Claude Code + Skills: A Practical Guide to AI-Powered Test Case Generation
A practical guide to generating enterprise-level test cases using Claude Code + Skills as an AI Agent.
This guide explains how Claude Code + Skills can automatically generate enterprise-grade test cases, far surpassing what traditional LLMs produce. It covers the key differences between AI Agents and LLMs, introduces the four core Agent capabilities (perception, decision-making, action, memory), compares mainstream AI coding tools, and provides a complete workflow from requirements analysis to iterative test case generation.
The Limitations of Traditional AI Test Case Generation
When faced with a complete requirements document, many test engineers instinctively open DeepSeek or ChatGPT, paste in the document, and type something like "Please generate functional test cases based on this requirements document."
Take a typical e-commerce project as an example. The requirements document covers front-end features (product homepage, product categories, product search, product details, user registration, user login, password recovery, shipping addresses, shopping cart, order placement, order after-sales, payment methods, etc.) and back-end features (dashboard, permission management, system settings, product management, order management, user management, etc.). This is a very common requirements document structure in enterprise settings.
However, what LLMs generate directly is usually nothing more than a "demo-level" output — 8 test cases for user registration, 7 for user login, 8 for product search… For a project of this scale, the quantity and quality of these test cases fall far short of what's needed. Even with manual intervention and revisions, it's difficult to meet enterprise-level testing requirements.
There are several deeper reasons behind this. First, there's the context window limitation: even though mainstream LLMs now support 128K or even longer context windows, when processing a requirements document that runs tens of thousands of words, the model's attention to detail drops significantly as text length increases. This phenomenon is known in academia as the "Lost in the Middle" problem — models tend to focus on the beginning and end of input text while overlooking critical information in the middle. Second, LLMs lack the systematic application of professional testing methodologies. A qualified test engineer designing test cases will comprehensively apply multiple test design techniques such as equivalence partitioning, boundary value analysis, decision tables, cause-effect graphing, orthogonal array testing, scenario-based testing, and error guessing. In a single conversation, LLMs typically only cover the most basic positive and negative scenarios, lacking deep exploration of boundary conditions, exception flows, and combinatorial scenarios. Take "user registration" as an example: a complete set of test cases for an enterprise-level project typically needs to cover 30–50 or more scenarios (including boundary values for each field, special character handling, concurrent registration, API security, etc.), and the 8 cases generated by an LLM are clearly just the tip of the iceberg.
The Core Difference Between AI Agents and LLMs
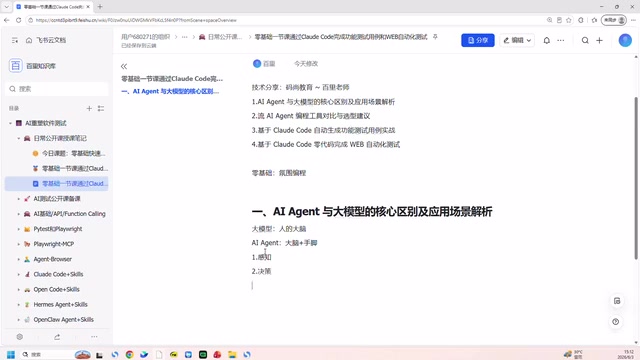
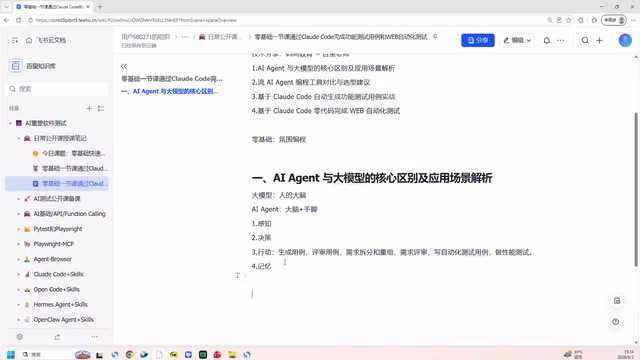
To understand why Claude Code can achieve better test case generation, you first need to understand the fundamental difference between AI Agents and LLMs.
LLMs: A Brain Without Hands or Feet
An LLM can be compared to a human brain — it knows everything and understands everything; you can ask it any question. But the problem is that this "person" only has a brain, with no hands or feet. The only thing you can do with it is have a conversation: you say something, it responds, and that's it.
From a technical perspective, an LLM is essentially a text generation model based on the Transformer architecture. It works by predicting and generating the next token one at a time based on the input prompt. Whether it's GPT-4, Claude, or DeepSeek, their core capabilities are all bounded within the "text in → text out" framework. This means LLMs cannot proactively read your project files, execute system commands, access external tools, or dynamically adjust their next steps based on execution results. Each conversation is an independent, stateless interaction.
AI Agents: A Complete Person
AI Agents are different — they are the brain plus hands and feet, a complete person. In functional testing scenarios, they possess four core capabilities:
- Perception: Able to understand what you want to accomplish and comprehend the project context
- Decision-making: No need for step-by-step guidance — they can determine what to do on their own
- Action: Can directly execute operations — generating test cases, reviewing test cases, decomposing and reorganizing requirements, writing automation scripts, running performance tests, etc.
- Memory: Knows what you've done before, understands the project's iteration history, and can perform incremental work based on historical context
AI Agents are typically built on the ReAct (Reasoning + Acting) framework, an architectural pattern that allows LLMs to alternate between "thinking" and "acting" during the reasoning process. Specifically, after receiving a task, the Agent first performs reasoning analysis to determine which tools to call or which operations to execute, then actually performs those operations (Acting), and then conducts the next round of reasoning based on the execution results — repeating this cycle until the task is complete. During this process, the Agent can invoke multiple external tools (Tool Use) such as file read/write, command-line execution, code interpreters, and web search, forming a complete "perception-decision-execution-feedback" loop. This is fundamentally different from an LLM's single-pass text generation.
This means AI Agents' capabilities far exceed those of simple LLM conversations. They don't just "answer questions" — they can proactively complete an entire workflow.
Comparing Mainstream AI Coding Tools
There are many AI Agent editors (AI Editors) available on the market today, including:
- Claude Code: A command-line AI coding tool from Anthropic
- Cursor: A code editor with integrated AI capabilities
- Codex: OpenAI's coding assistant tool
- Open Code: An open-source AI coding solution
- Gemini Code: Google's AI coding assistant
Although these tools are all categorized as "AI coding tools," their architectural designs and interaction patterns differ significantly. Claude Code uses a Terminal-Native interaction approach, running directly in the command-line environment without a graphical IDE interface. This design may seem "bare-bones," but it actually provides tremendous flexibility — it can directly access the project's complete file system, execute arbitrary Shell commands, use Git for version control, and even run test scripts and analyze execution results. In contrast, tools like Cursor use an IDE-integrated model, embedding AI capabilities into the editor's graphical interface, making them better suited for everyday code writing and completion. OpenAI's Codex emphasizes asynchronous multi-task processing, capable of launching multiple Agent instances to handle different tasks in parallel, making it suitable for scenarios requiring large-scale parallel development.
Tool Selection Recommendations for Different Scenarios
The right tool depends on the specific use case:
| Scenario | Recommended Tool | Reason |
|---|---|---|
| Deep development on large projects | Claude Code | Strong context understanding, suitable for complex projects |
| Multi-Agent parallel development | Codex | Supports multi-task parallel processing |
| High data privacy requirements | Local deployment solutions | Data stays in the local environment |
| Long-term evolving AI assistant | Agents with memory support | Can continuously learn project knowledge |
Interestingly, Claude Code can also be used in China — although its default commercial LLM may have access restrictions, you can connect it to domestic LLMs as a substitute to achieve the same Agent capabilities. The specific technical approach involves modifying Claude Code's API endpoint configuration to point its underlying model calls to domestic LLM services compatible with the OpenAI API format (such as DeepSeek, Qwen, GLM, etc.). Since Claude Code's Agent framework is decoupled from the underlying model, as long as the replacement model provides sufficient reasoning capability and Function Calling support, you can retain the complete Agent workflow while bypassing network access restrictions.
The Paradigm Shift from Traditional Approaches to AI Agents
Over the past year or two, the typical learning path for test automation has been: learn a programming language → write scripts step by step → encapsulate frameworks → package into tools. This is a process that requires substantial programming fundamentals.
Looking back at the evolution of test automation, we can clearly see several stages of progression. Phase 1 (2000s) was the record-and-playback era, represented by QTP (now UFT) and Selenium IDE, where testers generated scripts by recording operation steps — low barrier to entry but extremely high maintenance costs. Phase 2 (2010s) was the keyword-driven and data-driven era, where test teams began building automation frameworks, separating test data from test logic, and introducing design patterns like Page Object — but this placed high demands on testers' programming skills. Phase 3 (early 2020s) saw the rise of low-code/no-code testing platforms, with tools like Katalon and TestSigma attempting to lower the automation barrier, but still falling short in flexibility and complex scenario coverage. Now, we are entering Phase 4 — the era of AI Agent-driven intelligent testing.
Today, testing work in enterprises is undergoing a paradigm shift:
- Before: Manual writing → manual encapsulation → gradually building an automation system
- Now: AI Agent + editor + LLM integration → fully automated generation
The key shift is that we no longer need testers to have deep programming skills. The Claude Code + Skills combination achieves "zero technical barrier" — you don't need to know how to code; the AI Agent handles the entire process from requirements analysis to test case generation.
This paradigm shift is also profoundly affecting the organizational structure of testing teams. Traditional test teams are usually divided into two tiers: manual test engineers and automation test engineers, with the latter enjoying higher salaries and job levels because of their programming skills. In the AI Agent era, this stratification is being dismantled — a tester's core value is no longer reflected in "whether they can write Selenium scripts" but in their depth of business understanding, ability to formulate test strategies, and efficiency in leveraging AI tools. A manual test engineer with deep business knowledge, armed with Claude Code, may produce higher-quality test outcomes than an automation engineer who can write scripts but doesn't understand the business.
The Right Process for AI-Powered Test Case Generation
When you receive a requirements document, the right approach isn't to simply toss the document to the AI and ask it to "generate test cases." Instead, you should follow a systematic process:
Step 1: Requirements Understanding and Feature Mapping
Whether done manually or by AI, the first step is always to thoroughly understand all features. The advantage of an AI Agent is that it can automatically parse requirements documents, identify all functional modules and their relationships, rather than viewing each feature in isolation.
In practice, Claude Code first traverses the requirements documents in the project directory (supporting Markdown, Word, PDF, and other formats), extracts a tree structure of functional modules through semantic analysis, and automatically identifies dependencies between modules. For example, it can understand that the "place order" feature depends on "shopping cart" and "shipping address," and that "order after-sales" depends on the completion of "place order" and "payment." This automatic construction of a feature dependency graph is something traditional LLM conversations cannot achieve — because it requires the Agent to proactively read multiple files, cross-reference information, and maintain a structured knowledge representation in memory.
Step 2: Building a Testing Knowledge Base with Skills
Claude Code's Skills feature allows you to preset testing standards, test case templates, quality criteria, and more. This is essentially injecting "expert tester experience" into the AI Agent, so the generated test cases are no longer generic demos but professional cases that meet enterprise standards.
From a technical implementation perspective, the core carrier of Skills is the CLAUDE.md configuration file in the project root directory (along with local configuration files in subdirectories). This file is written in Markdown format, and Claude Code automatically reads it at startup, injecting it as system-level context into the Agent's workflow. In test case generation scenarios, you can define the following in CLAUDE.md: standard test case format templates (including fields like case ID, priority, preconditions, test steps, expected results, actual results, etc.), rules for applying test design techniques (e.g., "each input field must cover equivalence partitioning and boundary value analysis"), domain-specific business rules (e.g., "amount fields must be tested for decimal precision, negative numbers, zero values, and maximum values"), and quality checklists for test case review. These preset Skills essentially make the tacit knowledge of senior test experts explicit and structured, enabling the AI Agent to automatically follow these standards when generating every test case.
Step 3: Iterative Optimization and Memory Accumulation
Leveraging the AI Agent's memory capability, test cases generated in each iteration are optimized based on previous feedback. The longer a project runs, the deeper the AI's understanding of the business becomes, and the higher the quality of generated test cases.
Claude Code's memory mechanism operates on two levels. Short-term memory is reflected in context retention within a single session — the Agent remembers all modification suggestions and preference settings you've made during the current session, ensuring consistency in subsequently generated test cases. Long-term memory is persisted through the CLAUDE.md file and the project file system — the Agent can write testing patterns discovered during the current iteration, business rules identified, and user feedback preferences into configuration files, automatically loading them at the next startup. This forms a continuous improvement feedback loop: generate test cases → manual review → feedback issues → Agent learns and updates Skills → generate higher-quality test cases next time. As project iterations progress, this knowledge base becomes increasingly rich, and the AI Agent's understanding of the business deepens from "generalized awareness" to "domain expert-level cognition."
Conclusion
AI test case generation is evolving from "conversational Q&A" to a new phase of "autonomous Agent execution." The Claude Code + Skills combination, through its four core capabilities of perception, decision-making, action, and memory, transforms test case generation from a process requiring extensive manual intervention into an efficient workflow led by AI with human review. For test engineers, the core competitive advantage is shifting from "knowing how to code" to "knowing how to harness AI Agents."
It's worth noting that this doesn't mean test engineers will be replaced by AI. Quite the opposite — the introduction of AI Agents frees test engineers from repetitive test case writing, allowing them to devote more energy to test strategy formulation, exploratory testing, user experience evaluation, and other high-value work that demands greater creativity and judgment. Human-AI collaboration, not human-AI replacement, is the right approach to test engineering in the AI Agent era.
Related articles

Claude Code with Local LLMs: Token-Free Deployment Guide & Configuration
Learn how to connect Claude Code to local LLMs for token-free AI coding. Covers three-layer architecture, Ollama/LM Studio/vLLM setup, protocol translation, and hardware selection.
Inventory-Free Game Design and Godot Sprite Occlusion Sorting: A Practical Tutorial
Explore inventory-free game design with mouse-drag interactions. Learn Godot sprite occlusion sorting pitfalls and solutions, plus AI-generated shader tips.
The Vibe Coding Flow State: When AI Coding Speed Outpaces Creative Output
A developer shares a zero-frustration Vibe Coding experience using Fable and Replit. Explore how AI coding tools are shifting the bottleneck from execution to creativity.