Gemini Omni Multimodal Comprehension Test: Absurd Prompts Push AI to Its Limits

Gemini Omni passes an absurd multimodal prompt test, showcasing AI's compositional generalization limits.
A creative stress test using an absurd prompt challenged Google's Gemini Omni to generate a surreal scene combining garlic bread, unicycles, tomato sauce oceans, and T.S. Eliot poetry. This test explores multimodal AI's compositional generalization, cross-domain knowledge integration, and creative generation capabilities.
Google's Gemini Omni model has recently garnered widespread attention on social media. A user conducted an unconventional multimodal comprehension stress test using an extremely absurd prompt, with impressive results.
Gemini Omni is a next-generation native multimodal large model from Google DeepMind. Unlike earlier approaches that stitched together separate modality modules, Gemini was designed from the start to simultaneously understand and generate text, images, audio, and video. This "native multimodal" architecture means the model achieves deep cross-modal fusion at the internal representation level, rather than performing inter-modal translation during inference. This design enables stronger semantic consistency and contextual coherence when handling complex cross-modal tasks.
An "Impossible" Prompt Challenge
This test prompt stands as one of the most creative stress tests in the AI field: it requested a scene depicting "a man eating garlic bread while balancing on a unicycle on a small platform, beneath which churns a sea of tomato sauce, with a meatball wearing a top hat and bright blue eyes sitting in the center of the ocean, while the man recites the 'Death by Water' section from T.S. Eliot's The Waste Land."
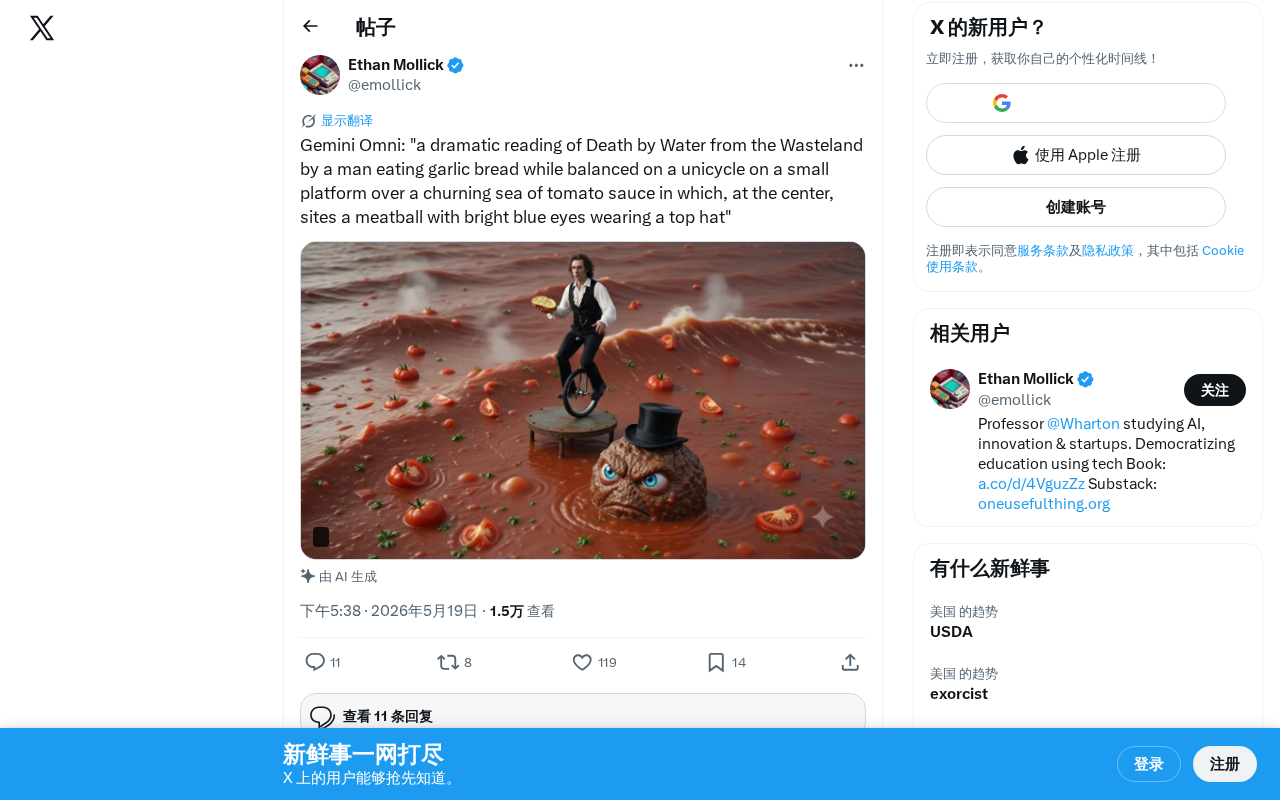
It's worth noting that T.S. Eliot's The Waste Land (1922) is a landmark work of 20th-century modernist poetry. The poem is divided into five parts, and the "Death by Water" section mentioned in the prompt is the shortest—the fourth part—consisting of only ten lines describing the image of the Phoenician sailor Phlebas being eroded by ocean currents after drowning. Choosing this passage as part of the prompt not only requires the model to possess knowledge of classic literature but also to understand the deeper metaphors of death, water, and oblivion—creating a subtle intertextual tension with the absurd "tomato sauce ocean" setting, further testing the model's ability to maintain contextual balance between serious literature and surrealist humor.
The complexity of this prompt manifests across multiple dimensions:
- Layered physical actions: eating + riding a unicycle + maintaining balance
- Surreal scene construction: tomato sauce ocean, anthropomorphized meatball
- Cultural reference integration: dramatic recitation of classic literary works
- Stacked visual elements: specific details like top hat and blue eyes
Exploring the Capability Boundaries of Multimodal AI
These types of tests actually explore several key capability dimensions of current multimodal AI models. To understand the technical implications of these dimensions, one must first grasp how multimodal AI fundamentally works: modern multimodal models are typically based on Transformer architecture, mapping information from different modalities (such as text token sequences, image patch embeddings, and audio spectral features) into a unified high-dimensional vector space for joint representation learning. Models are pre-trained on massive amounts of multimodal data like image-text pairs and video captions, learning the semantic correspondences between different modalities. When receiving a complex text prompt, the model needs to construct a complete scene representation in this shared semantic space, then "decode" it into the target modality output.
Depth of Semantic Understanding
Gemini Omni needs to accurately parse every element in the long sentence and their interrelationships, including spatial relationships ("above," "in the center"), multiple simultaneous actions, and various descriptive details. This places extremely high demands on the model's natural language understanding capabilities.
From a technical perspective, this involves a core challenge in AI—Compositional Generalization. Compositional generalization refers to a model's ability to recombine basic concepts and relationships learned during training to understand and generate novel combinations never seen before. For example, the model may have separately encountered "a person riding a unicycle" and "a bottle of tomato sauce" in training data, but almost certainly never "a person riding a unicycle above a sea of tomato sauce." Traditional deep learning models often perform poorly in such out-of-distribution combinatorial scenarios, but large-scale multimodal models are gradually breaking through this bottleneck through massive data and powerful attention mechanisms. This absurd prompt serves as an excellent test case precisely because it combines numerous everyday concepts in extremely unusual ways, directly testing the model's compositional generalization limits.
Cross-Domain Knowledge Integration
This prompt involves literature (Eliot's The Waste Land), physical common sense (unicycle balance), and surrealist art style. The model needs to fuse knowledge from these vastly different domains into a coherent output—this is precisely the core advantage that distinguishes multimodal AI from single-modality models.
Surrealism, as an art movement originating in the 1920s, emphasizes revealing subconscious truth through dreamlike irrational juxtapositions. Salvador Dalí's melting clocks and René Magritte's floating boulders are classic examples of placing everyday objects in impossible contexts. This prompt essentially asks AI to perform a surrealist creation—fusing garlic bread, unicycles, tomato sauce oceans, and classic poetry, elements with no apparent connection, in a way that maintains internal logical consistency. Whether the model can successfully complete this task reflects whether it truly "understands" the semantic essence of these elements, rather than merely performing surface-level pattern matching.
Creative Generation Capability
Facing scenarios that cannot exist in reality, AI needs to generate content with artistic expressiveness while maintaining internal logical consistency. This capability is crucial for AI applications in creative industries.
Insights from Absurd Testing for AI Development
While these "absurd tests" may seem entertainment-oriented, they actually provide valuable references for AI research and applications. In AI safety and evaluation, similar methods are called "Red Teaming" or "adversarial evaluation." Traditional AI benchmarks (such as ImageNet, MMLU, etc.) typically use standardized datasets and scoring systems, but these tests often fail to cover long-tail scenarios that models might encounter in the real world. User-initiated absurd prompt testing actually constitutes a distributed, creativity-driven stress testing network—millions of users probing model capability boundaries from unexpected angles, with coverage and creativity far exceeding any test suite a single evaluation team could design.
- Stress testing methodology: Discovering capability boundaries and weak points of multimodal models through extreme cases
- Creative application potential: Demonstrating AI's enormous possibilities in artistic creation, advertising design, film concept development, and other fields
- User expectation management: Helping the public more accurately understand current AI's true capability levels
As multimodal models like Gemini continue to evolve, tasks once considered "impossible" are gradually becoming achievable. From an industry trend perspective, multimodal capability is becoming the core battleground for large model competition—OpenAI's GPT-4o, Anthropic's Claude, and Meta's Llama series are all accelerating multimodal capability iteration. The ultimate goal of this race is not just to enable AI to "see" or "hear" information in a single modality, but to achieve true cross-modal reasoning and creation—flowing freely between vision, hearing, language, and common sense like humans do. This also signals the arrival of a new phase in AI-assisted creative work, where creators will gain more powerful tools to realize their wildest imaginations.
Key Takeaways
Related articles
Deep Dive into the Three AI Programmin…
Deep Dive into the Three AI Programming Frameworks: The Right Way to Do Specification-Driven Development
Deep dive into the three frameworks of Specification-Driven Development (SDD) for AI programming: Blueprint, Execution Flow, and Change Records — solving the problem of AI code going off the rails.
AI Aggregator Platforms Tested: A Complete Guide to Using GPT 5.5 and Other Top Models for Free
A hands-on guide to using GPT 5.5, Gemini 3.1 Pro, and Grok 4.2 for free via AI aggregator platforms, covering cross-model context memory, account pool mechanisms, and key security risks.
Vibe Coding in Practice: A Junior Student Uses Cursor to Build a Multi-Agent System with 51 AI Officials Based on the Three Departments and Six Ministries Framework
A junior student uses Cursor and Vibe Coding to build a multi-agent system with 51 AI officials modeled on China's Three Departments and Six Ministries, featuring task distribution, approval workflows, and Token cost visualization.