Grok Build vs GPT 5.5 vs Composer 2.5: Hands-On Comparison Across 17 Frontend Tasks
Grok Build vs GPT 5.5 vs Composer 2.5:…
Grok Build wins 14 of 17 frontend code generation tasks, outperforming GPT 5.5 and Composer 2.5 overall.
A developer tested Grok Build 0.1, GPT 5.5, and Composer 2.5 across 17 complex frontend interaction tasks. Grok Build won 14 tasks, leading in code depth, visual quality, and interaction implementation. GPT 5.5 won 3 tasks, excelling in requirement fidelity and stability. Composer 2.5 didn't win any single task but offers the lowest price and can close the quality gap through multi-round iteration.
Comparing Frontend Code Generation Across Three Major Models
Two AI coding models have recently drawn significant attention: xAI's Grok Build 0.1, available in Grok Build C1 and Cursor IDE, and Cursor's newly released Composer 2.5, marketed as "fast and affordable." According to Cursor's internal benchmark data, Composer 2.5's capabilities rank just below OPPO 4.7 Max and GPT 5.5 Extra High.
To evaluate how these models perform in real-world frontend development, a developer designed 17 complex frontend interaction tasks and ran a comprehensive comparison of Grok Build 0.1, GPT 5.5 (Extra High mode), and Composer 2.5. The evaluation covered multiple dimensions including core functional algorithms, interaction states and event binding, visual style and animations, and interaction documentation and feasibility.
Evaluation Methodology Background: AI model benchmarks fall into two broad categories: automated evaluations (such as code pass-rate tests like HumanEval and MBPP) and human evaluations. This test belongs to the latter category, making it more representative of real development scenarios. The 17 complex frontend tasks span a wide range of technical dimensions—Canvas animations, physics simulations, 3D rendering, state machine logic, and more—effectively distinguishing between models' capabilities at the "basic code completion" level versus the "complex system design" level. Frontend code generation is particularly challenging because it requires not only understanding HTML/CSS/JavaScript syntax rules, but also grasping the interplay between visual design intent, interaction logic, and browser rendering mechanisms—placing extremely high demands on a model's multimodal comprehension.
Overall Scores and Win Distribution
The final results are quite revealing: Grok Build won 14 out of 17 tasks, GPT 5.5 took 3, and Composer 2.5 failed to win any single task.
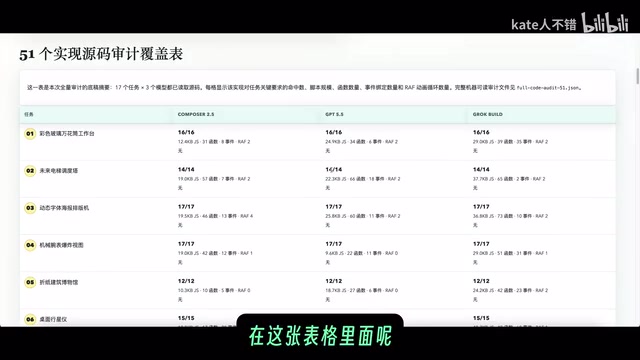
Based on the evaluation data, each model has distinct characteristics:
- Grok Build: Produced the most code, delivered the most complete event binding and complex interaction implementations, and achieved the best code depth across multiple tasks. However, it occasionally suffered from overly dense page layouts or off-target styling.
- GPT 5.5: Most faithful to task requirements, provided the most complete interaction documentation, and performed best in terms of requirement coverage.
- Composer 2.5: Lightweight implementations with smaller code footprints, but noticeably underperformed compared to the other two on complex tasks.
Cursor IDE and the AI Coding Tool Ecosystem: Cursor is an AI-native IDE built as a deep modification of VS Code. Its core differentiator lies in deeply integrating large language models into the code editing workflow, rather than treating them as simple plugins. The Composer feature allows users to generate or modify entire code files through natural language descriptions, complementing GitHub Copilot's line-level completions. By partnering with multiple model providers (including Anthropic, OpenAI, and others), Cursor has built a multi-model orchestration layer that lets users switch between different underlying models within the same IDE—this is the technical foundation that enables Composer 2.5 to be released as a standalone product.
In-Depth Analysis of Key Tasks
Stained Glass Kaleidoscope Workbench
This was one of GPT 5.5's strongest tasks. GPT 5.5 generated a kaleidoscope with rich patterns, adjustable colors, numerous parameters, and impressive visual depth. In contrast, Composer 2.5 loaded into a mostly black interface, and clicking "random generate" produced no response—a disappointing result.
Grok Build revealed an interesting phenomenon on this task—its UI style closely resembled early GPT 5.5, with heavy use of rounded design elements. The tester speculated that Grok may have retained significant GPT 5.5 data characteristics during training. In AI research, this is known as "style leakage" or training data distribution bias: if training data includes a large volume of code generated by a specific model (so-called "synthetic data"), the model will learn the stylistic features of that data source, sparking industry discussion about "models training on each other leading to style convergence."
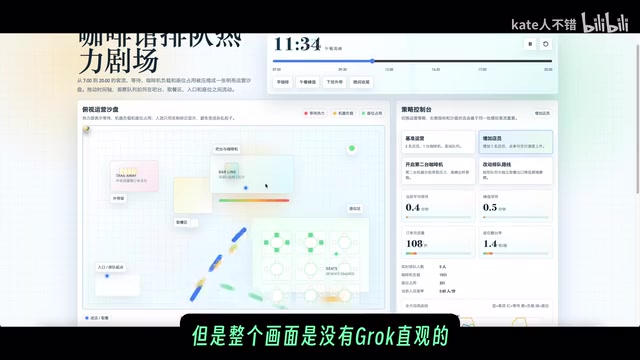
Café Queue Simulation Theater
This task best demonstrated a model's ability to understand complex interaction logic. Grok Build's performance was impressive:
- The heatmap queue simulation was the most vivid, with characters rendered as cute stick figures
- The flow logic of queuing → picking up coffee → walking to the exit was completely coherent
- Supported interactions like time fast-forward, adding staff, and adding coffee machines
- As time progressed, the coffee level in machines gradually decreased—an excellent attention to detail
GPT 5.5 also implemented the basic functionality, but when "adding staff," the new personnel couldn't be seen on screen, and the overall visual was less intuitive and lively than Grok's. Composer 2.5 lacked dynamic effects, with overly simplistic interaction representations.
Desktop Orrery
In terms of 3D visual rendering, all three models showed varying degrees of shortcomings. GPT 5.5's planetary textures were mediocre, Composer 2.5's display had noticeable rendering artifacts, and its material types, base/table details, and nameplate information all fell short of the other two models. While Grok Build delivered the best overall performance, it still fell short of the ideal result.

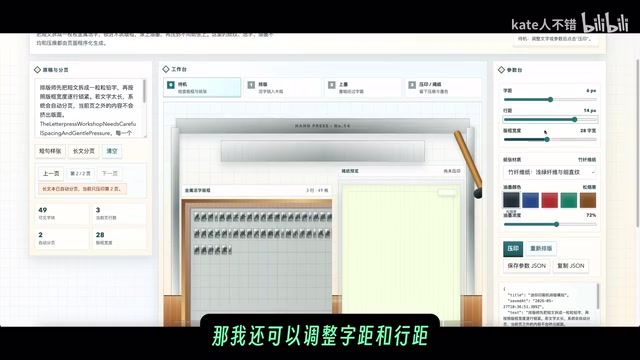
Mini Printing Press Typesetting Simulation
Grok Build offered three styles—wooden movable type, metal movable type, and an antique hybrid—and thoughtfully included vertical typesetting and faux-antique material options. However, there was one notable oversight: in real movable type printing, the characters on the type blocks should be mirror-reversed, but the application didn't reflect this.
Technical Details of Movable Type Printing: In movable type printing, the type blocks must be mirror-reversed—this is a fundamental physical constraint of the printing process. The raised, reversed characters are inked and pressed onto paper to produce correctly oriented text. This detail serves as a classic test of "common-sense domain knowledge," requiring the model to correctly map physical-world craft logic into a digital simulation. Grok Build's oversight here reveals a common limitation of current large models: when handling implicit cross-domain expertise, models tend to prioritize visual intuition (the user should see correctly oriented text) over the physical authenticity of the craft process.
GPT 5.5 also performed well on this task, supporting long-text pagination, character spacing and line height adjustments, and real-time changes displayed on the metal type frame. After pressing, it even rendered the characteristic blurred ink impressions of printing—a strong attention to detail. However, there were noticeable inaccuracies in ink color reproduction.
Pricing and Cost-Effectiveness Analysis
Composer 2.5 is the cheapest of the three, available in Standard and Fast modes, with Fast mode priced at 6x the Standard rate. For users who don't need speed, Standard mode offers excellent value for money.
Grok Build is priced higher than Composer 2.5, but its quality advantage is clear. One noteworthy detail: some users have reported that while Composer 2.5's first-pass output may not be ideal, after two or three rounds of prompt refinement, accuracy improves significantly.
Multi-Round Iteration and Prompt Engineering: This phenomenon underscores the importance of prompt engineering in practical AI applications. Multi-round conversational iteration is essentially a collaborative, incremental process of requirement clarification between human and machine: initial prompts often contain ambiguity, and the model's first output amounts to a "speculative implementation" of the requirements, while the user's corrective feedback provides more precise constraints. For budget-sensitive scenarios, a strategy of "low-cost model + multi-round iteration" often achieves a better balance between total cost and output quality than simply pursuing the model with the highest single-pass generation quality. This means that in practice, a well-crafted prompting strategy can effectively bridge the capability gap between models.
Summary and Model Selection Recommendations
Based on the comprehensive results across 17 complex frontend tasks:
| Dimension | Best Model |
|---|---|
| Code Depth | Grok Build |
| Requirement Coverage | GPT 5.5 |
| Visual Quality | Grok Build |
| Stability | GPT 5.5 |
| Cost-Effectiveness | Composer 2.5 |
If you need to generate complex frontend interactive pages, Grok Build is the overall recommendation. It demonstrated the strongest capabilities in code depth, visual quality, and interaction implementation. GPT 5.5 is better suited for scenarios that demand high requirement fidelity and stability. While Composer 2.5 doesn't lead in single-pass generation quality, its price advantage combined with a multi-round iteration strategy makes it a reliable choice when budgets are tight.
Looking ahead, as Grok 5 development progresses—building on the existing Grok Build foundation and incorporating Cursor's data—its frontend code generation capabilities are expected to improve further, setting the stage for even fiercer competition with top-tier models.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.