#TensorRT
20 related articles
·3 min
NVIDIA ACE SDK: On-Device AI Inference for Intelligent Game NPC Companions
Deep dive into NVIDIA ACE Game Agent SDK's integration with Unreal Engine 5, exploring how on-device AI inference enables low-latency, privacy-safe intelligent NPC dialogue and behavior.
Read more →
·3 min
DAQIRI Platform Explained: Deep Integration of High-Speed Data Acquisition and Real-Time AI Inference
Deep dive into how the DAQIRI platform embeds NVIDIA GPU-accelerated computing into high-speed data acquisition pipelines, enabling real-time AI inference for industrial inspection, scientific experiments, and autonomous driving.
Read more →
·3 min
748-Episode AI Large Language Model Development Tutorial: Seven Core Modules from Zero to Project Deployment
Analysis of a 748-episode, 198-hour AI LLM development tutorial covering API integration, prompt engineering, RAG, AI Agents, fine-tuning, multimodal development, and deployment.
Read more →

·3 min
The Complete Skill Map for AI Application Engineers: A Progressive Roadmap from Fundamentals to Production
A systematic breakdown of the complete skill structure for AI application engineers, covering Python & deep learning fundamentals, small model engineering, LLM fine-tuning, Agent development, and enterprise projects.
Read more →
·2 min
Baseten Raises $1.5 Billion: Why AI Inference Infrastructure Has Become a Capital Darling
AI inference startup Baseten is raising $1.5B at a $130B valuation. We analyze why inference infrastructure is booming, the competitive landscape, and what this mega-round signals.
Read more →

·4 min
Local Deployment of Claude Code: Principles and Practical Guide for Three Approaches
A detailed guide to locally deploying Claude Code with three approaches (LM Studio, Ollama, vLLM), covering architecture, protocol translation, hardware selection, and model recommendations.
Read more →
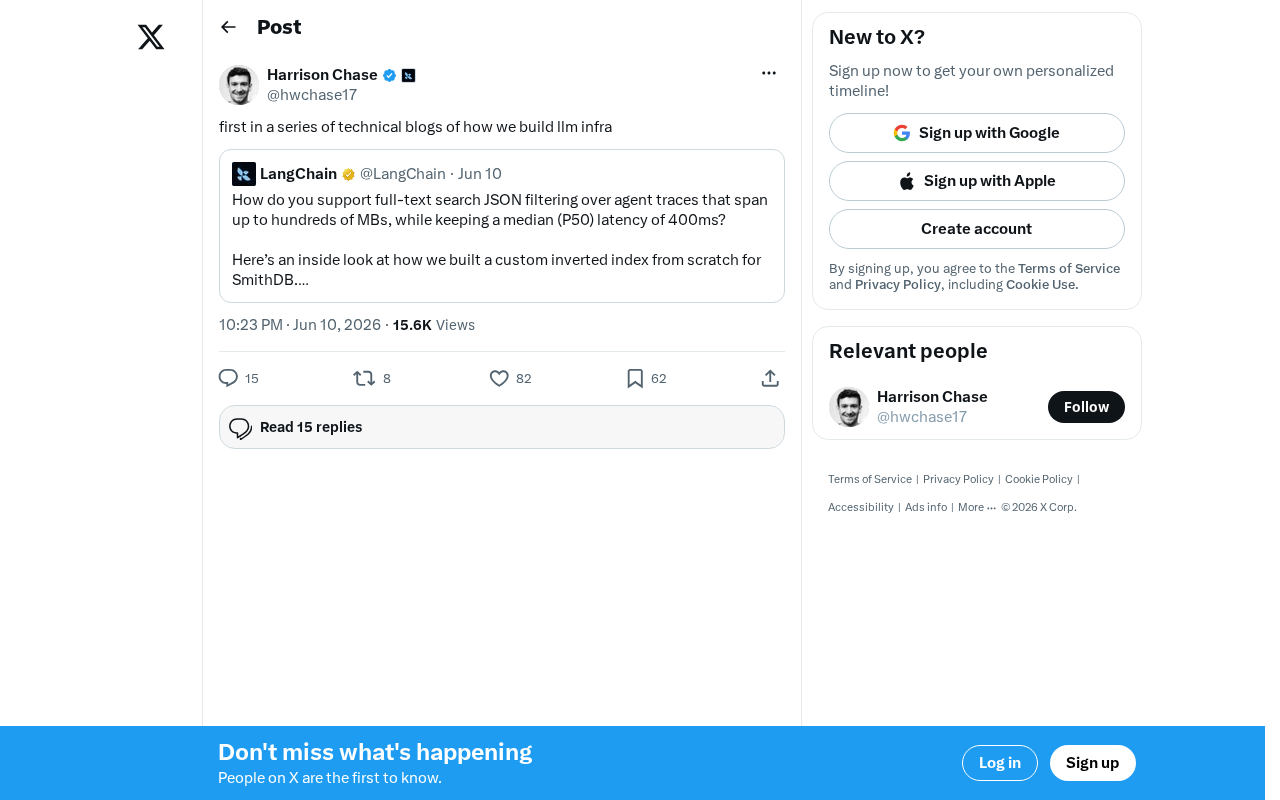
·2 min
A Complete Guide to LLM Infrastructure: Core Challenges from GPU Clusters to Inference Optimization
A deep dive into core challenges and key technologies for LLM infrastructure, covering GPU cluster management, inference optimization, distributed training, cost control, and observability.
Read more →

·4 min
AI Engineer Job Search: The Capability Leap from Demo to Production System
AI job demand is surging but companies can't find qualified candidates. Learn the 3 core skills—advanced RAG, local model deployment, and full-stack monitoring—to leap from demo builder to production engineer.
Read more →

·4 min
The Five-Tier Pyramid of IT Careers in the AI Era: Your Position Determines Your Career Ceiling
AI is reshaping IT careers into a five-tier pyramid from tool usage to self-developed models. Learn where you fit and how to maximize your career potential.
Read more →

·3 min
vLLM Deep Dive: How PagedAttention Enables High-Throughput LLM Inference
Deep dive into vLLM's core technologies for high-throughput LLM inference, including PagedAttention memory management, continuous batching, distributed deployment, and comparisons with TensorRT-LLM.
Read more →
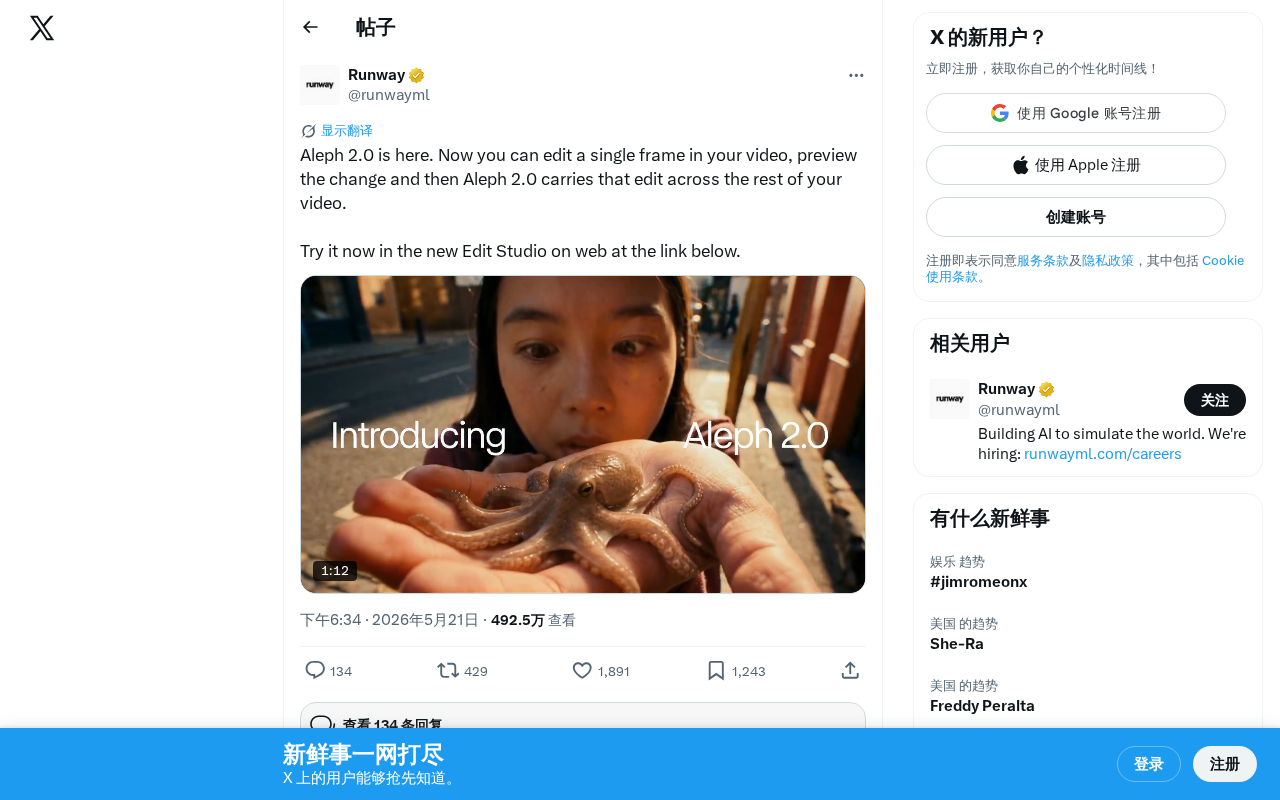
·2 min
Aleph 2.0 Deep Dive: Edit One Frame to Transform an Entire Video
Aleph 2.0 introduces single-frame edit propagation: modify one frame and automatically apply changes across the entire video. Deep dive into Edit Studio, temporal consistency breakthroughs, and industry impact.
Read more →
 Expert Opinions
Expert Opinions·3 min
Windsurf CEO Deep Dive Interview: Speed Is the Only Moat
Windsurf CEO Varun Mohan shares insights on AI coding IDE pivots, product methodology, async Agent challenges, and differentiation strategy vs Cursor. Speed is the only moat.
Read more →
 Deep Dives
Deep Dives·3 min
Why Is Python the Top Choice for AI Development? Three Core Reasons Explained in Depth
In-depth analysis of three core reasons Python dominates AI development: simple syntax for quick onboarding, powerful ecosystem, and industry-wide network effects.
Read more →
 Tutorials
Tutorials·1 min
AI Large Language Model Learning Roadmap: Six Stages from Zero to Engineer
A systematic LLM engineer learning roadmap covering Transformer basics, prompt engineering, RAG, Agent development, API integration, fine-tuning, deployment, and project practice across six stages.
Read more →
 Tech Frontiers
Tech Frontiers·1 min
Windsurf Integrates Claude Opus 4.7 Fast Mode with 2.5x Speed Boost
Windsurf integrates Claude Opus 4.7 fast mode with 2.5x speed boost while retaining full intelligence. Analysis of its impact on developer productivity and AI coding tool competition.
Read more →
 Industry Insights
Industry Insights·2 min
AMD MI355X Beats B200: Full-Stack Optimization Breakdown for 5% Lower TCO on DeepSeek-R1 Inference
AMD Instinct MI355X achieves 5% lower TCO than NVIDIA B200 on DeepSeek-R1 disaggregated inference via SGLang+MoRI full-stack optimization with 1.25x per-GPU throughput.
Read more →
 Tech Frontiers
Tech Frontiers·1 min
SGLang Hosts Agent Loops Office Hour, Focusing on Agentic Loop Architecture Optimization
SGLang team hosts an Agent Loops Office Hour exploring inference optimization for agentic loops, covering KV Cache reuse, low-latency multi-turn dialogue, and tool calling techniques.
Read more →
 Industry Insights
Industry Insights·2 min
NVIDIA Dynamo Snapshot: A Snapshot Recovery Solution for GPU Inference Cold Start Problems
Deep dive into how NVIDIA Dynamo Snapshot reduces LLM inference cold start time from minutes to seconds via GPU state snapshot and recovery, covering Kubernetes integration and elastic inference.
Read more →
 Industry Insights
Industry Insights·2 min
NVIDIA Blackwell Sets New STAC-AI Records for Financial LLM Inference
NVIDIA Blackwell GPU sets new LLM inference records in STAC-AI financial benchmark. Explore Blackwell architecture advantages, TensorRT-LLM co-optimization, and LLM applications in trading and risk management.
Read more →
 Product Reviews
Product Reviews·3 min
DLSS 4.5 Deep Integration with UE5 and Multilingual AI Characters: Major NVIDIA RTX Game Development Update
NVIDIA releases major RTX update with DLSS 4.5 deep UE5 integration for frame generation performance leaps and multilingual AI characters supporting dynamic dialogue with real-time speech synthesis.
Read more →