Getting Started with LLM Fine-Tuning: Teaching AI New Tricks with Your Own Data

A beginner's guide to fine-tuning LLMs with your own data to build specialized AI models efficiently.
This article explains LLM fine-tuning—taking a pre-trained general model and adapting it with your own data to create a specialized AI. It covers three core characteristics: preserving general capabilities while adding domain skills, prioritizing data quality over quantity, and producing stable specialized models. The piece also compares fine-tuning with RAG and prompt engineering, helping readers decide which approach fits their needs.
What Is Fine-Tuning? A Smart Approach That Stands on the Shoulders of Giants
When people want AI to better understand their business, the first instinct is often "let's train a large model from scratch." But in reality, this path is prohibitively expensive—requiring millions or even tens of millions in compute costs, making it impractical for the vast majority of organizations.
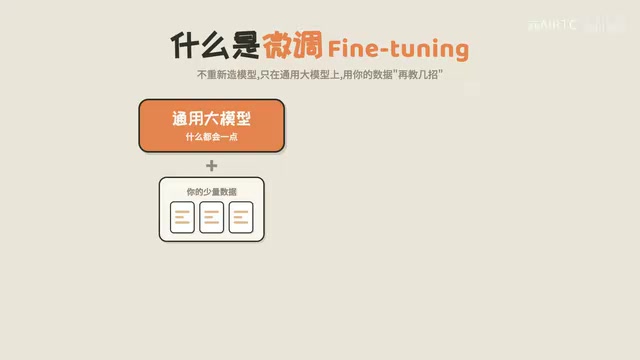
A more practical approach is called fine-tuning. In simple terms, you take an already-intelligent general-purpose large model as your foundation, then feed it a batch of your own data—such as your company's communication scripts or industry-specific cases—letting it learn a few more tricks on top of that foundation, ultimately producing a specialized model that truly understands your needs.

Think of it like hiring a top graduate from an elite university. They already possess solid general knowledge and reasoning abilities—you don't need to teach them elementary math. You just need to familiarize them with your company's workflows, industry terminology, and work standards, and they'll get up to speed quickly. That's exactly what fine-tuning does.
To understand why fine-tuning works, you need to know that large model training happens in two stages. Pre-training is the first stage, where the model digests trillions of tokens of text data from the internet, learning language structure, world knowledge, and reasoning patterns through self-supervised learning (such as next-token prediction). This process typically requires thousands of GPUs running for weeks or even months at enormous cost. Fine-tuning is the second stage, using a dataset far smaller than pre-training to adapt the model to specific tasks through supervised learning. From a technical perspective, fine-tuning essentially makes small adjustments near the parameter space where the pre-trained model has already converged, rather than searching the entire parameter space from scratch—this is the fundamental reason it can achieve significant results at extremely low cost.
Three Core Characteristics of Fine-Tuning
To understand fine-tuning, you need to grasp these three key points:
Characteristic 1: General Capabilities Are Preserved; Only Specialized Skills Are Added
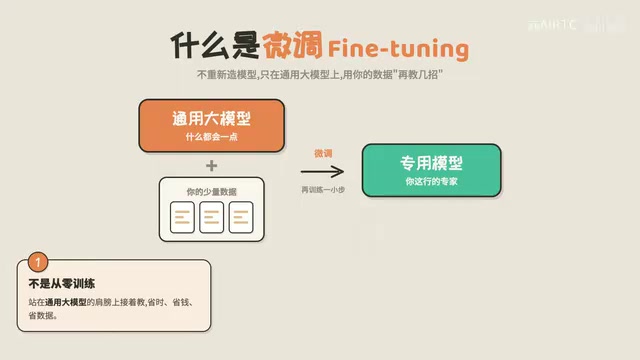
Fine-tuning is not "training from scratch in the wilderness." The general-purpose large model has already learned massive amounts of linguistic knowledge, logical reasoning ability, and world knowledge during pre-training, and these capabilities are preserved during fine-tuning. Fine-tuning simply adds a layer of specialized ability on top of this foundation, rather than starting over.
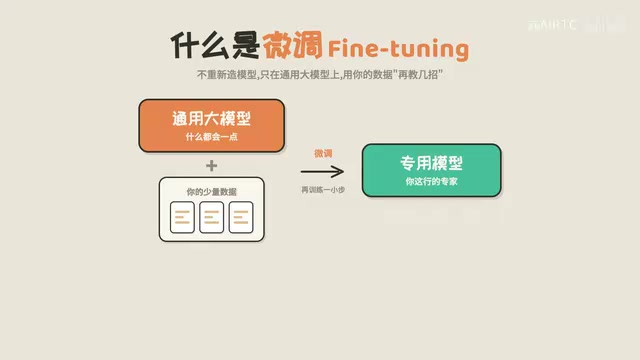
This means the fine-tuned model retains the general model's "intelligence" while gaining the specialized skills you need. This is fine-tuning's greatest advantage—low cost, high efficiency, and great results.
Modern fine-tuning techniques have evolved into multiple efficient implementations, further lowering the barrier to entry. Full fine-tuning updates all model parameters, delivering the best results but at the highest cost. More popular is Parameter-Efficient Fine-Tuning (PEFT), with LoRA (Low-Rank Adaptation) being the most representative method—it inserts low-rank matrices into the model's attention layers, training only these newly added parameters (typically less than 1% of the original model's parameters) to achieve results close to full fine-tuning. QLoRA goes further by quantizing the base model to 4-bit, making it possible to fine-tune a 7-billion-parameter model on a single consumer-grade GPU. These techniques mean fine-tuning is no longer exclusive to big tech companies—small teams and even individual developers can afford it.
Characteristic 2: Data Quality Matters Far More Than Quantity
Fine-tuning only requires your own data, and data quality matters far more than quantity. Many people assume they need massive amounts of data for fine-tuning, but in practice, a few hundred to a thousand high-quality samples are often sufficient.
What constitutes a "high-quality sample"? It can be measured across three dimensions:
- Consistent formatting: Input and output formats are uniform and clear
- Accurate content: The answers themselves are correct and meet business standards
- Coverage of typical scenarios: Covering the most common and important situations in your business
Rather than spending time cobbling together ten thousand samples of varying quality, it's better to carefully craft five hundred high-quality labeled samples.
Characteristic 3: The Output Is a Stable, Specialized Model
The final result of fine-tuning is a specialized model. This model will more consistently output content in the style, format, and tone you require. Compared to repeatedly emphasizing "please respond in such-and-such style" in your prompts every time, a fine-tuned model has already "internalized" these requirements, dramatically improving output consistency and stability.
This is extremely valuable in real business scenarios. For example, in customer service, you want the AI to always respond in a warm, professional tone while strictly following your company's communication guidelines. Or in content generation, you need the AI to always produce reports in a specific format. Achieving these requirements through fine-tuning is far more reliable than relying solely on prompt engineering.
Fine-Tuning Isn't a Silver Bullet: When to Use It and When Not To
While fine-tuning is powerful, not every scenario requires it. Before deciding to fine-tune, consider evaluating two lighter-weight alternatives first:
Alternative 1: RAG (Retrieval-Augmented Generation)
If your core need is for the AI to reference the latest, specific knowledge base content (such as product documentation or regulatory policies), then RAG might be the better choice. RAG retrieves relevant documents in real-time during generation, giving the model "sources to cite" without needing to stuff knowledge into model parameters.
RAG's specific workflow has three steps: First, knowledge base documents are split into small chunks, converted into vectors through an embedding model, and stored in a vector database (such as Pinecone, Milvus, etc.). When a user asks a question, the system first converts the question into a vector and retrieves the most semantically similar document fragments from the vector database. Finally, the retrieved content is concatenated as context into the prompt and handed to the large model to generate the final answer. RAG's core advantage is that knowledge can be updated in real-time (just update the vector database), and answers are traceable—you can clearly see which original text the model referenced. However, it cannot change the model's reasoning approach or output style—this is the fundamental difference between RAG and fine-tuning.
Alternative 2: Prompt Engineering
If your need is simply to adjust output format or style, writing a good system prompt might be sufficient. This is the lowest-cost, fastest-to-implement approach.
Prompt engineering guides model behavior through carefully designed input instructions. Common techniques include: setting roles and constraints with system prompts, providing reference formats through few-shot examples, and guiding complex reasoning with Chain-of-Thought prompting. However, prompt engineering has clear limitations: every request must carry the full instruction text, increasing token consumption and inference latency; the model's adherence to long prompts decreases as length increases (the "instruction forgetting" phenomenon); and it cannot make the model truly "learn" new knowledge patterns—it can only guide within the model's existing capabilities. When you find that your prompt exceeds 2,000-3,000 words and still can't consistently produce satisfactory output, it usually means it's time to seriously consider fine-tuning.
When Do You Actually Need Fine-Tuning?
Fine-tuning is the best choice when you encounter these situations:
- You need the model to deeply understand domain-specific terminology and logic
- You have extremely high requirements for output consistency and stability
- Your prompts are already very long but results are still unsatisfactory
- You need to reduce inference costs (a fine-tuned small model may replace the combination of a large model + long prompts)
The last point deserves elaboration. Suppose you're currently using a GPT-4-level large model with a 2,000-word system prompt to complete a task, with relatively high per-call costs. Through fine-tuning, you can internalize that "instruction knowledge" into a 7B or 13B parameter small model, enabling it to produce equivalent-quality output without long prompts. This not only dramatically reduces per-inference token consumption, but the smaller model itself runs faster and can be deployed on cheaper hardware. OpenAI's research shows that well-fine-tuned small models can match or even exceed the performance of un-fine-tuned large models on specific tasks—for high-frequency production environments, this translates to enormous cost savings.
Summary: Think Before You Act
The essence of fine-tuning is standing on the shoulders of giants and teaching it a few of your own secret techniques. It doesn't require starting from zero, doesn't require massive data, but can give you a specialized AI model that truly understands your business.
However, before you start fine-tuning, ask yourself one question: Can RAG or good prompts solve my problem? If yes, then fine-tuning isn't necessary. If not, fine-tuning is the most worthwhile investment you can make. The wisdom of technical decision-making often lies in knowing when to use which tool.
Related articles
PyCharm 2026.1 Deep Dive: Native AI Coding Assistant & Legitimate Licensing Guide
Deep dive into PyCharm 2026.1: native Claude AI integration, competitive analysis vs Cursor, official free and paid plans, and why to avoid pirated cracks.
CherryStudio + MCP: Tutorial for Build…
CherryStudio + MCP: Tutorial for Building Automated AI Agents and Local Knowledge Bases
Complete guide to building automated AI agents with Cherry Studio and MCP protocol, covering environment setup, MCP Server configuration, web scraping, Shell execution, and Ollama local knowledge base deployment.
MCP Hands-On Tutorial: Using AI to Aut…
MCP Hands-On Tutorial: Using AI to Automate Reverse Engineering of JS Encryption Algorithms
A detailed guide on MCP protocol setup and hands-on workflow showing how AI can automatically locate encrypted APIs, analyze obfuscated JS, set breakpoints, and restore sign algorithms to generate Python scraper code.