Google Flow Integrates Gemini Omni: A Major Upgrade for AI Video Creation
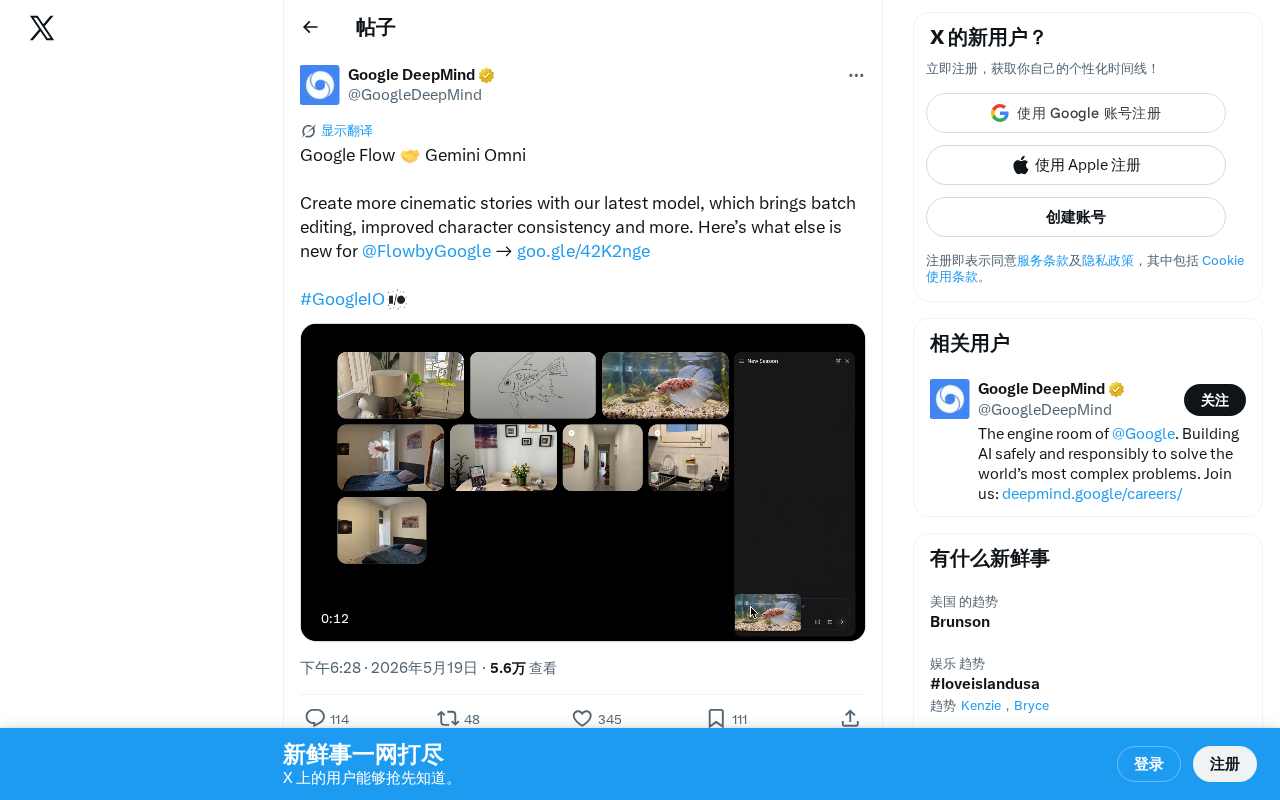
Google Flow integrates Gemini Omni at I/O 2025, upgrading batch editing and character consistency for AI video.
At Google I/O 2025, Google announced the deep integration of its AI video creation tool Flow with the Gemini Omni multimodal model. Key upgrades include batch editing for workflow efficiency, improved character consistency across scenes, and enhanced cinematic output quality. The move positions Google competitively against OpenAI's Sora, Runway, and Pika Labs in the rapidly evolving AI video generation space.
At the 2025 Google I/O conference, Google officially announced the deep integration of its AI video creation tool Flow with the Gemini Omni model, bringing batch editing, improved character consistency, and several other important updates that further lower the barrier to cinematic content creation.
Flow × Gemini Omni: A Powerful Combination
Google Flow is Google's AI-powered video and story creation platform, helping creators quickly generate visually cinematic narrative content. This integration with the Gemini Omni model represents a qualitative leap in Flow's underlying capabilities.
As Google's latest multimodal large model, Gemini Omni possesses powerful text, image, audio, and video understanding and generation capabilities. "Multimodal" refers to a model's ability to simultaneously process and generate multiple types of data, rather than being limited to a single modality. This stands in stark contrast to early large language models that only processed text. The "Omni" (all-capable) naming reflects its unified architecture design for cross-modal understanding and generation — the model can establish semantic connections between different modalities, such as understanding compositional intent from text descriptions, or extracting narrative logic from video clips. This capability is crucial for video creation tools, as filmmaking itself is an inherently multimodal creative process involving the coordination of visual, auditory, and textual script dimensions.
With Gemini Omni integrated into Flow, creators can describe their creative intent in more natural ways and receive higher-quality output. This "creation tool + top-tier model" combination is becoming the standard paradigm in AI content creation.
Three Core Upgrade Highlights
Batch Editing: Dramatically Improved Workflow Efficiency
One of the most practical features in this update is Batch Editing. In previous versions, creators had to adjust content frame by frame or scene by scene, resulting in low efficiency. The batch editing feature allows users to apply unified style adjustments, tone modifications, or element replacements across multiple scenes at once, dramatically improving workflow efficiency.
Notably, batch editing in AI video creation is far more complex than batch processing in traditional video editing software. Traditional tools (like Adobe Premiere's batch export) primarily handle deterministic parameter adjustments, while batch editing in AI video tools requires the model to understand the semantic content of each scene and then uniformly adjust the visual style while keeping the content semantics unchanged. This involves deep learning techniques such as Style Transfer and Conditional Generation. For example, when a user requests changing all scenes from "bright and warm" to "cold and dark," the model needs to understand which elements in each scene belong to lighting and tone, and which are part of the content itself that shouldn't change — requiring fine-grained semantic segmentation and style disentanglement capabilities.
For creators producing long-form narrative content, this feature means they can rapidly iterate and optimize large volumes of material while maintaining overall visual style consistency.
Character Consistency: Solving a Core Pain Point in AI Video Generation
A long-standing pain point in AI-generated content is the character consistency problem — the same character often exhibits noticeable changes in appearance, clothing, or even body type across different scenes. This Flow update specifically addresses this issue.
Character Consistency is recognized as a technical challenge fundamentally because most generative models (such as diffusion model-based architectures) treat the generation of each frame or scene as an independent sampling process. The model starts from random noise and progressively denoises to generate an image based on text prompts, but different sampling processes lack a shared "character identity anchor." Current industry solutions include: IP-Adapter and similar image prompt injection techniques that encode reference character images as feature vectors injected into the generation process; LoRA fine-tuning methods that perform few-shot training for specific characters; and more cutting-edge Identity Embedding approaches that encode facial features, body proportions, and other character information as persistent vector representations.
Leveraging Gemini Omni's powerful multimodal understanding capabilities, Flow can now maintain character identity at a higher semantic level rather than relying solely on pixel-level feature matching, better preserving visual consistency across scenes. This is crucial for creating coherent story narratives and represents a key step in AI video tools evolving from "toys" to "professional tools."
Cinematic Output: Closer to Professional Film Standards
Google specifically emphasized the "cinematic stories" positioning in its announcement. Combined with Gemini Omni's capabilities, Flow has improved in composition, lighting effects, and camera movement, bringing generated content closer to professional filmmaking visual standards.
Competitive Landscape in AI Video Generation
The AI video generation space is fiercely competitive. OpenAI's Sora, Runway's Gen series, Pika Labs, and other products are all iterating rapidly. Google's decision to bind Flow with its most powerful model, Gemini Omni, is clearly aimed at establishing differentiated advantages in this race.
From an industry perspective, each product has its own focus. When OpenAI's Sora debuted in 2024, it stunned the industry with its ability to generate up to one-minute high-quality videos, and its Transformer-based Spacetime Patches architecture was considered a paradigm breakthrough in video generation. Runway is one of the pioneers in this field, with its Gen-1 through Gen-3 series evolving from motion transfer to text-to-video generation, already finding practical application in Hollywood post-production — the Oscar-winning film Everything Everywhere All at Once utilized their technology. Pika Labs is known for its lightweight approach and ease of use, targeting short-form video and social media content creation. Additionally, Stability AI's Stable Video Diffusion, ByteDance's Jimeng, and others are rapidly catching up. These products differ in model architecture, training data, business models, and target user bases, but all face common challenges in video duration, resolution, physical realism, and character consistency.
Compared to competitors, Google Flow's unique advantages include:
- Vertical integration of model capabilities: Gemini Omni's multimodal capabilities can directly serve Flow's various features
- Google ecosystem synergy: Enormous potential for integration with YouTube, Google Cloud, and other platforms
- Data and compute advantages: Google's accumulated training data and computational resources provide a solid foundation for continuous optimization
What This Means for Creators
This update sends a clear signal: AI-assisted content creation is evolving from single image generation toward complete narrative production. This paradigm shift is profoundly significant — early AI image generation tools (like Midjourney, DALL-E) solved the problem of creating individual images, where users input prompts and receive a single picture. But the essence of film and video content creation is narrative across the time dimension, requiring logical coherence between scenes, character emotional arcs, rhythm in cinematographic language, and audio-visual coordination. This means AI tools need to evolve from "generators" to "creation systems," addressing not only single-frame quality but also higher-level creative needs such as Scene Planning, Narrative Structure, and Continuity Management. Flow's positioning as a "story creation platform" rather than a simple "video generator" is precisely a response to this trend.
For independent creators, small studios, and even educators, tools like Flow are making cinematic content production — which previously required significant manpower and funding — increasingly accessible.
However, the advancement of tools also means creators need to invest more energy in creative ideation and narrative design — when technical barriers are leveled, true differentiation will come from the quality of the story itself.
As more details emerge from Google I/O, how the Flow and Gemini Omni combination performs in actual creative work is worth continued attention.
Related articles
Vibe Coding in Practice: A Junior Student Uses Cursor to Build a Multi-Agent System with 51 AI Officials Based on the Three Departments and Six Ministries Framework
A junior student uses Cursor and Vibe Coding to build a multi-agent system with 51 AI officials modeled on China's Three Departments and Six Ministries, featuring task distribution, approval workflows, and Token cost visualization.
How to Connect Codex to DeepSeek Models: Free Switching via CC Switch
Learn how to connect OpenAI Codex to DeepSeek models via CC Switch, enabling free switching between DeepSeek and GPT with complete setup and routing guide.
AI Coding Deployment Guide: A Complete Hands-On Workflow from Local Demo to Live Website
Most AI Coding tutorials stop at local demos. This guide walks through 8 key steps to deploy an AI-powered 3D figurine website from Codex coding to live server deployment.