In-Depth Analysis of the AI Large Model Job Market: Two Core Directions and Future Trends

In 2025, AI large model careers have converged into algorithm research and engineering deployment.
The 2025 AI large model job market has matured from early exploration into clear specialization, converging into algorithm research and engineering deployment. Algorithm research has extremely high barriers (top-tier Master's + top conference papers) but offers the best job prospects due to talent scarcity. Engineering deployment is accessible with a bachelor's degree, covering Agent, RAG, and fine-tuning work, with growing demand but inevitable future saturation. Regardless of direction, continuous learning remains the only certain strategy.
Introduction
Since 2025, the job market in the AI large model space has undergone significant changes. Compared to 2024, job directions have become more focused and industry specialization more defined. Based on in-depth analysis from seasoned practitioners, this article outlines the current reality of AI large model employment, the two core career directions, and future development trends.
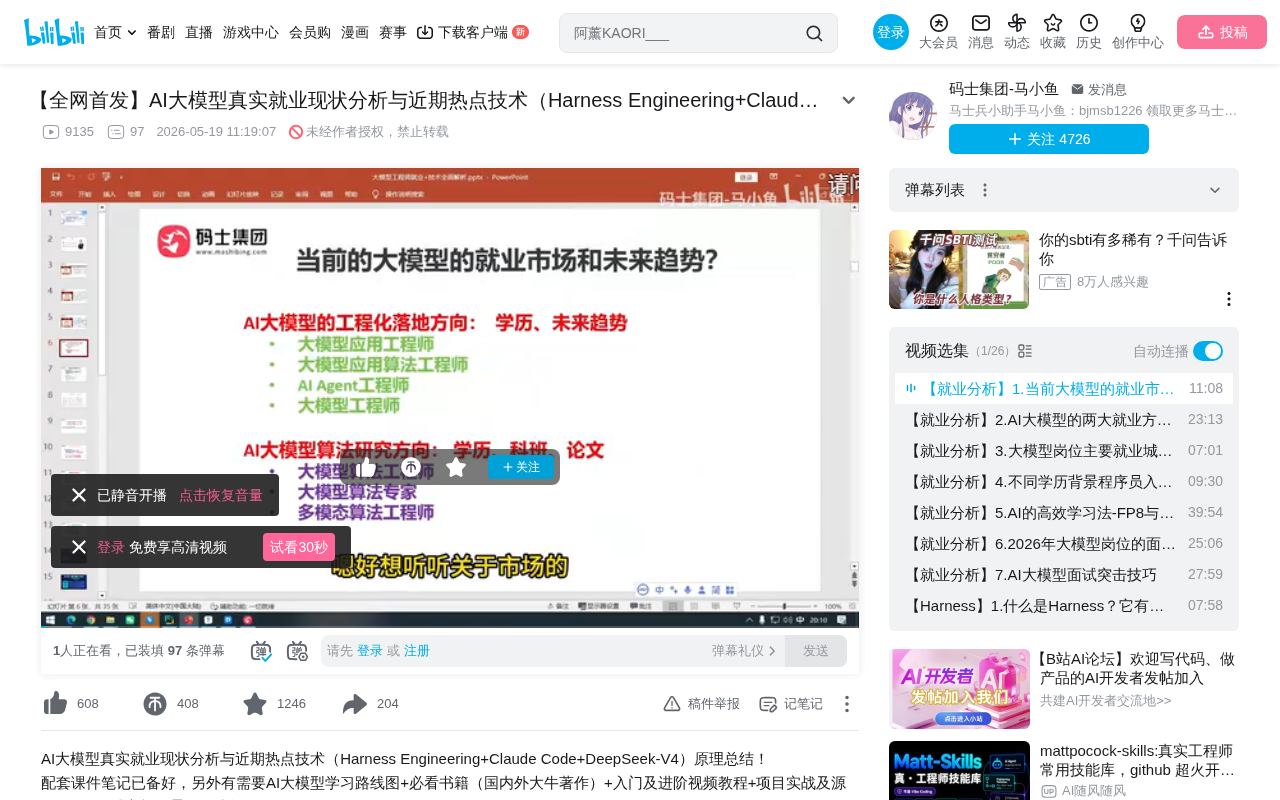
Only Two Directions Remain in AI Large Model Employment
Unlike 2024, when AI large model employment was divided into three directions, by 2025 the entire market has converged into two core directions:
- Large Model Engineering & Deployment
- Large Model Algorithm Research
All AI large model-related positions, regardless of their titles, essentially belong to one of these two directions. This shift reflects the industry's transition from early exploration into a more mature phase of specialization—you're either working on foundational algorithm innovation or on upper-layer application deployment. This binary differentiation is not uncommon in the tech industry, similar to how early internet development gradually split into frontend and backend. When a technology domain matures, professional specialization is an inevitable trend.
Direction One: Large Model Algorithm Research
Job Definition and Core Responsibilities
The algorithm research direction is primarily responsible for foundational research on large model algorithms within an organization, including:
- Writing and optimizing operators
- Optimizing the training process of large models
- Optimizing the inference process of large models
- Exploring new model architectures and training paradigms
It's important to deeply understand the technical implications of this work. An operator is the most basic computational unit in deep learning frameworks—matrix multiplication, convolution operations, activation functions, etc. Writing and optimizing operators means achieving extreme performance optimization at the level of low-level programming languages like CUDA, tailored to GPU hardware characteristics. This requires both deep mathematical foundations and systems engineering expertise. Training optimization involves distributed training strategies (data parallelism, model parallelism, pipeline parallelism), mixed-precision training, gradient accumulation, and more. Inference optimization includes model quantization, KV Cache optimization, Speculative Decoding, and other cutting-edge methods. This work directly determines whether large models can run in production environments at reasonable cost.
Entry Barriers and Hard Requirements
The entry barrier for this direction is extremely high:
- Minimum education: Master's degree from a top-tier (985) university
- Major requirements: Must be in Computer Science or Mathematics (strictly formal academic background)
- Publication requirements: Papers at top conferences/journals required; regular journal publications are not recognized
The "top conferences" mentioned here refer to NeurIPS, ICML, ICLR, CVPR, ACL, AAAI, and other premier international academic venues, which typically have acceptance rates of 20%-30% and represent the most cutting-edge research in the field. Companies set such high bars because algorithm research requires the ability to independently propose innovative solutions and design experiments to validate hypotheses—top conference papers are the most direct signal proving this capability.
Current Employment Situation
You might not have noticed, but despite the extremely high barriers, this direction is currently the easiest to find a job in—bar none. The reason is simple: talent meeting these criteria is extremely scarce. Typical positions include: Large Model Algorithm Engineer, Large Model Algorithm Expert, Multimodal Algorithm Engineer, etc. In terms of compensation, fresh master's graduates in these roles typically start at 400,000-600,000 RMB annually, while senior researchers can earn over one million, fully reflecting the extreme supply-demand imbalance.
Direction Two: Large Model Engineering & Deployment
Job Definition and Core Responsibilities
The engineering and deployment direction is the choice for most practitioners. Core work includes:
- Application development based on existing foundation models (e.g., using DeepSeek, OpenAI models)
- Agent development
- RAG (Retrieval-Augmented Generation) system development
- Model fine-tuning
- Implementing GraphRAG with knowledge graphs
- Calling multimodal models (e.g., YOLO) for image processing
In short, this direction focuses on combining large models with enterprise business needs, completing the last mile from technology to product.
Agent Development Explained
Agents are the core hotspot of large model applications in 2024-2025. Unlike simple conversational AI, Agents possess capabilities for autonomous planning, tool calling, memory management, and multi-step reasoning. Typical Agent frameworks include LangChain, LlamaIndex, AutoGPT, CrewAI, etc. In enterprise scenarios, Agents can autonomously complete complex business processes such as automated data analysis, customer service ticket handling, code generation and debugging. Multi-Agent (multi-agent collaboration) systems are an even hotter research topic—multiple Agents with different roles and capabilities working together, simulating human team division of labor, and are considered one of the important paths toward AGI.
Technical Principles of RAG Systems
RAG (Retrieval-Augmented Generation) has been one of the most important large model application paradigms since 2023. Its core idea is: before the large model generates an answer, first retrieve relevant document fragments from an external knowledge base, inject them as context into the prompt, allowing the model to generate answers based on the most current and accurate information. This approach effectively addresses the "hallucination" problem and knowledge timeliness issues of large models. A complete RAG system typically includes document parsing, text chunking, embedding (vectorization), vector database storage, similarity retrieval, reranking, and generation—each stage offering substantial engineering optimization opportunities.
GraphRAG and Knowledge Graph Integration
GraphRAG is an enhanced retrieval method proposed by Microsoft in 2024 that combines traditional RAG's vector retrieval with knowledge graph structured reasoning. Traditional RAG performs poorly on questions requiring cross-document reasoning or global summarization, while GraphRAG captures deep semantic relationships between documents by constructing entity-relationship graphs. Its workflow includes: extracting entities and relationships from documents, building knowledge graphs, performing community detection and hierarchical summarization based on graph structure, and ultimately leveraging both vector similarity and graph structural information during retrieval. This approach is particularly suited for enterprise knowledge management, legal document analysis, medical diagnosis assistance, and other scenarios requiring complex reasoning.
Entry Barriers and Technical Requirements
- Minimum education: Bachelor's degree
- Tech stack: Must master the full-chain technology of large model application development
Specifically, the engineering and deployment tech stack typically includes: Python programming, calling and integrating mainstream large model APIs, Prompt Engineering, vector databases (such as Milvus, Pinecone, Weaviate), development frameworks like LangChain/LlamaIndex, Docker containerized deployment, and basic frontend/backend development capabilities. As the industry evolves, requirements for engineers continue to rise—merely knowing how to call APIs is no longer sufficient; understanding model capability boundaries and optimization strategies is also necessary.
Important Clarification: Engineering & Deployment ≠ No Algorithm Knowledge Needed
A critical point must be emphasized here: the engineering and deployment direction absolutely does not mean you don't need to learn algorithms. This is a common misconception. Even when doing application-layer development, understanding underlying algorithm principles is crucial for system optimization, troubleshooting, and solution selection. For example, when building a RAG system, you need to understand how Embedding models work to choose appropriate chunking strategies; when fine-tuning models, you need to understand the mathematical principles of parameter-efficient fine-tuning methods like LoRA (Low-Rank Adaptation) to correctly set hyperparameters; when debugging Agent reasoning errors, you need to understand the attention mechanism and context window limitations of large models.
Additionally, some traditional CV (Computer Vision) work, such as using YOLO or convolutional neural networks for image processing, falls under the engineering and deployment direction in the current classification system rather than algorithm research. This is because models like YOLO are already very mature, and using them is more of an engineering integration task rather than algorithmic innovation.
Future Trend Analysis
Development Prospects for Engineering & Deployment
In terms of job volume, demand for the engineering and deployment direction will continue to grow—this is the highest-certainty trend. Currently, virtually every industry is exploring large model application scenarios: intelligent risk control and investment research assistants in finance, assisted diagnosis and drug development in healthcare, personalized learning in education, intelligent quality inspection and supply chain optimization in manufacturing, etc. This industry-wide digital intelligence upgrade will continue creating massive numbers of engineering and deployment positions.
However, it's important to maintain a clear-eyed perspective:
- The number of practitioners is also growing rapidly
- Industry saturation will inevitably occur—the timing is uncertain (possibly 2027, 2028, or after 2030)
- At that point, pivoting to new technical directions may be necessary
This pattern has played out repeatedly in the IT industry: from early web development, to mobile internet development, to big data development—each technology wave has gone through the cycle of "talent scarcity → mass influx → oversupply → new direction emerges." The AI large model field will be no exception. The key is to accumulate sufficient technical depth and industry knowledge during the dividend period.
Evolution Path for Algorithm Research
The algorithm research direction is also constantly evolving:
- Currently focused primarily on AIGC algorithm research
- May shift toward Embodied AI algorithm research in the future
- May also shift toward World Model algorithm research
Embodied AI refers to embedding AI systems in physical entities (such as robots), enabling them to perceive the physical world, interact physically, and learn from those interactions. Unlike large language models operating purely in the digital world, Embodied AI must handle continuous perception-decision-execution loops, facing the uncertainty and real-time challenges of the physical world. World Models are AI models capable of understanding and predicting the operating principles of the physical world—they can simulate possible future scenarios in "imagination" to guide decision-making. Since 2024, video generation models represented by Sora have been considered prototypes of World Models, while Tesla's FSD and Figure's humanoid robots are typical applications of Embodied AI. These two directions are widely regarded as the next major battleground for large model technology.
The good news is that despite shifting hot topics, the foundational machine learning and deep learning algorithms haven't fundamentally changed in over a decade. From early CNNs for image recognition, to the rise of the Transformer architecture in 2017-2018, to today's large language models—the core remains the neural network paradigm. Changes are more reflected in network topology architecture and engineering implementation.
The Historical Significance of the Transformer Architecture
The 2017 Google paper "Attention Is All You Need" introduced the Transformer architecture, fundamentally changing the landscape of natural language processing and the entire deep learning field. Before this, sequence modeling primarily relied on RNNs (Recurrent Neural Networks) and LSTMs (Long Short-Term Memory networks), which were difficult to parallelize due to their sequential computation nature, resulting in low training efficiency. The Transformer achieved direct information interaction between any positions in a sequence through the Self-Attention mechanism and naturally supports parallel computation, making it possible to train ultra-large-scale models. From BERT to the GPT series, from ViT to Stable Diffusion, virtually all modern AI breakthroughs are built on the Transformer architecture. This confirms the point above: the underlying algorithmic framework remains relatively stable, with changes occurring more at the architectural detail and engineering implementation level.
Continuous Learning Is the Only Certainty
Regardless of which direction you choose, one iron rule remains unchanged: programmers must continuously learn. Once learning is interrupted for more than three years, you'll most likely be eliminated by the industry. This isn't unique to AI large models—it's an objective reality of the entire IT industry.
From a practical standpoint, effective approaches to continuous learning include: following the latest papers on arXiv (especially categories like cs.CL, cs.CV, cs.AI), contributing to open-source projects, regularly reproducing cutting-edge work, attending industry technical conferences, and constantly experimenting with new technologies in real projects. For practitioners in the engineering and deployment direction, it's recommended to invest at least 5-10 hours per week in technical learning and experimentation; for those in algorithm research, daily tracking of the latest research developments is essential.
Summary and Recommendations
The core characteristic of the current AI large model job market is converging directions with clear specialization. Recommendations for practitioners with different backgrounds:
- Top-tier (985) Master's + formal CS/Math background + top conference papers: Prioritize the algorithm research direction—there's an extreme talent shortage right now
- Bachelor's degree and above: The engineering and deployment direction is a pragmatic choice, but don't neglect building algorithm fundamentals
- Everyone: Maintain continuous learning habits, stay aware of industry changes, and be prepared to pivot directions
Additionally, a few supplementary suggestions: First, regardless of direction, English proficiency is very important since the most cutting-edge technical documentation, papers, and community discussions are almost entirely in English. Second, build your own technical portfolio (GitHub projects, technical blogs)—this carries increasing weight in job searches. Third, focus on accumulating domain knowledge in vertical industries—"AI + Industry" compound talent will become increasingly competitive in the future.
The pace of change in the AI industry far exceeds traditional IT. Only by maintaining learning agility and taking action can you stay competitive in this rapidly evolving field.
Key Takeaways
- The 2025 AI large model job market has converged into two directions: Engineering & Deployment and Algorithm Research
- The algorithm research direction has extremely high barriers (top-tier Master's + formal background + top conference papers), but is actually the easiest to find work due to talent scarcity
- The engineering and deployment direction is accessible with a bachelor's degree, covering Agent development, RAG, fine-tuning, etc., but still requires algorithm fundamentals
- The engineering and deployment direction will inevitably face saturation—the timing is uncertain but the trend is definite
- Foundational deep learning algorithms haven't fundamentally changed in over a decade; continuous learning is the only strategy for navigating industry changes
Related articles
 Industry Insights
Industry InsightsAI Product Development in Practice: Model Selection, Building Moats, and Paths to Commercialization
Practical strategies for AI product development: why not to train models from scratch, when to use APIs vs. fine-tuning, building product moats, and the full path from evaluation systems to commercialization.
 Industry Insights
Industry InsightsNo Product Fits Your Needs? Building It Yourself Is the Best Starting Point for Indie Developers
Can't find a product that fits? Building from personal pain points is the best entry for indie developers. Niche needs + AI tools = rapid product creation.
 Industry Insights
Industry InsightsOpenAI Codex Tutorials Mass-Copied on Bilibili, Highlighting AI Content Farm Problem
At least 9 Bilibili accounts mass-published identical OpenAI Codex tutorial videos, exposing content farm operations in the AI tools space.