Fixing Tool Confusion: A Practical Method to Make DeepSeek v4 Outperform Opus
Deterministic Repair Logic fixes DeepSeek v4's tool call failures, making it outperform Claude Opus 4.7.
Ahmad Awais discovered that DeepSeek v4 Pro suffers from 'Tool Confusion'—repeating failed tool calls an average of 56 times without self-correcting. His deterministic Repair Logic intercepts known error patterns (malformed JSON, null parameters, Markdown in paths) and fixes them without consuming extra tokens. By the third call, models self-correct. The approach extends to fixing AI design slop and includes a Taste system that auto-learns developer preferences using KL divergence filtering.
Introduction: An Overlooked Problem with Open-Source Models
In the AI coding tools space, the gap between open-source and commercial models has been a hot topic among developers. Is DeepSeek v4 Pro actually good? Why do some people say it rivals Claude Opus while others say it's unusably slow?
Recently, Ahmad Awais, founder of Command Code, shared a key discovery on the Latent Space podcast—what he calls "Tool Confusion"—and how deterministic repair logic can make DeepSeek v4 outperform Opus 4.7. This finding applies not only to DeepSeek but can be extended to other open-source models like Kimi.
What Is Tool Confusion?
The Nature of the Problem
When you use a coding Agent, the model needs to make tool calls to perform various operations—listing file directories, reading file contents, executing shell commands, etc. In modern AI coding Agent architectures, these tool calls follow strict structured protocols: the model issues a call request in JSON format, the Agent framework validates the request's legitimacy through predefined parameter schemas, then executes the corresponding operation and returns results. This validation layer typically uses Zod—the most popular runtime type validation library in the TypeScript ecosystem—to ensure parameter formats are correct.
While processing billions of tokens of inference data, Ahmad discovered that DeepSeek v4 Pro has a kind of "alpha male energy"—it firmly believes its tool calls are correct, and even when receiving Zod schema validation errors, it won't correct its behavior.
Specifically: when tool call parameter schemas don't match (such as sending empty objects or null in optional parameter positions), Zod validation returns an error. But DeepSeek won't correct itself based on the error message—instead, it repeats the same erroneous call an average of 56 times. This means the model wastes enormous amounts of tokens and time on the same error, causing user experience to plummet.

Why Are Open-Source Models Prone to Tool Confusion?
Ahmad proposed an interesting hypothesis: these open-source models learn from data generated by stronger models during training, and the training signal tells them "what you're told is correct." This is closely related to the Knowledge Distillation training paradigm widely adopted by open-source models—many use high-quality outputs generated by GPT-4, Claude, and other commercial models as training data. During this training process, the implicit rule the model learns is "output from authoritative sources is always correct." When this pattern transfers to the inference stage, the model exhibits overconfidence—"what I generate should also be correct."
This leads to a behavioral pattern of "what I tell you is also correct, don't try to correct me." While this is an intuition-based judgment, the data supports it—the model's "stubbornness" when facing error feedback far exceeds expectations.
The Deterministic Fix: Repair Logic
Core Approach
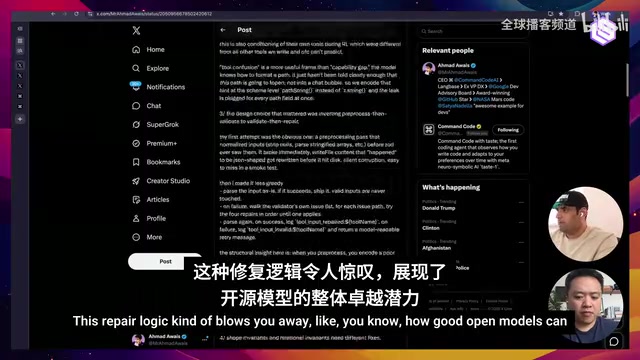
Ahmad's solution isn't complex, but the results are remarkable. The core idea: rather than throwing error messages back to the model and hoping it self-corrects (which consumes additional inference tokens and often fails), fix the problem first, return the correct result, and attach a "repair hint" telling the model what it should do.
"Deterministic" is the keyword here—the repair logic doesn't rely on the model's probabilistic reasoning but directly corrects known error patterns through hard-coded rules. This is similar to a compiler's error recovery mechanism: when a parser encounters a syntax error, it doesn't stop to "think" about what to do—it skips or corrects the error according to predefined rules and continues processing subsequent content.
He used a vivid analogy: it's like teaching someone to drive—when the student is about to crash, you don't lecture them first; you help them avoid the danger, then explain what they should have done.
Actual Results
The repair logic started with 3,200 lines and 4 repair rules, and has now grown to over 16,000 different repair variants, covering hundreds of billions of tokens of inference data. Key findings include:
- On the first failed tool call, repair and return the result + hint
- By the third tool call, the model can self-correct (indicating the model has in-context learning capability—it just needs the right guidance signal)
- After reducing tool errors, the model becomes more creative and can explore for longer periods (because it's no longer wasting its reasoning budget on repeated errors)
Specific Repair Examples
Some common deterministic repair scenarios:
- JSON String Repair: When the model sends data as a JSON string type, deterministically repair it to an array. For example, the model outputs
"[1,2,3]"(string), and the repair layer automatically parses it to[1,2,3](array) - File Read Offset: When the model doesn't specify a read position, default to returning the first 100 lines of the file. This avoids call failures due to missing required parameters
- Markdown Links in Paths: The model inexplicably inserts Markdown link format in file paths (e.g.,
[src/index.ts](src/index.ts)), which is directly cleaned to a plain path string - Empty Object/Null Parameters: Non-compliant values in optional parameter positions are automatically corrected, e.g., replacing
{}ornullwith schema-defined default values
All these repairs are deterministic, require no additional token consumption, and execute in near-zero time.
From Tool Repair to AI Design Repair
Solving the AI Design "Purple Gradient" Problem
Ahmad's team discovered the same repair logic can be applied to AI-generated designs. So-called "design slop"—the cookie-cutter indigo purple gradients, three-card layouts—is essentially a finite set of deterministically fixable patterns. The root cause lies in distribution bias in training data: a large number of SaaS websites and UI templates use similar design languages, so models naturally gravitate toward these high-frequency patterns when generating designs.
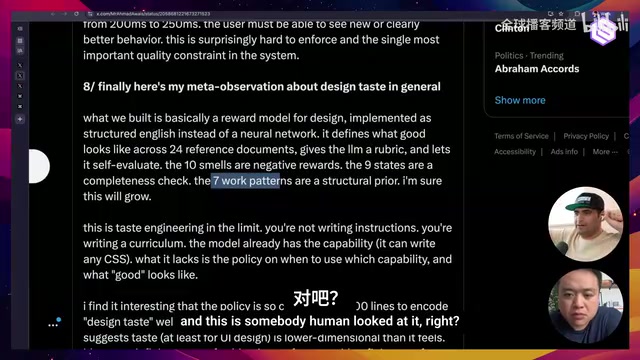
They collaborated with multiple professional designers to compile 24 reference documents, 10 "Design Smells" (similar to the Code Smells concept in programming), and 7 design patterns. Designers can distinguish AI-generated designs from human-reviewed ones in just 1.5 seconds, and these differences are all fixable.
Key Design Repair Rules
- Intent First: Have the model think about intent before designing (Dashboard? Showcase page? Marketing landing page?). Different intents correspond to completely different layout logic and visual hierarchy
- Surface Type Framework: Provide 7 common design patterns for the model to choose from, transforming an open-ended design problem into a constrained selection problem
- Color Space: Force the use of OKLCH instead of HSL. OKLCH is a perceptually uniform color space proposed by Björn Ottosson. Unlike HSL, equal numerical changes in OKLCH correspond to consistent visual perception differences—meaning the model produces predictable visual effects when adjusting parameters. In HSL, blue and yellow at the same lightness value appear completely different in brightness, while OKLCH eliminates this inconsistency, making AI-generated color schemes more harmonious
- Compositional Thinking: Give the model a design thinking framework rather than letting it freestyle. Similar to the Design System philosophy, improving consistency through constraints
The Taste System: Automatically Learning Developer Preferences
An Automated Solution Beyond Rules Files
Another core differentiator of Command Code is the "Taste" system—a Meta Neuro-Symbolic Model that automatically learns preferences from developers' daily operations and encodes them as reusable skill files.
Neuro-Symbolic AI is a research direction that combines deep learning's pattern recognition capabilities with symbolic reasoning's logical rigor. The "Meta" in the Taste system indicates it's a model about model behavior—it doesn't directly generate code but learns and encodes meta-knowledge about "how to make models generate better code." The advantage of this architecture: preferences are stored in human-readable symbolic form while using neural networks to learn when and how to apply these preferences.
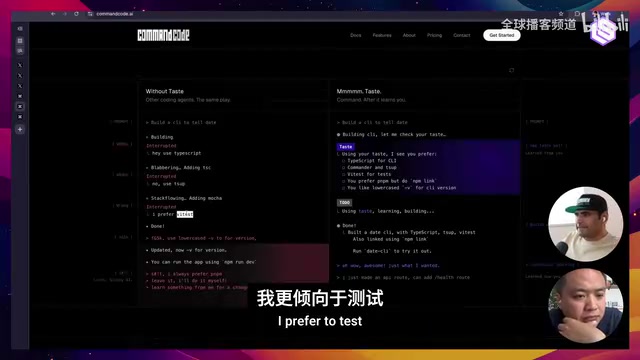
Unlike manually written rules files, Taste has several key characteristics:
- Automatic Learning: Learns from your edits, acceptances, and rejections. Every time you modify AI-generated code, the system analyzes modification patterns and extracts preference signals
- KL Divergence Filtering: If the LLM already knows something, it won't be written to the taste file (avoiding useless context). KL Divergence (Kullback-Leibler Divergence) is an information theory metric measuring the difference between two probability distributions. The system compares the model's output distribution with and without a given preference to judge: if the difference is small (low KL divergence), the model already tends to do this, and writing it to the taste file only wastes precious context window; if the difference is significant, the preference can effectively change model behavior
- Never Outdated: Automatically updates as the project evolves, automatically resolving preference conflicts when detected
- Transparent and Auditable: Stored as Markdown files in Git repositories, enabling version control and team sharing just like code
Practical Usage Patterns
An interesting community practice: use a high-quality model (like Opus or GPT 5.5) to build the first project, letting the taste file learn high-standard code patterns, then use a cheaper model based on that taste file for subsequent projects. This "high-quality bootstrap + low-cost scaling" pattern works well in practice—it essentially distills an expensive model's "taste" into a lightweight symbolic representation, then uses that representation to guide cheaper model behavior.
Implications for Developers
This work reveals an important truth: much of what we perceive as "insufficient model capability" is actually "contract mismatch between the coding Agent framework and the model." When you run DeepSeek through Claude Code's framework, massive tool call failures make the model appear slow and dumb—but the problem isn't the model's reasoning ability; it's that the framework hasn't adapted to the model's tool call behavioral characteristics.
This discovery has far-reaching implications for the entire AI coding tools ecosystem. It means the actual usability of open-source models may be severely underestimated. A well-designed middleware layer—one that understands different models' behavioral patterns and performs deterministic adaptation—may be more cost-effective than simply pursuing larger, more powerful models.
Ahmad emphasizes that these repair logic patterns are completely open, and any coding Agent framework can implement them. Command Code also plans to open-source the entire codebase soon. For developers using open-source models, understanding and implementing this deterministic repair logic may be the most direct way to improve the AI coding experience.
Key Takeaways
Related articles

AI Now Writes Over 80% of Code: What Doubling Capability Every 4 Months Really Means
Anthropic reveals Claude now writes over 80% of its code, with AI capability doubling every four months. Three real cases show the speed of AI's rise and the shrinking window for human adaptation.

Replit President: Writing Code Will Become Insignificant — Ideas Are Everything
Replit's president shares insights on AI programming's future: how a 40M-user platform uses Claude to eliminate coding barriers, making natural language the new programming language.

Stripe Data Reveals an AI Startup Explosion: A New Business Paradigm Where New Company Creation Has Doubled
Stripe data shows new business creation nearly doubled YoY, surpassing pandemic peaks. A deep analysis of how AI is transforming startup speed, vertical SaaS, and global entrepreneurship.