From GPT-1 to ChatGPT: How Ilya's Bet Ignited the AI Revolution
From GPT-1 to ChatGPT: how OpenAI's bet on scaling ignited the AI revolution.
This article traces OpenAI's journey from releasing GPT-1 — mocked as "garbage" in 2018 — to ChatGPT taking the world by storm in 2022. The core driving force was Ilya Sutskever's belief that "scale is intelligence." The team leveraged Google's Transformer architecture and validated through Scaling Laws that increasing model size continuously improves performance. But the revolution has a dark side: Kenyan outsourced workers endured psychological trauma to complete AI alignment work.
Introduction: A Starting Point Mocked as "Garbage"
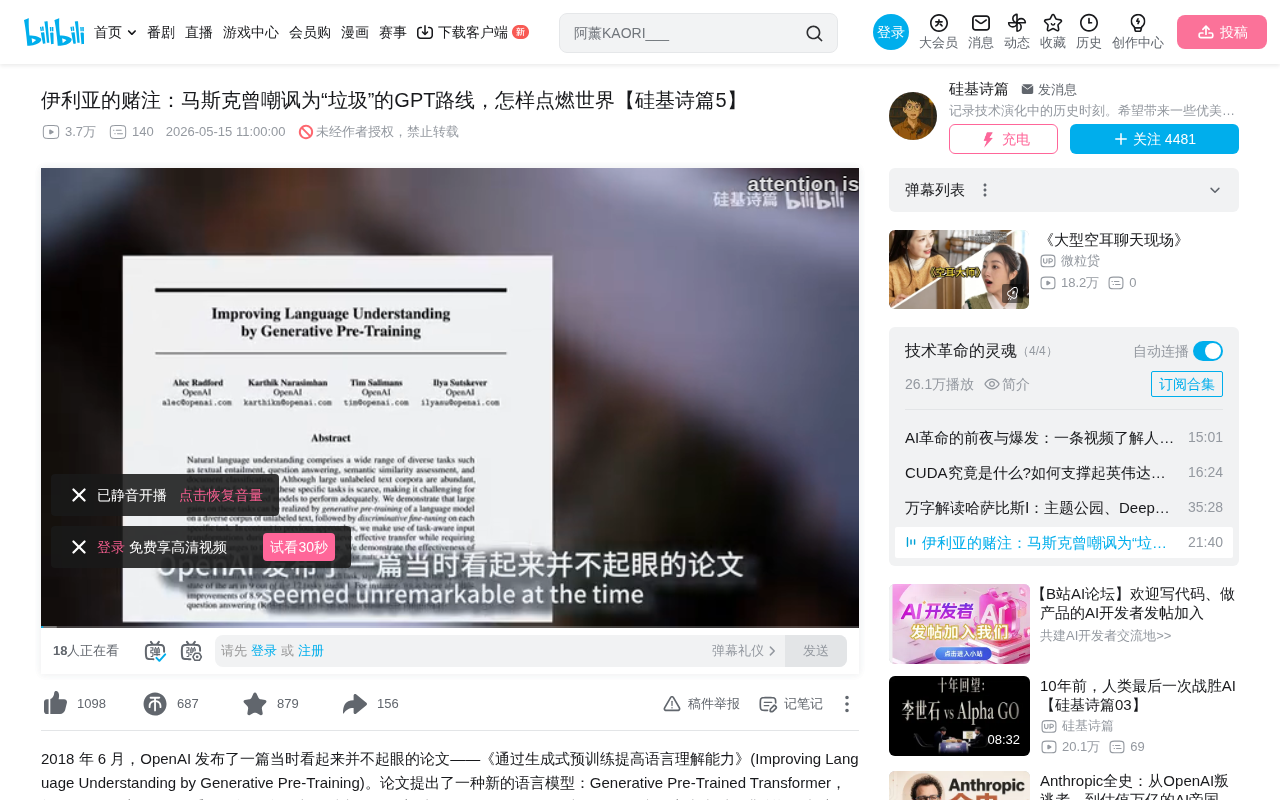
In June 2018, OpenAI published a paper that seemed unremarkable at the time — Improving Language Understanding by Generative Pre-Training. The paper proposed a new language model: Generative Pre-training Transformer, or GPT for short. This was the first version of the GPT series, later known as GPT-1.
GPT-1's performance was underwhelming — it often gave irrelevant answers and produced incoherent text. As OpenAI's biggest financial backer at the time, Elon Musk considered it "garbage" and sent a harshly worded email to OpenAI: "Without a significant overhaul in execution and resources, I believe OpenAI's chances of winning against DeepMind or Google are essentially zero."

But in the eyes of OpenAI's Chief Scientist Ilya Sutskever, this was merely the beginning. He decided to lead the team in doubling down on this approach. At the time, few could have imagined that this incoherent language model would eventually change the world forever.
The Birth of the Transformer and OpenAI's Opportunity
Google's Invention, Ignored by Google
In mid-2017, a Google research team published the landmark paper Attention is All You Need, introducing a completely new neural network architecture — the Transformer. Internally at Google, researchers had applied the Transformer to machine translation, text generation, and music composition, achieving surprisingly impressive results.
But Google's leadership seemingly failed to recognize the technology's potential value. At the time, Google's monopoly position in search had made the company increasingly bureaucratic and bloated, and they repeatedly thwarted the Transformer team's attempts to productize the technology. This gave OpenAI its opening.
Ilya's Prophetic Intuition
Ilya quickly recognized the Transformer's potential. Back at the University of Toronto, studying under his advisor Geoffrey Hinton, his doctoral thesis had focused on how to effectively train sequence models. Traditional recurrent neural networks struggled to learn long-range dependencies, and the Transformer solved precisely this problem.
He began evangelizing the Transformer around the office. According to an MIT researcher, the Transformer appeared to be just a niche architecture at the time. But Ilya held prophet-like prestige in the AI field — he was a primary author of AlexNet and Sequence to Sequence, and had contributed to AlphaGo research. One researcher said: "Ilya can see ten years into the future."
Radford's Pivotal Decision
Under Ilya's influence, researcher Alec Radford began testing the Transformer. He made a fateful decision: changing the task the Transformer needed to learn. At Google, the Transformer was primarily used for machine translation, but Radford had the model perform a different task — predicting the next word.
Behind this seemingly simple training objective lay a profound philosophical insight. Ilya had repeatedly expressed a view: "Intelligence is compression. Training a model to generate convincing content forces it to compress information about the world into its essential essence."
Scaling Law: From Intuition to Law
Ilya's Faith in Scale
Ilya held an unwavering belief in model scale. He once stated: "With a very large dataset and a very large neural network, success will follow. When neural networks become as large as the brain, understanding and intelligence may emerge."
Sometimes he would pace back and forth in the office, suddenly appear in a meeting room, and then repeat the same message like a prophet: Scale up, scale up, scale up.
GPT-2: The Beginning of a Qualitative Shift
Radford was given more compute to scale up GPT. Meanwhile, another researcher, Dario Amodei, saw his work gradually converge with this project. Together they scaled GPT-1 by more than 10x, building a language model with 1.5 billion parameters.
As the model grew larger, researchers noticed a phenomenon that astonished them: improvements in model performance seemed to follow a mathematical pattern. Training data size, compute investment, number of model parameters — the relationship between these variables and model performance could be described by a smooth curve.
The team led by Amodei named this curve the Scaling Law. This meant Ilya's intuition was very likely entirely correct: simply scaling up, in and of itself, could be the core method driving AI progress.
GPT-3: The Insane Experiment with Ten Thousand GPUs
An "Absurd" Proposal
As part of an investment agreement, Microsoft built OpenAI a supercomputer equipped with approximately 10,000 NVIDIA V100 GPUs. Amodei made a bold suggestion: use all 10,000 GPUs at once to train a new language model.
Many thought Amodei had lost his mind. Previously, training models on a few dozen GPUs was already considered "large-scale," and at top universities, a PhD student who could monopolize 10 GPUs was considered lucky. But Amodei was resolute, and OpenAI's leadership backed the plan.
Devouring the Internet
In the fall of 2019, Amodei assembled an internal team called NUST to develop GPT-3. The team began massively expanding data sources: Reddit links, English Wikipedia, the Common Crawl data warehouse, the complete GitHub code repository, plus various blogs, forums, books... The inexhaustible ocean of text on the internet — containing humanity's brilliance and wisdom, along with its darkest, most deranged violence, hatred, and pornography — was all force-fed into GPT's brain.
Shocking the Tech World
In June 2020, GPT-3 was released and made available to developers via API. It could generate essays, scripts, and code, demonstrating unprecedented flexibility. Even more surprising was a new phenomenon — few-shot learning: by providing just a few examples, without any fine-tuning, the model could understand new tasks and begin executing them.

GPT-3 sent ripples through the global tech community. Google researchers realized OpenAI was using Google's own invention to build a competitive advantage; Meta's Yann LeCun was skeptical of the large language model approach; in China, tech companies including Alibaba, Huawei, and Baidu still viewed large language models as merely "an interesting research direction."
The Cost of Alignment: The Dark Side of the AI Supply Chain
An Untamed Beast
A freshly trained large language model is more like an untamed beast. Having digested the internet's vast trove of dark data, the model would randomly generate shocking content — sexual abuse, terrorism, crime tutorials, murder incitement.
Dario Amodei had at one point blocked the release of the GPT-3 API, sparking endless arguments with the applications team. However, Sam Altman needed to demonstrate technical capability to Microsoft as soon as possible. By the end of 2020, Amodei and over a dozen employees left OpenAI, officially founding Anthropic in May 2021.
The Psychological Trauma of Kenyan Workers
OpenAI began investing heavily in alignment work, including developing automated content filtering systems and Reinforcement Learning from Human Feedback (RLHF). This work required human annotators to label and rank harmful text generated by the model, one entry at a time. The project was ultimately outsourced to Kenya.

According to TIME magazine, each Kenyan worker earned less than two dollars per hour and had to review large volumes of model outputs involving self-harm, incest, violence, and hatred daily. Research from the University of Washington showed that in this group, the PTSD rate was approximately 15.4%, depression symptoms were at 30.8%, and alcohol abuse reached 38.5%.
To produce a gentle, polite large language model, real human beings were forced to use their own eyes and psychological well-being to clean, line by line, the filthiest excretions of human civilization.
ChatGPT: An Accidental Explosion
A Hasty Launch
In the fall of 2022, OpenAI was advancing a project codenamed "Super Assistant." The team originally planned to wait until GPT-4's alignment was complete before launching a chat product, but because Anthropic might release a chatbot first, management decided to use the much weaker GPT-3.5 to create a chat version as a market placeholder. It wasn't until the night before launch that the product got its name — ChatGPT.
Internally at OpenAI, almost no one was optimistic about this release. The sales team was told it "wouldn't have any impact on sales," and the infrastructure team was told to provision servers for 100,000 users "even though that many probably won't be needed."
Everyone Was Wrong
At 11:38 AM on November 30, Altman posted a tweet on X consisting of just nine words and a link. Traffic surged in from around the globe, tearing through the entire system at a pace that defied common sense. An OpenAI engineer at a NeurIPS party told a colleague: "No good — all the GPUs are melting, everything is crashing."
Five days after launch, ChatGPT surpassed one million users; two months later it reached 100 million, becoming the fastest-growing product in history. Musk, who had mocked GPT-1 years earlier, tweeted: "Many people are stuck in a 'holy shit, this is insane' ChatGPT loop."
Overnight, ChatGPT elevated OpenAI to legendary status. Google sounded its highest-level red alert, Microsoft's Nadella smiled at the skyrocketing numbers, and across the Pacific, Chinese labs and startups stayed up all night. All compute, capital, and ambition pivoted in the same direction at the same moment.
Conclusion
From GPT-1 — mocked as "garbage" by Musk in 2018 — to ChatGPT sweeping the globe at the end of 2022, the success of this approach validated Ilya's core belief: scale is intelligence. The Scaling Law transformed from an intuition into a law, from a law into a faith, and ultimately ignited the most expensive, most brutal, and most audacious technology race in human history.
But behind this revolution lies an interweaving of vision and greed, idealism and compromise, technological breakthroughs and human costs. It reminds us that behind every seemingly glamorous AI product, countless invisible prices are being paid.
Related articles
 Industry Insights
Industry InsightsAI Product Development in Practice: Model Selection, Building Moats, and Paths to Commercialization
Practical strategies for AI product development: why not to train models from scratch, when to use APIs vs. fine-tuning, building product moats, and the full path from evaluation systems to commercialization.
 Industry Insights
Industry InsightsNo Product Fits Your Needs? Building It Yourself Is the Best Starting Point for Indie Developers
Can't find a product that fits? Building from personal pain points is the best entry for indie developers. Niche needs + AI tools = rapid product creation.
 Industry Insights
Industry InsightsOpenAI Codex Tutorials Mass-Copied on Bilibili, Highlighting AI Content Farm Problem
At least 9 Bilibili accounts mass-published identical OpenAI Codex tutorial videos, exposing content farm operations in the AI tools space.