AI Engineer Job Search: The Capability Leap from Demo to Production System

Bridge the gap from calling APIs to building production-ready AI systems with three core competencies.
AI job demand is booming, yet companies struggle to find engineers who can build production systems—not just demos. This article breaks down the three essential competencies for AI engineers: advanced RAG with knowledge graphs and automated evaluation, local model deployment with quantization, inference acceleration, and LoRA fine-tuning, and full-stack operations monitoring including tracing, hallucination detection, and data drift management.
Introduction: The Supply-Demand Mismatch in AI Roles
A thought-provoking phenomenon is playing out in the AI industry: job demand has surged 143%, yet companies complain they "can't find people who can actually do the work." What's the root cause of this supply-demand mismatch? A Chinese tech content creator hit the nail on the head in his AI application development tutorial — companies aren't hiring people who can call models; they're hiring people who can turn models into systems.
This perspective deserves serious consideration from anyone looking to break into AI.

The Harsh Reality: Calling APIs ≠ Building AI
"Microwave Reheating" Level AI Skills
Many beginners have a superficial understanding of what an AI engineer does: call a few APIs, write a couple of prompts, follow tutorials to build Snake-game-level AI mini-projects. These skills today are like "applying for a chef position when all you can do is reheat food in a microwave" — nowhere near enough.
What's even more sobering is that using frameworks like LangChain or Dify to build a toy demo is something "a middle schooler with basic training could do." While that's a bit of an exaggeration, it does reflect a real trend: as AI tools become increasingly user-friendly, the value of low-barrier skills is depreciating rapidly.
It's worth understanding the background of these frameworks. LangChain is currently the most popular framework for building LLM applications, offering modular components like Chains, Agents, Memory, and Retrieval that let developers assemble LLM applications like building blocks. Dify is an open-source LLMOps platform with a visual workflow orchestration interface where users can build RAG applications and AI Agents through drag-and-drop, without even writing code. These frameworks have dramatically lowered the barrier to AI application development — but precisely because of this, merely knowing how to use them no longer constitutes a competitive advantage. Frameworks abstract away a massive amount of underlying detail, and when developers encounter performance bottlenecks, edge-case exceptions, or deep customization needs, those lacking foundational understanding are often left helpless.

What Do Companies Actually Need?
Companies want a high-concurrency, low-latency production system that doesn't hallucinate. Specifically, you need to be able to:
- Handle dirty data: Real-world data is far messier than the clean datasets in tutorials
- Optimize retrieval: Make RAG systems accurately find relevant information across massive document collections
- Suppress hallucinations: Ensure model outputs are reliable and don't fabricate facts
- Squeeze every drop of GPU performance: Accelerate inference and control costs
Getting a demo to run and building a production system are two entirely different capabilities. The former validates "can it run?" while the latter validates "can it actually be used?"
Three Core Competencies: The Hard Currency for Breaking into AI
AI engineers need to master three core competency areas. This isn't a simple tech checklist — it's a complete capability framework.
Advanced RAG: From Basic Retrieval to Knowledge Graphs

RAG (Retrieval-Augmented Generation) is one of the most critical technical approaches in current LLM applications, but "advanced RAG" goes far beyond basic vector retrieval.
To understand the value of advanced RAG, you first need to understand its technical background. RAG was first proposed by Meta AI in 2020. Its core idea is to retrieve relevant document fragments from an external knowledge base before the LLM generates an answer, injecting them as context into the prompt so the model generates responses based on real data. This paradigm effectively addresses two major pain points of LLMs: knowledge cutoff limitations and hallucination. The basic RAG pipeline is typically "document chunking → vectorization → store in vector database → vectorize user query → similarity search → concatenate context → model generation." However, this simple pipeline exposes numerous issues when facing complex enterprise scenarios — for example, improper chunk granularity causing semantic fragmentation, insufficient recall from a single retrieval method, and lack of re-ranking and filtering of retrieval results.
Enterprise-grade RAG systems require mastery of:
- Multi-path recall and hybrid retrieval: Combining vector search, keyword search, semantic search, and other methods to improve both recall and precision
- GraphRAG and knowledge graphs: Using graph structures to organize knowledge, addressing the shortcomings of traditional RAG in complex reasoning scenarios
- Automated evaluation frameworks: Establishing systematic evaluation processes to quantify both retrieval quality and generation quality
GraphRAG deserves special attention. GraphRAG is a novel RAG architecture open-sourced by Microsoft Research in 2024 that upgrades traditional "flat document retrieval" to "graph-structured knowledge retrieval." Its core process first uses LLMs to extract entities and relationships from documents to build a knowledge graph, then applies graph community detection algorithms (such as the Leiden algorithm) to perform hierarchical clustering of knowledge, generating community summaries at different granularities. At query time, the system can perform multi-hop reasoning over the graph structure, answering complex questions that require synthesizing information across documents and paragraphs. Compared to traditional RAG, which can only find "locally similar" text fragments, GraphRAG captures deep associations between entities, making it particularly suitable for scenarios requiring global understanding, such as legal compliance analysis, medical knowledge Q&A, and enterprise internal knowledge management.
The keyword here is "automated evaluation." Many people think the job is done once they've built a RAG system, but without an evaluation framework, you have no idea which scenarios will cause problems, let alone continuously optimize.
Local Small Model Deployment & Optimization: Balancing Cost and Performance
Not every scenario requires calling GPT-4-level large models. In many enterprise scenarios, locally deployed smaller models are actually the more pragmatic choice — controllable costs, data security, and lower latency. This area requires mastery of:
- Quantization techniques: Compressing models from FP16 to INT8 or even INT4, dramatically reducing VRAM usage
- Distillation and inference acceleration: Obtaining smaller, faster models through knowledge distillation, combined with tools like vLLM and TensorRT for inference acceleration
- LoRA fine-tuning: Adapting general models to specific business scenarios with minimal data and compute resources
Each of these three skills has deep technical substance worth exploring individually.
On quantization techniques: Model quantization converts neural network weights from high-precision floating-point numbers (such as FP32 or FP16) to low-precision integers (such as INT8 or INT4). Take a 7B parameter model as an example — at FP16 precision it requires about 14GB of VRAM, but quantized to INT4 it needs only about 3.5GB, runnable on a consumer-grade GPU. Mainstream quantization methods include GPTQ (post-training quantization based on layer-wise optimal quantization), AWQ (Activation-aware Weight Quantization, which allocates quantization precision based on activation value importance), and GGUF (the quantization format in the llama.cpp ecosystem, supporting CPU+GPU hybrid inference). Quantization inevitably introduces some precision loss, but modern quantization algorithms, through carefully designed calibration strategies, can keep INT4 quantization performance loss within 1-3% — virtually imperceptible in most application scenarios.
On inference acceleration: vLLM is a high-performance LLM inference engine developed by the UC Berkeley team. Its core innovation is the PagedAttention mechanism — borrowing the paged memory management concept from operating system virtual memory, it divides the KV Cache into fixed-size blocks for dynamic allocation, solving the VRAM waste caused by KV Cache memory fragmentation in traditional inference frameworks. In actual benchmarks, vLLM's throughput can reach 8-24x that of native HuggingFace Transformers inference. TensorRT-LLM is NVIDIA's inference optimization tool that fully leverages GPU Tensor Core compute through operator fusion, quantization-aware inference, In-flight Batching, and other techniques. In production environments, inference acceleration directly impacts service costs — for the same QPS (queries per second) requirement, optimized systems may need only 1/5 of the original GPU resources.
On LoRA fine-tuning: LoRA (Low-Rank Adaptation), proposed by Microsoft in 2021, is currently the most popular parameter-efficient fine-tuning method. Its core idea is based on a key hypothesis: the weight change matrix when adapting to downstream tasks is low-rank. Therefore, instead of directly modifying original model weights, LoRA inserts two small matrices (a down-projection matrix A and an up-projection matrix B) alongside the attention matrices in each Transformer layer, updating only these small matrices during training. For a 7B model, full fine-tuning requires updating 7 billion parameters, while LoRA typically updates only a few million parameters (less than 1% of the original), reducing training VRAM requirements from hundreds of GB to tens of GB. QLoRA goes further by quantizing the base model to 4-bit before applying LoRA fine-tuning, making it possible to fine-tune large models on a single consumer GPU with 24GB of VRAM.
The combination of these three skills essentially answers one question: How do you achieve model performance that meets business requirements at the lowest possible cost?
Full-Stack Operations & Monitoring: Keeping AI Systems Running Reliably
This is the most easily overlooked yet most critical capability in production environments. Once an AI system goes live, you need:
- Distributed tracing: When the system has issues, quickly pinpoint whether the problem is in the retrieval stage, model inference stage, or post-processing stage
- Metrics visualization: Real-time monitoring of key metrics like response time, throughput, and accuracy
- Hallucination assessment: Continuously monitoring the reliability of model outputs and detecting upward trends in hallucination rates
- Alerting: Notifying relevant personnel immediately when system anomalies occur
This capability set corresponds to the DevOps mindset in traditional software engineering, except that in AI systems, you also need to pay attention to model-specific issues like hallucinations, data drift, and model degradation.
Data drift and model degradation deserve special explanation, as they represent the core challenges that distinguish AI system operations from traditional software operations. Data drift refers to the distribution of input data in production environments shifting over time, deviating from the data distribution the model was trained on. For example, a customer service Q&A model trained on 2023 data might face a flood of questions about new products in 2024, causing answer quality to decline. Model degradation is a broader concept that, beyond data drift, includes factors like upstream dependency changes (e.g., an Embedding model update causing vector space inconsistency), outdated knowledge bases, and shifts in user behavior patterns. In traditional ML systems, data drift detection already has mature solutions (such as PSI and KL divergence monitoring), but in LLM systems, since inputs are unstructured natural language, drift detection is more complex and typically requires combining semantic clustering analysis with output quality score trend monitoring. Understanding these concepts is essential for building a truly effective AI system monitoring framework.
Recommended Learning Path: From Mindset to Practice
Start with the Right Mindset
Before diving into specific technologies, the most important thing is to establish the right cognitive framework. An AI engineer is not "someone who can use AI tools" but "an engineer who can build AI systems." This means you need to simultaneously develop:
- AI technical skills: Understanding model principles and mastering core techniques like RAG and fine-tuning
- Engineering skills: Knowing how to turn technical solutions into reliable production systems
- Systems thinking: Being able to design and optimize the entire AI application pipeline from a holistic perspective
Drive Learning Through Projects
Learning individual technical topics in isolation has limited effectiveness. A better approach is to use an end-to-end project as your main thread, connecting all knowledge points through practice. For example, build an enterprise-grade knowledge Q&A system from scratch, going through the entire pipeline from data processing, retrieval optimization, and model deployment to monitoring and operations.
Focus on Production-Grade Details
During your learning journey, pay special attention to the "dirty work" that tutorials typically don't cover: exception handling, edge cases, performance tuning, and cost control. These are what truly distinguish a "demo builder" from a "production-ready engineer."
Conclusion
The logic behind AI hiring has fundamentally changed: it's not about certificates or scattered tutorials — it's about whether you can build an end-to-end production system from scratch. Advanced RAG, model deployment optimization, and full-stack operations monitoring — these three core competencies form the hard skills of an AI engineer.
For those looking to break into the field, rather than spending time collecting various "complete tutorial packages" and "learning resources," it's better to first think clearly about one question: after you finish learning, can you independently build an AI system that runs reliably in a real business environment? If the answer is no, it's time to reassess your learning path.
Related articles

A Gen-Z Woman Making $1.5M/Month: Deconstructing the Growth Methodology Behind AI Apps
Gen-Z indie dev Nicole built 4 hit AI apps earning $1.5M/mo. Deep dive into her industrialized UGC engine, traffic testing system, and minimalist tech stack.
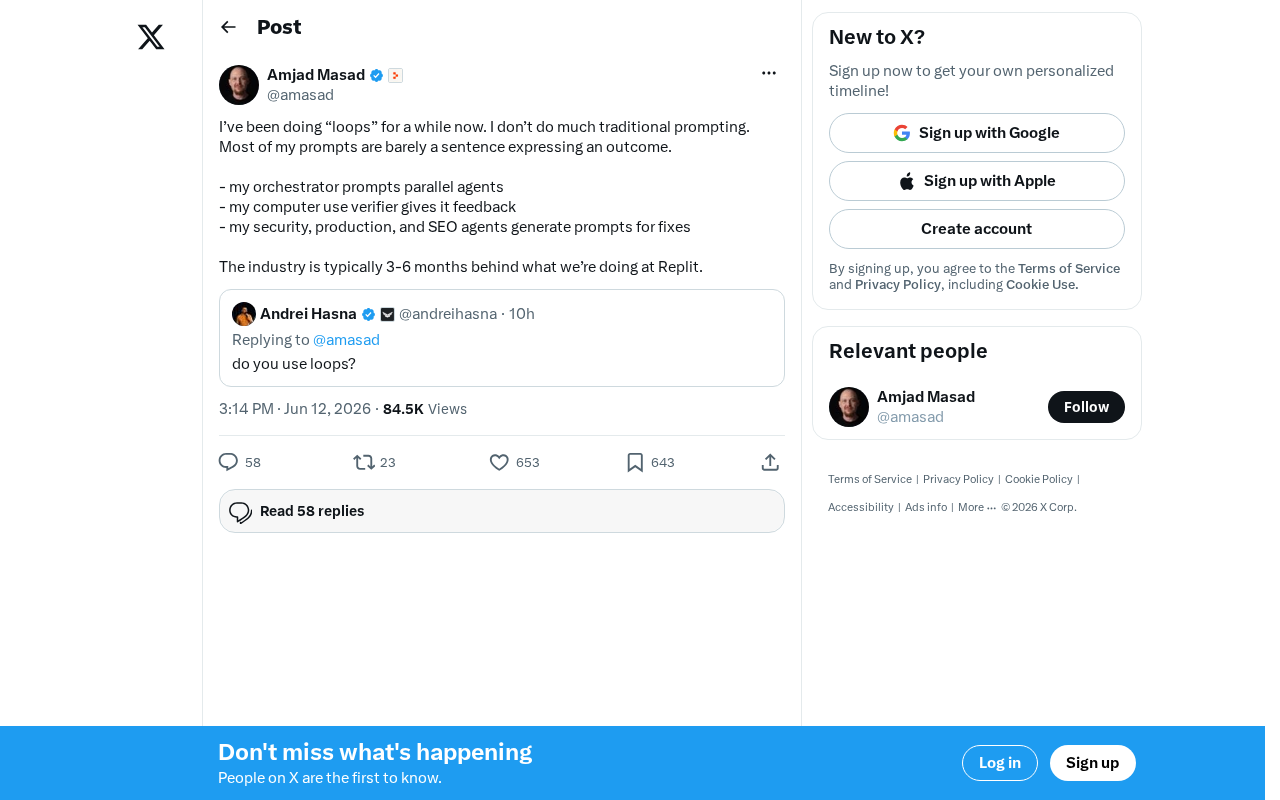
Replit's AI Loops Workflow Explained: Multi-Agent Collaboration Replaces Prompt Engineering
Deep dive into Replit's AI Loops workflow: how orchestrators, parallel agents, and Computer Use Verifiers build automated closed-loop systems through multi-agent collaboration.
Claude Code + Skills: A Practical Guide to AI-Powered Test Case Generation
Learn how to use Claude Code + Skills to auto-generate enterprise-grade test cases. Covers AI Agent vs LLM differences, the four core capabilities, and the complete workflow from requirements to test cases.