Gemini 3.5 Flash Achieves a Massive Leap on the GDPval Benchmark

Gemini 3.5 Flash achieves a performance leap via post-training techniques, approaching frontier model levels.
Google's Gemini 3.5 Flash significantly outperforms the previous-generation Gemini 3.1 Pro on the comprehensive GDPval benchmark, signaling that lightweight Flash models are approaching frontier-level performance. This breakthrough is primarily driven by advances in post-training techniques such as RLHF, instruction tuning, and DPO, which dramatically improve model quality without increasing inference costs. The traditional boundary between Flash and Pro positioning is blurring, and the emergence of high-quality, low-cost models will lower barriers to large-scale AI deployment, making the cost-performance sweet spot the key competitive battleground.
Core Finding: Flash Models Are Approaching Frontier-Level Performance
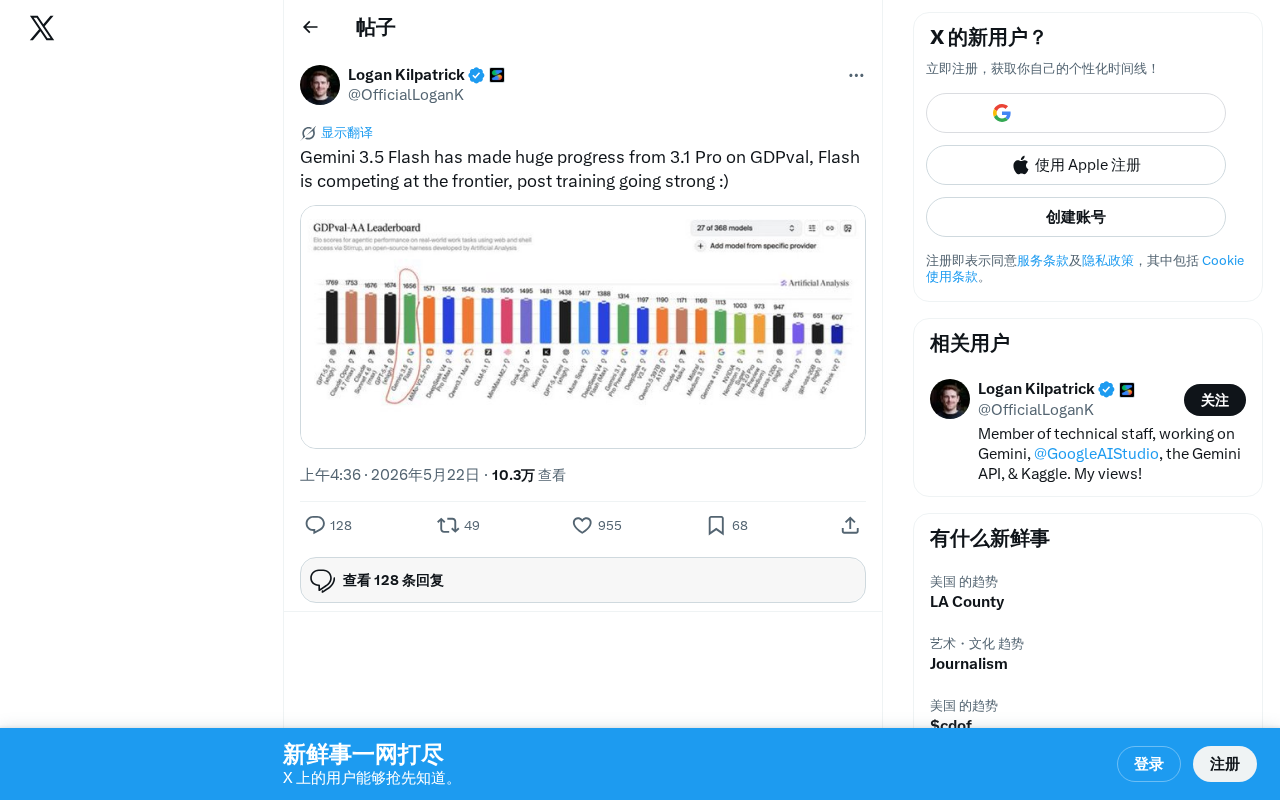
Google's newly released Gemini 3.5 Flash model has demonstrated remarkable progress on the GDPval benchmark, significantly outperforming the previous Gemini 3.1 Pro. This means a model positioned as lightweight and high-efficiency — a "Flash" model — is now challenging frontier-level large models in terms of performance.
GDPval (General Domain Performance Validation) is a comprehensive LLM evaluation benchmark designed to measure a model's practical performance across a variety of general tasks, including reasoning, knowledge Q&A, code generation, multilingual understanding, and more. Unlike single-dimension benchmarks, GDPval aims to provide a composite score that more closely reflects real-world usage scenarios, making it one of the industry's key reference metrics for measuring a model's "real-world capability." Gemini 3.5 Flash's breakthrough on this comprehensive benchmark means it hasn't just gamed a single task — it has achieved a holistic capability leap.
The Powerful Driving Force of Post-Training Techniques
Based on these evaluation results, Gemini 3.5 Flash's progress is largely attributable to continuous optimization of post-training techniques. Post-training refers to the process of further improving model performance through a series of refinement techniques after a large language model has completed pre-training (i.e., learning language patterns from massive text data). Core techniques include: RLHF (Reinforcement Learning from Human Feedback), where human evaluators rank model outputs to train a reward model, which then optimizes generation strategies via reinforcement learning; Instruction Tuning, which uses high-quality instruction-response pairs to help the model better follow user intent; and newer alignment techniques like DPO (Direct Preference Optimization).
The core value of post-training lies in its ability to significantly improve output quality and safety without increasing model parameter count — meaning without increasing inference costs. This allows Flash models to maintain their speed and cost advantages while achieving performance that approaches or even surpasses the previous generation of larger models through more refined post-training pipelines.
This trend indicates that Google's investment in the post-training phase is yielding significant returns. The Flash series already has inherent advantages in inference speed and cost efficiency, and now it's beginning to catch up with or even surpass the previous generation of Pro-level models in quality — a development with far-reaching implications for the entire AI application ecosystem.
Flash vs Pro: Rethinking Model Positioning
Traditionally, in Google's model product line, Pro represents stronger capability while Flash represents faster speed and lower cost. Flash series models typically employ smaller parameter scales, more efficient attention mechanisms (such as Multi-Query Attention MQA or Grouped-Query Attention GQA), and potentially model distillation techniques to achieve efficient inference. Distillation refers to compressing the knowledge of a large model (teacher model) into a smaller model (student model), enabling the smaller model to maintain high performance while dramatically reducing computational overhead. These techniques give Flash models far superior latency and throughput compared to Pro-level models, with per-token inference costs typically an order of magnitude lower.
However, Gemini 3.5 Flash's performance surpassing 3.1 Pro is blurring this boundary:
- Performance Crossover: Flash is no longer just a "good enough" cheap alternative — it's achieving frontier-level competitiveness on key benchmarks
- Efficiency Dividend: Users may obtain quality that previously required Pro-level models at significantly lower cost
- Accelerated Iteration: The magnitude of generational improvement (3.1 to 3.5) exceeds expectations, suggesting Google's model iteration cadence is accelerating
This blurring of positioning actually reflects a deeper industry trend: model capability "trickle-down" is happening far faster than expected. Today's flagship model capabilities may be replicated by efficiency-optimized lightweight models within six months.
Implications for Developers and the Industry
For AI application developers, this is a positive signal. High-quality but low-cost models mean more use cases can be economically served. When Flash-level models can deliver frontier-quality outputs, the barrier to deploying AI applications at scale will be further lowered.
The current frontier competition in the large model space is primarily concentrated among OpenAI (GPT-4o series), Google (Gemini series), Anthropic (Claude series), and Meta (Llama series). Competition has evolved from simply "whose flagship model is strongest" to a multi-dimensional contest: flagship performance, cost-effectiveness, inference speed, multimodal capabilities, long-context support, and more. The "cost-performance sweet spot" — delivering sufficiently good quality at the lowest cost — has become the critical battleground for commercialization, since the vast majority of real-world applications don't need the full capabilities of the most powerful models.
This also intensifies competition among large model providers — they must compete not only on the ceiling of their flagship models but also fiercely contest the optimal cost-performance "sweet spot." Through refinement of post-training techniques, Google is building an advantage in this arena. For developers, the decision framework for choosing models needs to be updated accordingly: it's no longer simply "use the most expensive model for the best results," but rather finding the optimal solution within an increasingly rich model matrix based on specific task quality requirements, latency sensitivity, and cost budgets.
Key Takeaways
- Gemini 3.5 Flash significantly outperforms Gemini 3.1 Pro on the GDPval benchmark, demonstrating a generational leap
- Flash-level models are approaching frontier performance, blurring the traditional distinction between Pro and Flash positioning
- Post-training techniques (including RLHF, instruction tuning, DPO, etc.) are the key drivers of this performance improvement, dramatically boosting quality without increasing inference costs
- The emergence of high-quality, low-cost models will lower the barrier to large-scale AI deployment, with the cost-performance "sweet spot" becoming the focal point of competition among providers
Related articles
 Tech Frontiers
Tech FrontiersGitHub Agent HQ Launch: AI Coding Tools Enter the Era of Platform Competition
GitHub Universe unveils Agent HQ platform for unified coding agent management, Copilot upgrades with multi-model support. OpenAI completes restructuring, Anthropic tests new model, NVIDIA open-sources AI models.
 Tech Frontiers
Tech FrontiersGoogle Gemini Antigravity Weekly Quota Tripled — AI Coding Without Limits
Google Gemini triples Antigravity weekly quotas following a prior daily quota boost. Analyzing the impact on developers and its strategic significance in AI coding.
 Tech Frontiers
Tech FrontiersGemini 3.5 Flash Surpasses Pro in Vision Capabilities, 6x Faster Inference
Roboflow benchmarks show Google Gemini 3.5 Flash outperforms the flagship Gemini 3.1 Pro on multiple vision tasks with ~6x faster inference, delivering a cost-effective multimodal AI solution.