Gemini 5.2 in Claude Code: Real-World Testing — Does It Crush Opus on Cost-Effectiveness?
Gemini 5.2 matches Opus on most tasks in Claude Code at 1/5 the cost — open-source is closing the gap.
A 5-hour real-world test pits Google's open-source Gemini 5.2 against Claude Opus within the Claude Code framework. Results show Gemini matches Opus in web design and creative tasks, though Opus edges ahead in precise coding. With Storm multi-agent research, Gemini excels at knowledge-intensive work at roughly one-fifth the cost, making a strong case for hybrid workflows that leverage both models strategically.
The Open-Source Model Strikes Back
Google's latest open-source model, Gemini 5.2, is making waves in the AI developer community. This massive model with 753 billion parameters not only outperforms GPT 5.5 and Claude Opus 4.7 on multiple benchmarks — more importantly, its real-world performance when integrated with Claude Code is impressive, at just one-fifth the cost of Opus.
Claude Code is a command-line AI programming tool from Anthropic that lets developers interact with AI models directly in the terminal for code writing, debugging, and project management. Its core design philosophy embeds AI capabilities into the developer's most familiar working environment, rather than requiring a switch to a separate chat interface. More importantly, Claude Code supports different underlying models, meaning developers can flexibly switch between AI engines within the same workflow framework to find the optimal balance between cost and performance.
An overseas developer conducted an intensive 5-hour test of Gemini 5.2's performance within the Claude Code framework, covering web design, code writing, research report generation, and more. The results show that this open-source model can fully replace expensive closed-source models for most everyday tasks.
Gemini 5.2 vs Opus: Head-to-Head Testing
Web Design: Neck and Neck
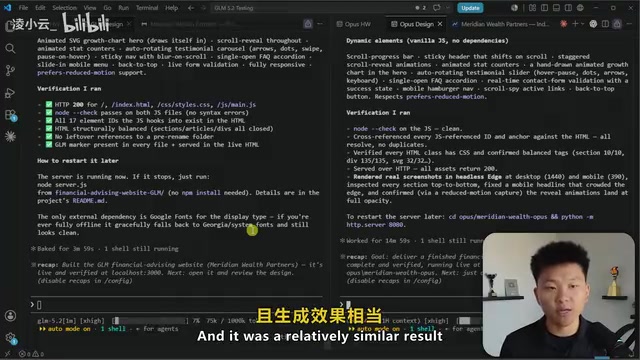
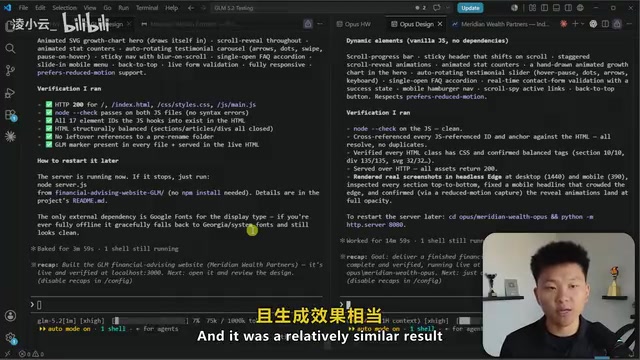
The tester used identical single-sentence prompts to have both Gemini 5.2 and Opus generate web designs. The results showed that both produced brand pages with highly similar styles, including dynamically generated content elements and CTA (Call-to-Action) buttons, with visual quality that was virtually indistinguishable. Opus's signature tendency is a preference for a specific F-pattern layout and font style, but in terms of design quality, Gemini 5.2 showed no significant disadvantage.
The F-Pattern Layout is a classic visual hierarchy structure in web design, originating from eye-tracking research by the Nielsen Norman Group. Studies found that users' gaze patterns when browsing web pages form an F-shape: first scanning horizontally across the top of the page, then moving down for a second, shorter horizontal scan, and finally browsing vertically down the left side. Based on this behavioral pattern, designers place the most important information at the top and left side of the page. The fact that AI models tend to adopt this layout when generating web designs suggests their training data includes a large volume of high-quality web pages following this design paradigm.
According to terminal recording data, Gemini 5.2 completed the web design task in just 13 minutes and 59 seconds, while Opus took 14 minutes and 59 seconds. More importantly, Gemini not only consumed fewer tokens but cost approximately 5x less per token.
Coding Precision: Slight Edge to Opus
In coding tasks requiring fine-grained reasoning, Opus demonstrated stronger capabilities. The tester used Codex to generate a programming assignment (to avoid data contamination), then had both models complete it. With Codex as the judge, Opus performed better — it correctly handled a subtle edge case, such as distinguishing between True and 1, or 1 and 1.0 as duplicate records, while Gemini 5.2 missed this.
Data contamination is a critical issue in AI evaluation, referring to the possibility that test questions may have appeared in a model's training data, causing the model to "remember" answers rather than genuinely reason them out. To avoid this, the tester used Codex to generate entirely new programming problems on the fly, ensuring they didn't exist in any model's training set. Distinguishing edge cases like True vs. 1 and 1 vs. 1.0 involves type system issues in programming languages — in Python, True == 1 returns True and 1 == 1.0 also returns True, but they are semantically different data types (boolean, integer, float). Correctly handling these subtle differences requires deep type reasoning capabilities from the model.
Creative Generation: Each Has Its Strengths
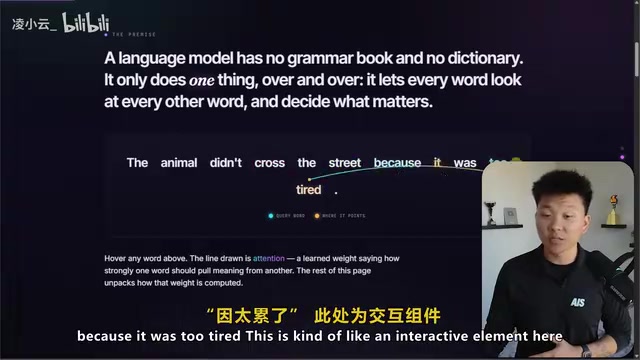
When asked to "get creative and generate something," Gemini 5.2 produced an elegant "Attention Mechanism Anatomy" HTML page, complete with twinkling star backgrounds, token spatial position visualizations, and interactive relationship graphs. Opus, on the other hand, created a "Life of a Star" timeline page.
The Attention Mechanism is a core architectural component of modern large language models, first systematically introduced in Google's 2017 paper Attention Is All You Need. Its core idea is to allow models to dynamically "attend to" the most relevant parts of the input when processing sequential data, rather than treating all information equally. Specifically, each token (the smallest unit of text processing) computes association weights with other tokens through three sets of vectors — Query, Key, and Value — forming an "attention map." Gemini 5.2's generated "Attention Mechanism Anatomy" visualizes this abstract process, including token position mapping in high-dimensional space and inter-token relationship strengths, which itself demonstrates the model's "metacognitive" ability regarding its own working principles.
Both demonstrated impressive creative capabilities, but one notable observation: Gemini took about 35 minutes on this task, while Opus finished in just 11 minutes. This indicates that Gemini 5.2's speed drops noticeably on tasks involving complex reasoning.
Storm Research Skill: The Power of Multi-Agent Collaboration
The most impressive part of the test was Gemini 5.2's performance running the Storm research skill. The tester used a Goal command to invoke the Storm skill for a comparative study of open-source vs. closed-source AI models.
Storm is an automated research framework developed by Stanford University based on multi-agent collaboration, inspired by academic peer review and multidisciplinary discussion models. In the Storm framework, the system generates multiple virtual "expert agents" with different professional backgrounds and perspectives. These agents engage in structured dialogue and debate around the same topic, ultimately synthesizing various viewpoints into a comprehensive research report. The advantage of this approach is that it simulates real-world multi-perspective analysis, effectively reducing the biases and blind spots that a single model might produce.
Throughout the process, Gemini 5.2 ran a series of sub-agents assigned different role identities — academic, skeptic, practitioner, economist, historian, and more — taking about 27 minutes to generate a detailed HTML research report.
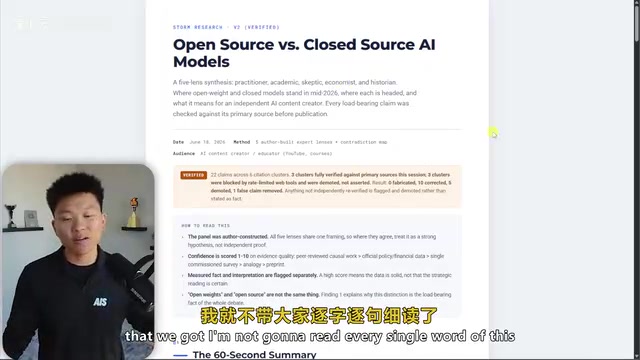
The report provided deep analysis from five perspectives, including a 60-second key takeaway summary and five core findings, each annotated with supporting and dissenting viewpoints. Each agent's role definition determined its analytical angle and evaluation criteria, ensuring multidimensional and balanced final output. This "mixture of experts" multi-agent collaboration model powerfully illustrates a key insight: the importance of prompt engineering and skill orchestration has surpassed that of the underlying model itself.
When to Use Gemini 5.2, When to Use Opus?
After a full day of testing, the tester summarized a practical model selection strategy:
- Gemini 5.2 is ideal for: Information gathering, opinion synthesis, data aggregation, research report generation, and other knowledge-intensive work — covering roughly 80% of daily tasks
- Opus is ideal for: Deep data analysis, logical reasoning, edge case handling, converting research findings into action plans, and other tasks requiring higher-order thinking
This isn't a black-and-white either/or choice, but rather flexible switching at different stages of a workflow. Use Gemini for bulk foundational research, then bring in Opus for refined analysis. This combination strategy ensures quality while significantly reducing costs.
The Strategic Significance of Open-Source Models

The reason Gemini 5.2 is generating so much attention comes down to one core fact: it's open-source. While its 753 billion parameters mean most people can't run it locally, the strategic value of being open-source cannot be overlooked:
First, significant cost advantages. Through platforms like Said AI, a $60/month subscription provides generous usage quotas, while equivalent workloads on Opus could cost up to 5x more.
Second, reduced vendor lock-in risk. Vendor lock-in is a classic risk in enterprise IT, where users become so deeply dependent on a single vendor's products or services that migrating to alternatives becomes prohibitively expensive. In the AI space, this risk is particularly acute: prompt templates, fine-tuning data, and workflow integrations built around specific model APIs are all highly proprietary. Neither Anthropic nor OpenAI is currently profitable — according to multiple reports, OpenAI's operating losses exceeded $5 billion in 2024, and Anthropic is similarly in a massive cash-burning phase. Users paying $200/month for a Max subscription are actually receiving roughly $8,000 worth of inference compute, with platforms operating at a loss. This pricing strategy is essentially venture capital subsidizing user growth. Once the business model adjusts, deeply locked-in users will face enormous migration costs and business disruption risks.
Third, future local deployment potential. As hardware costs continue to decline and model compression techniques advance, open-source models will eventually achieve near-zero-cost local deployment — a massive competitive advantage. Model compression is a key technical direction for running large-scale AI models on consumer hardware, primarily encompassing three categories: quantization, distillation, and pruning. Quantization reduces memory usage and computation by lowering the numerical precision of model parameters (e.g., from 32-bit floating point to 4-bit integer); distillation trains a smaller model using the outputs of a larger model; pruning removes network connections that contribute minimally to final outputs. Taking Gemini 5.2's 753 billion parameters as an example, at FP16 precision it requires approximately 1.5TB of VRAM, far exceeding consumer GPU capacity. However, 4-bit quantization can reduce this to roughly 375GB, and combined with future hardware developments and more advanced compression algorithms, the feasibility of local deployment is steadily improving.
Benchmark Data Confirms Its Strength
On the Frontiers benchmark, Gemini 5.2's performance even surpassed GPT 5.5, while also beating Claude Opus 4.7 and the latest 3.0 model. It maintained a leading position across multiple evaluations including agentic coding.
Benchmarks should only serve as reference points — real-world usage experience is what truly matters. But these numbers at least demonstrate that the gap between open-source and top-tier closed-source models is shrinking rapidly, with open-source even pulling ahead in certain dimensions.
Conclusion: The Most Expensive Isn't Always the Best Fit
The arrival of Gemini 5.2 marks an important turning point in the AI landscape. When an open-source model can run smoothly within the Claude Code framework, completing complex tasks ranging from web design to multi-agent research at just one-fifth the cost of top closed-source models, we have to rethink: when it comes to choosing AI tools, the most expensive option isn't necessarily the best fit.
The real competitive advantage isn't which model you use, but how you craft your prompts, orchestrate your workflows, and design your skill frameworks. The model is just the foundation — the wisdom lies in how the user wields it.
Related articles

Core Insights from Andrew Ng's Prompt Engineering Course: From Fundamentals to Practice
Deep dive into Andrew Ng's ChatGPT Prompt Engineering course: Base vs. Instruction Tuned LLMs, two core prompting principles, and practical developer methodologies.

Codewell Hands-On Review: Is This Terminal AI Coding Assistant with Nearly 40K GitHub Stars Actually Worth It?
Hands-on review of Codewell (formerly DeepSeek2E), the open-source terminal AI coding assistant with nearly 40K GitHub stars. Supports 25 LLM providers, local models at zero cost, and MIT license.

Microsoft Copilot Cowork Introduces DeepSeek: Multi-Model Architecture and Enterprise AI Agent Strategy Explained
Microsoft Copilot Cowork launches with multi-model architecture, considering DeepSeek V4 as a low-cost option. Deep dive into usage-based pricing, WebIQ search, and Microsoft's enterprise AI agent strategy.