Project Architecture: Multi-System Collaborative Agent Engineering
This agent project is far from a simple chatbot — it's a complex engineering effort that requires coordination across multiple systems. The overall architecture involves three core components:
- Java ERP Backend: Provides business data and API support
- Docker Containers on a Linux Server: Serve as sandboxed execution environments
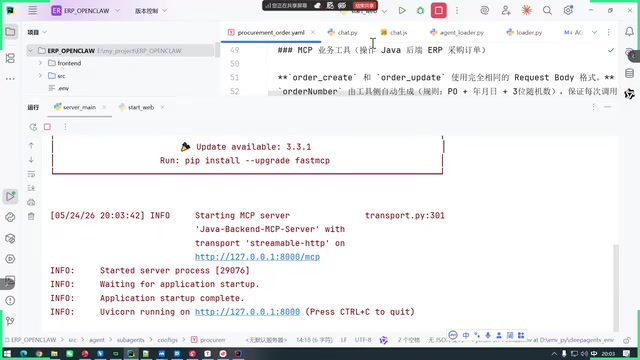
- Main Agent Project: Built with the DeepAO framework + HARIS architecture
The developer specifically noted that compared to previous agent solutions, the HARIS architecture showed clear advantages when handling complex problems. Its core approach is to decompose complex problems into task lists and then execute them step by step — a philosophy fully aligned with the mainstream multi-step reasoning paradigm.
This approach is a classic application of the "divide and conquer" strategy in AI, sharing deep theoretical connections with OpenAI's Chain-of-Thought reasoning and the increasingly popular ReAct (Reasoning + Acting) paradigm. Traditional end-to-end LLM calls often suffer from "hallucinations" or logical leaps when facing multi-step, multi-constraint complex tasks. Task decomposition architectures break large problems into verifiable small steps, with intermediate result validation at each stage, significantly improving overall accuracy and controllability. This is also the design paradigm widely adopted by well-known agent projects like AutoGPT and BabyAGI.
According to the developer's feedback, this architecture delivered three notable improvements: higher accuracy, stronger controllability, and better generalization.
MCP Tool Integration: Extending Agent Capabilities Through Community Ecosystem
One noteworthy design in the project is the integration of MCP (Model Context Protocol) tools. MCP is a standardized protocol open-sourced by Anthropic in late 2024, designed to establish a unified communication interface between large language models and external tools or data sources. Before MCP, every AI application needed custom integration code to connect with external tools, leading to significant duplication of effort and ecosystem fragmentation. MCP defines a standardized Server-Client architecture so that tool providers only need to implement an MCP Server once, and any agent supporting the MCP protocol can call it directly.
Rather than deploying all tools locally, the developer connected directly to the ModelScope community's MCP marketplace, leveraging community-provided MCP Servers to accomplish specific tasks. The ModelScope MCP marketplace is built on this protocol, aggregating various types of MCP Servers for data analysis, code execution, search engines, file processing, and more. Developers can quickly integrate the capabilities they need, much like installing plugins.
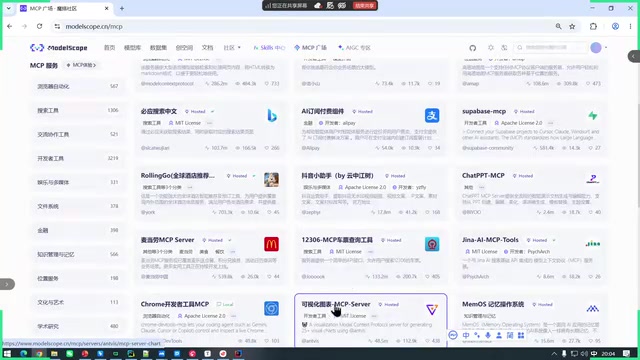
In the demonstration, he used an MCP tool specifically designed for data analysis and report image generation. The benefits of this approach are clear:
- Reduced local deployment costs: No need to build the entire toolchain locally, saving significant development time
- Leveraging community ecosystem: The MCP marketplace offers a rich selection of ready-to-use tools
- Separation of concerns: Each MCP Server handles only a specific function (e.g., chart generation), resulting in a cleaner architecture
However, this also introduces a challenge — when an MCP connection fails, the entire project throws errors and cannot start. This reminds us that in production environments, external tool dependencies require proper degradation and retry mechanisms. In microservices architecture and cloud-native practices, the industry has developed mature fault-tolerance patterns to address such challenges: the Circuit Breaker pattern automatically cuts off calls after detecting consecutive failures in an external service, preventing cascading failures; Retry with Backoff uses exponential backoff strategies to automatically recover after transient faults; Graceful Degradation provides limited but functional alternatives when external services are unavailable. For agent projects, when a particular MCP tool is unavailable, the system should be able to inform users that the feature is temporarily limited rather than crashing entirely. Netflix's Hystrix and Alibaba's Sentinel are classic open-source implementations in this space.
Sandbox Architecture Design: Separation of Execution Environment and Storage
The most valuable part of the entire demonstration was the design philosophy behind the sandbox architecture. This is also the key differentiator between enterprise-grade agents and demo-level projects.
Why Do Agents Need Sandboxes?
The project uses a Docker container management tool called OpenSandbox to create independent sandbox environments for each user on a remote Linux server. The core purpose of the sandbox is to operate on files and execute Skills.
Docker is an OS-level virtualization technology that leverages Linux kernel mechanisms — Namespaces and Cgroups — to create independent process spaces, network stacks, file systems, and resource quotas for each container. Using Docker as a sandbox in agent scenarios provides three core benefits: First, process isolation — code executed within the sandbox cannot access processes on the host machine or other containers. Second, file system isolation — each container has its own independent file system layer, preventing data cross-contamination between users. Third, resource limits — CPU and memory caps can be set for each sandbox, preventing a single user's abnormal operations from exhausting server resources. Compared to traditional virtual machines, Docker containers start in seconds with lower resource overhead, making them ideal for dynamically creating and destroying execution environments per user.
Here, "Skills" can be understood as the agent's specific capability modules — such as data querying, file processing, code execution, etc. Running these Skills in a remote sandbox rather than locally offers one crucial benefit: security isolation. User code execution doesn't affect the main system, and even if an exception occurs, it only impacts a single sandbox.
Why Must Skill Execution and Storage Be Separated?
This is the most elegant part of the entire architecture design. The developer explicitly stated: executing Skills and storing Skills must be kept separate.
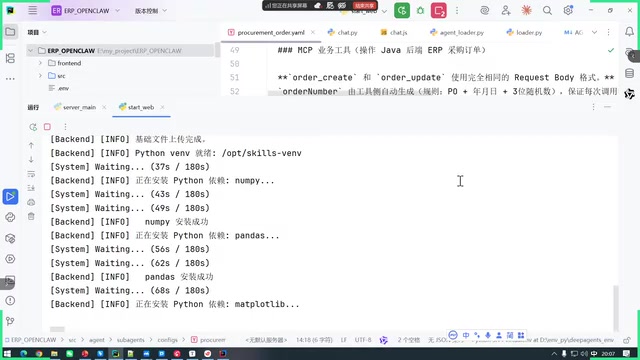
The reason lies in the real-world challenges of enterprise environments:
- Sandbox resources may be reclaimed: Cloud server containers can be destroyed due to insufficient resources
- Sandbox destruction = Skill loss: If Skills only exist within the sandbox, losing the sandbox means losing the Skills
- Recovery mechanisms are essential: There must be a way to copy Skills back from persistent storage to a new sandbox
Therefore, the project adopts a two-tier storage strategy:
- Persistent Storage Layer: Skill definitions and code are stored in independent persistent storage (unaffected by sandbox lifecycle)
- Runtime Execution Layer: The sandbox loads runtime copies of Skills
- Synchronization Mechanism: When a sandbox is rebuilt, Skills are automatically restored from persistent storage
This design philosophy closely mirrors the stateless Pod design principle in Kubernetes — execution environments are ephemeral, but data and configurations are persistent. In Kubernetes architecture, Pods are designed as stateless, disposable minimum scheduling units that can be destroyed and rebuilt at any time, while persistent data is safeguarded through PersistentVolumes, external databases, or object storage. The fundamental premise of this design is that in distributed environments, any running instance may be terminated due to hardware failures, resource scheduling, rolling updates, or other reasons, so system resilience cannot depend on the survival of any specific instance. Storing Skill definitions and code in an independent persistence layer (such as databases or object storage) while sandboxes hold only runtime copies ensures that even if all sandboxes are destroyed simultaneously, the system can fully recover within minutes.
User-Level Isolation and Memory System: Building a Personalized AI Assistant
Another architectural highlight is the user-level isolation design. The project assigns each user:
- An independent sandbox environment: Execution environments are completely isolated between users
- Independent long-term memory files: Each user has their own preference memory
Taking user preference files as an example, the system stores each user's preference data as files in a MongoDB database, with the naming convention {username}_preference.md. When a new user logs in for the first time, the system automatically creates a default preference file, which is gradually updated through subsequent interactions.
Agent memory systems are typically divided into three levels: working memory (current conversation context, i.e., dialogue history in the prompt), short-term memory (summaries and key information extracted from recent interactions), and long-term memory (user preferences, historical knowledge, and behavioral patterns). The project's approach of using MongoDB to store user preference files falls under long-term memory implementation. As a document-oriented NoSQL database, MongoDB's flexible schema design is well-suited for storing user preference data with variable structures — different users may have entirely different preference dimensions, and the fixed table structures of traditional relational databases would be cumbersome in this scenario. More cutting-edge memory systems also incorporate vector databases (such as Milvus or Pinecone) for semantic retrieval of historical interactions, enabling agents to not only remember what users said but also understand their deeper intent patterns.
This design gives the agent the ability to "remember users," which is a critical step in evolving from a tool-type AI to an assistant-type AI. In enterprise scenarios, different users may have completely different work habits and data permissions, and user-level isolation ensures both personalized experiences and data security.
Architectural Insights and Summary
From this project's architecture design, we can distill several principles with universal significance for enterprise AI agent development:
- Task decomposition over end-to-end: The HARIS architecture handles complex problems through task lists, which is more reliable than expecting the model to solve everything in one shot
- Leverage community ecosystems: Tool marketplaces like the MCP marketplace can dramatically reduce development costs, but fault tolerance is essential
- Separate execution from storage: This is the key to ensuring system resilience — sandboxes can be rebuilt at any time without losing Skills
- User-level isolation: In multi-user scenarios, independent sandboxes + independent memory are baseline requirements
- Memory persistence: Persistent storage of user preferences and interaction history is the foundation for agents evolving from "stateless tools" to "memory-equipped assistants"
Although the demonstration encountered some waiting times and errors due to the complexity of starting multiple systems, this precisely reflects the reality of enterprise projects — the value of architecture design is demonstrated through managing exactly this kind of complexity.
Related articles
OpenAI Codex Data Analytics Plugin in Practice: The Complete Workflow from Data Collection to Report Delivery
Deep dive into OpenAI Codex's Data Analytics Plugin: cross-system data integration, smart chart generation, data provenance, and Google Slides export reshaping analytics workflows.
OpenAI Codex Creative Production Plugin: How AI Is Revolutionizing Marketing Asset Creation
Deep dive into OpenAI Codex Creative Production Plugin: AI product image generation, Remix style adjustment, one-click brochure creation, and Canva integration for editable output.

Preparing for an Antarctic Cycling Expedition with ChatGPT: How AI Powers Extreme Adventure
An explorer uses ChatGPT to prepare for an unprecedented solo Antarctic cycling expedition. Learn how AI serves as gear optimizer, training coach, and emergency lifeline in extreme adventure.