Manus Hands-On Review: How Does This AI Agent Perform on the DeepSeek Tech Stack?
Hands-on review of Manus AI Agent's real-world performance powered by DeepSeek's reasoning engine.
This article analyzes the performance of AI Agent product Manus running on DeepSeek as its underlying model, based on a hands-on test by a Bilibili creator. DeepSeek's MoE architecture and RL-trained reasoning capabilities show clear advantages in task decomposition and Chain-of-Thought reasoning, with notable cost benefits. However, real-world Agent effectiveness is also constrained by tool invocation stability, context management, and error recovery. Chinese-developed models hold strategic value in the Agent space through cost efficiency, data compliance, and ecosystem synergy.
Introduction
As one of the most talked-about AI Agent products recently, Manus's choice of underlying model directly impacts the quality and efficiency of its task execution. Bilibili creator "花师小哲" (Huashi Xiaozhe) conducted a hands-on test of Manus running on the DeepSeek tech stack, providing firsthand usage experience for reference.
Manus + DeepSeek: Technical Background
What Is Manus AI Agent?
Manus is a general-purpose AI Agent capable of autonomously planning tasks, invoking tools, and executing multi-step operations. Unlike traditional conversational AI, Manus emphasizes "end-to-end" task completion — users simply describe their goal, and the system automatically breaks it down into steps and executes them one by one.
To understand Manus's positioning, it's essential to clarify the fundamental difference between AI Agents and traditional chatbots. Traditional conversational AI (such as early ChatGPT usage patterns) is essentially a "Q&A system" — the user asks, the model answers, and the interaction completes within single or multi-turn conversations. AI Agents, on the other hand, possess autonomy — they can perceive their environment, formulate plans, take actions, and adjust strategies based on feedback. Architecturally, an Agent typically comprises four core components: a Planning module, a Memory module, a Tool Use module, and an Action module. Manus's design philosophy integrates these modules organically, transforming the large language model from a "passive responder" into an "active executor" capable of operating browsers, writing code, managing files, and truly completing complex real-world tasks.
Core Characteristics of the DeepSeek Tech Stack
As a leading Chinese-developed large language model, DeepSeek is renowned for its powerful reasoning capabilities and open-source strategy. The DeepSeek-R1 series excels in mathematical reasoning, code generation, and similar tasks, while its MoE (Mixture of Experts) architecture effectively controls inference costs without sacrificing performance.
The MoE (Mixture of Experts) architecture is a key innovation in DeepSeek's technical approach. Traditional dense models (like GPT-4) activate all parameters during each inference pass, whereas MoE architecture divides the model into multiple "expert networks" and activates only a small subset of relevant experts per inference. DeepSeek-V3's MoE architecture has 671 billion total parameters but activates only about 37 billion per inference — meaning it achieves large-model capabilities while dramatically reducing computational overhead. Furthermore, DeepSeek-R1's core breakthrough lies in using large-scale reinforcement learning (RL) training to enable the model to spontaneously develop deep thinking and self-verification abilities, rather than relying solely on supervised fine-tuning. This training paradigm allows the model to generate detailed thinking chains (Thinking Chains) when facing complex reasoning tasks, deriving correct answers step by step. On the open-source front, DeepSeek releases model weights under the MIT license, providing tremendous flexibility for downstream applications — including Agent systems — to customize and develop.
When Manus adopts DeepSeek as its underlying reasoning engine, it theoretically gains advantages in the following areas:
- Stronger logical reasoning for complex tasks
- Higher comprehension and generation quality in Chinese-language scenarios
- Relatively lower inference costs, well-suited for multi-step Agent invocations
Hands-On Case Analysis: Manus's Task Execution Performance on DeepSeek
Task Execution Workflow in Detail
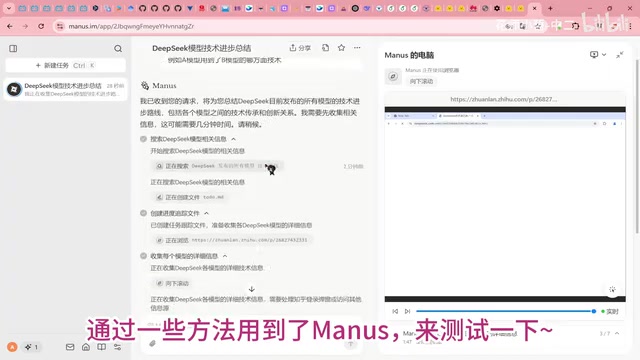
From the test video, after receiving user instructions, Manus goes through stages of task understanding, plan formulation, step-by-step execution, and result summarization. The DeepSeek model demonstrated solid logical coherence in the task decomposition phase, effectively breaking complex requirements into executable subtasks.
The technical framework behind this workflow closely aligns with mainstream Agent design paradigms. The widely adopted ReAct (Reasoning + Acting) framework requires the model to first reason at each step — thinking about the current state and what to do next — then act — invoking tools or generating output — and finally observe the result before entering the next cycle. Manus's task decomposition process is essentially a hierarchical planning problem: the top level breaks the user's goal into sub-goals, and each sub-goal is further decomposed into specific executable steps. DeepSeek's powerful reasoning capability is particularly critical here, because the quality of task decomposition directly determines the success rate of subsequent execution — an unreasonable plan may fail to achieve the goal even if every individual step is executed correctly.
Strengths and Weaknesses
On the DeepSeek tech stack, Manus shows clear advantages in Chinese comprehension and reasoning chains, especially in scenarios requiring multi-step deliberation, where DeepSeek's Chain-of-Thought capability helps the Agent make more rational decisions.
Chain-of-Thought (CoT) is a technical paradigm that enables large language models to display intermediate reasoning steps. Unlike directly outputting a final answer, CoT requires the model to make its thinking process explicit — for example, when solving a multi-step task, the model first analyzes various aspects of the problem, lists possible approaches, evaluates the pros and cons of each, and ultimately selects the optimal path. Through reinforcement learning training, DeepSeek-R1 enables the model to autonomously generate thinking chains spanning thousands of tokens, which in Agent scenarios means the system can conduct thorough "internal deliberation" before executing each step, thereby reducing the probability of erroneous decisions.
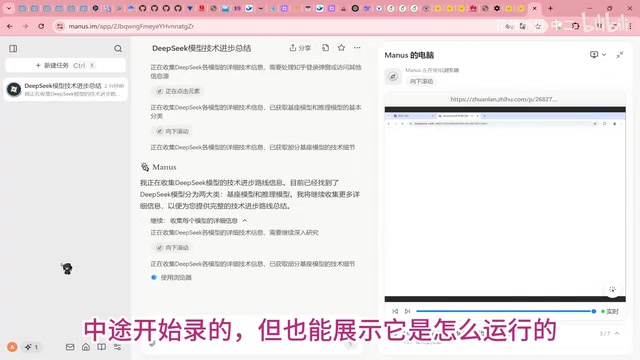
However, the performance of Agent products depends not only on the underlying model but is also influenced by multiple factors including tool invocation stability, context window management, and error recovery mechanisms.
Tool calling (Function Calling / Tool Use) is one of the most failure-prone components in Agent systems. The model must accurately determine when to call a tool, which tool to call, and how to construct the correct parameter format — any deviation in these steps can lead to execution failure. Context window management is another core challenge: as the Agent executes more steps, historical information accumulates rapidly and can quickly exceed the model's context length limit. How to retain the most critical information within a limited context (such as task objectives, completed steps, and key intermediate results) while discarding redundant content is a crucial engineering problem in Agent system design. Error recovery mechanisms require the Agent to identify the cause of failure when a step goes wrong, roll back to an appropriate state, and attempt alternative approaches — rather than simply terminating the entire task flow.
Deep Dive: Choosing the Right Tech Stack
The Relationship Between Model Capabilities and Agent Effectiveness
For AI Agents, choosing the underlying model involves multi-dimensional trade-offs:
- Reasoning ability: Determines the quality of task planning
- Instruction following: Affects the accuracy of tool invocations
- Context length: Limits the depth of complex task processing
- Response speed: Directly impacts user experience
DeepSeek's advantage in reasoning makes it a strong candidate for Agent scenarios, but real-world applications still require Agent-specific optimization.
It's worth exploring in depth that Agent scenarios demand fundamentally different model capabilities compared to general conversation. In general dialogue, a model's "creativity" and "fluency" tend to be more valued; in Agent scenarios, "precision" and "reliability" are the core metrics. An Agent model must strictly follow predefined output formats (such as JSON-formatted tool invocation instructions) — any format deviation will cause system parsing failures. Additionally, Agent scenarios require the model to have strong "self-monitoring" capabilities — the ability to judge whether the current step succeeded, whether a retry is needed, and when to request clarification from the user. Current industry explorations include: Agent-specific fine-tuning (Agent Tuning), optimizing tool invocation success rates through reinforcement learning, and designing more robust Prompt Engineering frameworks to constrain model behavior. Companies like OpenAI and Anthropic are also actively advancing "Computer Use" capability training, which aligns closely with Manus's product direction.
The Prospects of Chinese-Developed Models in AI Agent Applications
With the rapid iteration of Chinese-developed models like DeepSeek, the AI Agent ecosystem built on domestic models is gradually maturing. This means not only lower usage costs but also more possibilities for data security and local deployment.
From an industry ecosystem perspective, Chinese-developed models' positioning in the Agent space carries multiple strategic implications. First is the cost advantage: DeepSeek's API pricing is significantly lower than overseas models like GPT-4, and since Agent applications require multiple model calls (a complex task may need dozens or even hundreds of model invocations), the inference cost differential is amplified considerably. Second is data compliance: in sensitive sectors like finance, healthcare, and government, using domestic models avoids cross-border data compliance risks while supporting private deployment. Finally, there's ecosystem synergy: as the domestic open-source community grows, a complete technology stack has formed around models like DeepSeek — including inference frameworks (vLLM, SGLang), Agent frameworks (such as domestic adaptations of MetaGPT and AutoGen), and vertical domain applications — providing solid infrastructure support for rapid Agent product iteration.
Conclusion
The hands-on testing of Manus on the DeepSeek tech stack demonstrates the potential of Chinese-developed large language models in Agent applications. While there's still room for optimization, this direction deserves continued attention. For developers and users alike, understanding the characteristics of different tech stacks helps in making more informed choices.
Key Takeaways
- Manus supports running on the DeepSeek tech stack, leveraging its strong reasoning capabilities to improve Agent task planning quality
- DeepSeek's MoE architecture offers cost advantages in multi-step Agent invocation scenarios
- An AI Agent's real-world performance is jointly influenced by model capabilities, tool invocation stability, context management, and other factors
- The application prospects of Chinese-developed large language models in the Agent ecosystem deserve close attention
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.