NVIDIA ACE SDK: On-Device AI Inference for Intelligent Game NPC Companions
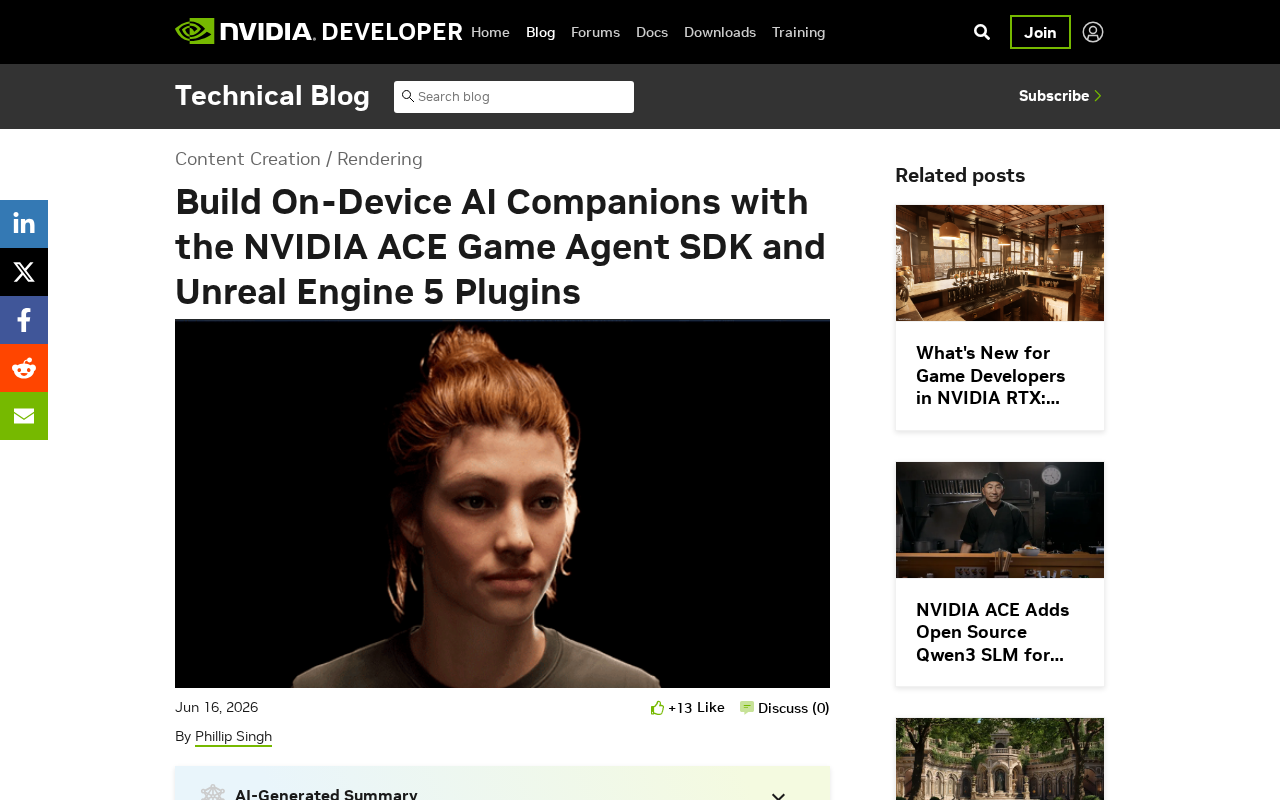
NVIDIA ACE SDK enables intelligent AI game companions through on-device inference integrated with Unreal Engine 5.
NVIDIA's ACE Game Agent SDK integrates with Unreal Engine 5 to enable intelligent AI NPCs running entirely on local GPUs. The solution features a multimodal AI pipeline covering speech recognition, LLM inference, text-to-speech, and facial animation, all optimized via TensorRT for real-time performance. This on-device approach delivers low latency, privacy protection, and offline capability, marking a paradigm shift from script-driven NPCs to dynamic AI-powered game companions.
The New Era of AI NPCs: From Script-Driven to Intelligent Interaction
NVIDIA recently released a deep integration solution combining the ACE (Avatar Cloud Engine) Game Agent SDK with an Unreal Engine 5 plugin, enabling game developers to build AI game companions with intelligent dialogue and behavioral capabilities running directly on players' local devices. This marks a critical step in game AI's evolution from traditional script-driven approaches to truly intelligent interaction.
For a long time, NPCs (Non-Player Characters) in games have relied on preset dialogue trees and behavior scripts, limiting player interaction to the finite paths pre-written by developers. The Dialogue Tree is an NPC interaction design pattern that the game industry has used for decades. It's essentially a directed graph structure where each node represents a line of NPC dialogue and each edge represents a player choice. Classic RPGs like the Baldur's Gate series and The Witcher 3 all use this approach—The Witcher 3 reportedly contains over 450,000 dialogue options. The advantage of this method is that content is fully controllable and quality is guaranteed, but the cost is enormous human effort and limited interaction flexibility—players can only choose from preset options and cannot truly express themselves freely. The emergence of NVIDIA ACE SDK is fundamentally changing this paradigm—AI-driven characters can understand context, engage in natural language dialogue, and respond dynamically based on game situations.
Core Capabilities of NVIDIA ACE SDK
On-Device AI Inference: Privacy and Performance Combined
One of the biggest highlights of the ACE Game Agent SDK is its support for On-Device AI Inference. This means the AI companion's language understanding, dialogue generation, and behavioral decision-making all happen on the player's local GPU, without needing to upload data to cloud servers.
On-Device AI Inference is a deployment paradigm contrasting with cloud-based inference. Traditional AI applications typically send computational tasks to GPU clusters in remote data centers for processing, while on-device inference deploys models directly on user terminal devices. The rise of this trend is driven by the rapid improvement in consumer-grade GPU computing power—NVIDIA RTX 40 series graphics cards equipped with fourth-generation Tensor Cores can deliver up to 1321 TOPS of AI computing power, sufficient to support real-time inference for language models with billions of parameters. Tensor Cores are hardware acceleration units specifically designed by NVIDIA for matrix operations, capable of executing the matrix multiplication and accumulation operations at the core of deep learning with extremely high throughput—precisely where the computational bottleneck of large language model inference lies.
This architecture brings multiple advantages:
- Low-latency response: Eliminates network round-trip latency, making AI character reactions more immediate and natural
- Privacy protection: Player dialogue content and gameplay behavior data never leave the local device
- Offline availability: AI companions continue to function normally even without network connectivity
- Cost advantage: Developers don't need to bear ongoing cloud inference costs
On-device inference has certain hardware requirements, and NVIDIA RTX series graphics cards' Tensor Cores provide powerful computing support for this, ensuring AI models run efficiently locally. It's worth noting that model compression technology is a key enabler for deploying large language models on consumer devices. Mainstream compression methods include quantization (reducing model weights from FP32 to INT8/INT4), knowledge distillation (using large models to guide training of smaller models), pruning (removing redundant parameters), and more. Taking quantization as an example, a 7-billion parameter model requires approximately 14GB of VRAM at FP16 precision, but through 4-bit quantization it can be compressed to approximately 4GB, enabling it to run on mainstream RTX graphics cards. NVIDIA's TensorRT-LLM framework is specifically optimized for LLM inference, supporting various quantization schemes and attention mechanism optimizations (such as FlashAttention), serving as the core technical foundation for ACE SDK's on-device deployment.
Deep Integration with Unreal Engine 5
NVIDIA RTX technology has already been deeply integrated into UE5 through the NVIDIA RTX Branch of Unreal Engine and the NVIDIA DLSS Unreal Engine plugin. DLSS (Deep Learning Super Sampling) is NVIDIA's AI-powered image super-resolution reconstruction technology that renders frames at lower resolution and then uses an AI model to upscale them to high resolution, significantly boosting frame rates while maintaining visual quality. The important significance of this technology is that it frees up GPU rendering headroom, allowing that computing power to be reallocated to AI inference tasks. In other words, DLSS indirectly creates computational resources for on-device AI characters to run, forming a synergistic technology ecosystem—AI is used both to enhance visual quality and to drive intelligent characters.
The ACE Game Agent SDK further extends this foundation, providing developers with a complete AI character development toolchain.
Developers can perform the following operations directly in the editor through the UE5 plugin:
- Configure AI character personality traits and backstories
- Define character knowledge scope and behavioral boundaries
- Set dialogue trigger conditions and context management rules
- Seamlessly connect AI behavior with game logic (such as quest systems, combat systems)
This native integration significantly lowers the development barrier, allowing game designers to create intelligent NPC characters with rich personalities without needing to deeply understand the technical details of underlying AI models.
Technical Architecture Analysis: Multimodal AI Pipeline and Behavior Framework
Multimodal AI Processing Pipeline
The ACE SDK constructs a complete multimodal AI processing pipeline covering the core capability modules required for intelligent characters. Multimodal AI refers to AI systems capable of simultaneously processing and understanding multiple forms of information (such as text, speech, images, and video). In the game AI character scenario, a multimodal pipeline needs to chain together multiple independent AI models—speech recognition, natural language processing, speech synthesis, and facial animation—into a low-latency processing pipeline. This end-to-end pipeline design is extremely challenging from an engineering perspective, as each stage has a strict latency budget—humans typically tolerate dialogue response delays of 200-500 milliseconds, beyond which the interaction feels unnatural.
Specifically, this pipeline contains the following core modules:
- Automatic Speech Recognition (ASR): Converts player voice input to text in real-time
- Natural Language Understanding (NLU): Parses player intent and performs semantic understanding combined with game context
- Large Language Model Inference (LLM): Generates appropriate responses based on character settings and dialogue history
- Text-to-Speech (TTS): Converts generated text into voice output with character-specific vocal qualities
- Facial Animation Driving: Drives character facial expressions and lip-sync based on speech and emotional information
The entire pipeline runs collaboratively on the local GPU, achieving efficient execution through the NVIDIA TensorRT optimized inference engine, ensuring all AI computation tasks are completed without significantly impacting game frame rates. TensorRT is NVIDIA's high-performance deep learning inference optimizer and runtime library that converts trained AI models into inference engines highly optimized for specific GPU hardware through techniques such as Layer Fusion, Precision Calibration, and Kernel Auto-Tuning. In gaming scenarios, TensorRT can reduce model inference latency by several times while significantly reducing VRAM usage. For example, through FP16 or INT8 quantization, model size and computation can be halved or more, with almost negligible precision loss. This is crucial for scenarios that need to run AI inference simultaneously with game rendering—the GPU must handle both graphics rendering and AI computation workloads.
Character Behavior Decision Framework
Beyond dialogue capabilities, the ACE SDK also provides a behavior decision framework. AI characters can not only "speak" but also "act"—triggering corresponding game behaviors based on dialogue content and game state, such as following the player, pointing to target locations, performing combat assistance, and other actions.
This design that connects language understanding with game behavior makes AI companions a truly organic part of the game experience, rather than an isolated chatbot. From a technical implementation perspective, this requires adding structured action command parsing at the LLM's output layer—the model not only generates natural language responses but simultaneously outputs behavioral commands executable by the game engine (similar to a Function Calling mechanism), which are received by UE5's behavior tree or state machine system to execute the corresponding game logic.
Impact and Challenges for the Game Industry
Transformation of Development Paradigms
In traditional game development, designing NPC dialogue and behavior is an extremely time-consuming task. A AAA-level RPG game might contain hundreds of thousands of lines of dialogue text, each requiring manual writing by scriptwriters. AI-driven character systems promise to transform this "exhaustive" design approach into a "rule-based" one—developers define character personality, knowledge, and behavioral boundaries, while specific dialogue content is generated by AI in real-time.
This not only significantly reduces content production costs but more importantly enables unprecedented interaction freedom. Every player's conversation with an AI character could be a unique experience.
Real-World Challenges in Implementation
This technology also faces several issues that need to be addressed in practical applications:
- Content controllability: How to ensure AI-generated dialogue always conforms to the game world's lore and narrative design. This involves character constraint design in Prompt Engineering, output filtering mechanisms, and rule-based safety Guardrails, requiring a balance between creativity and controllability
- Hardware threshold: On-device inference has high GPU performance requirements, potentially limiting the audience. Current mainstream on-device LLM inference requires at least an RTX graphics card with 8GB or more VRAM, meaning a significant portion of players using mid-to-low-end hardware may not be able to enjoy the full AI character experience
- Quality consistency: Quality fluctuations in AI-generated content may affect the stability of player experience. Large language model outputs have inherent randomness (controlled by sampling parameters like temperature), and the same question may receive answers of varying quality—a particular concern in games that emphasize narrative experience
- Multilingual localization: Multilingual support in on-device deployment scenarios requires balancing model size and inference performance. Supporting multiple languages typically means larger vocabularies and model parameters, which inherently conflicts with the lightweight goals of on-device deployment
Summary and Outlook
The integration of NVIDIA ACE Game Agent SDK with UE5 represents an important direction in game AI development: bringing large language model capabilities down to terminal devices, giving every player a truly intelligent game companion.
As RTX series GPU computing power continues to improve and model compression technology advances, on-device AI characters will become increasingly expressive. It's foreseeable that natural, deep interaction with AI NPCs will gradually become a standard part of the gaming experience, rather than exclusive to a few technical demonstrations. From a broader perspective, this is also a concrete manifestation in the gaming domain of the entire AI industry's macro trend of migrating from the cloud to edge and terminal devices—when AI capabilities truly reach every terminal device, the interactive experiences they can create will far exceed what we can imagine today.
For game developers, now is an excellent time to begin exploring and experimenting with this technology. The complete toolchain and UE5 plugin provided by NVIDIA significantly lower the entry barrier and are well worth close attention and experimentation.
Key Takeaways
Related articles

Sakana AI Releases Fugu Ultra: How Model Orchestration Achieves Frontier AI Performance
Sakana AI releases Fugu Ultra, achieving frontier AI performance through autonomous model orchestration. Deep dive into its technology, strategic implications, and impact on global AI competition.

Illusion Code In-Depth Review: 34+ Tools and 7 Agents Working in Harmony as an AI Coding Assistant
In-depth review of Illusion Code CLI AI coding assistant: 34+ core tools, 7 specialized Agents, three permission modes, and Chinese ecosystem support, compared with Claude Code, Codex, and OpenCode.
AI Scientist: A Deep Dive into Sakana AI's Automated Research Framework
Deep dive into Sakana AI's open-source AI Scientist project: how LLMs automate the full research pipeline from hypothesis generation and experiment execution to paper writing, including architecture, workflow, and limitations.