One BaseURL to Access All AI Models: A Deep Dive into API Aggregation

How API aggregation platforms unify access to all major AI models through a single BaseURL.
This article explores how API aggregation platforms like NovrAPI solve multi-model management challenges by providing a unified BaseURL to access Claude, OpenAI, Gemini, and other AI models. It covers the technical architecture including API gateway patterns and protocol adapters, intelligent routing with automatic failover, team collaboration features like token tracking and cost monitoring, and key considerations around latency, data compliance, and cost-effectiveness.
The Pain Points of Multi-Model Development
With the explosive growth of AI programming tools, developers now have more model choices than ever — Claude Code, OpenAI Codex, Gemini — each with its own strengths. But real-world problems come with the territory: each model has its own interface, API key, and billing system, and management overhead skyrockets.
Even more frustrating are the stability issues. Rate limiting during peak hours, unexpected API outages, response interruptions — none of these are trivial in production projects. For team development especially, a single API outage can bring an entire CI/CD pipeline to a halt. CI/CD (Continuous Integration/Continuous Deployment) is a core practice in modern software engineering, referring to the fully automated pipeline from code commit through testing, building, and deployment. When AI programming tools are integrated into CI/CD workflows — for example, automatically calling Claude for code review before merging, or using Codex to generate unit tests before deployment — API availability directly determines whether the entire pipeline runs smoothly. A single API outage doesn't just mean the current task fails; it can trigger pipeline blockages that cause all subsequent code changes to queue up, and in large teams, this cascading effect can be especially severe.
The Core Idea Behind API Aggregation Platforms
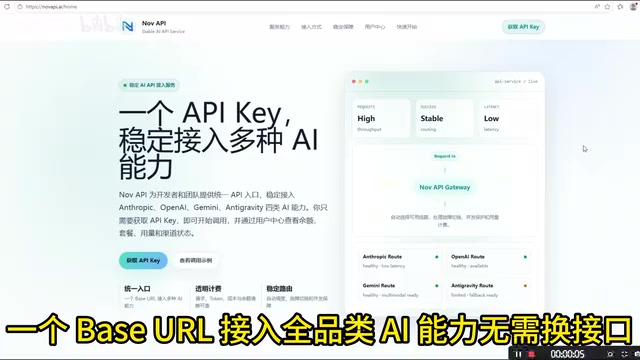
To address these pain points, API aggregation services like NovrAPI offer a straightforward solution: use a single unified BaseURL to access the capabilities of all major AI models.
The Core Mechanism of a Unified Interface Layer
The technical logic behind these platforms isn't complicated, but it genuinely solves real problems:
- Unified Interface Layer: Developers only need to connect to one API endpoint, and the backend automatically routes requests to different providers like Anthropic, OpenAI, Google, etc.
- Single Key Management: Say goodbye to the tedious process of applying for and maintaining separate API keys for each model
- Seamless Model Switching: Switching models in your code requires changing just one parameter — no need to refactor your API call logic
From a technical implementation perspective, the core of the unified interface layer is the API Gateway pattern, a classic design pattern in microservices architecture. Here's how it works: a developer's request first reaches the aggregation platform's gateway layer, which parses the model parameter (e.g., the model field) in the request, then converts and forwards the request in the corresponding provider's native API format. Since providers like OpenAI, Anthropic, and Google differ in request body structure, authentication methods, and response formats, the gateway layer maintains a set of Protocol Adapters responsible for bidirectional conversion between the unified format and each provider's proprietary format. This pattern has mature implementations in domains like payment gateways and cloud service aggregation.
This means developers can flexibly call Claude for code review, Codex for code generation, and Gemini for long-text analysis within the same project, with completely seamless switching at the interface level.
Intelligent Routing and Fault Tolerance
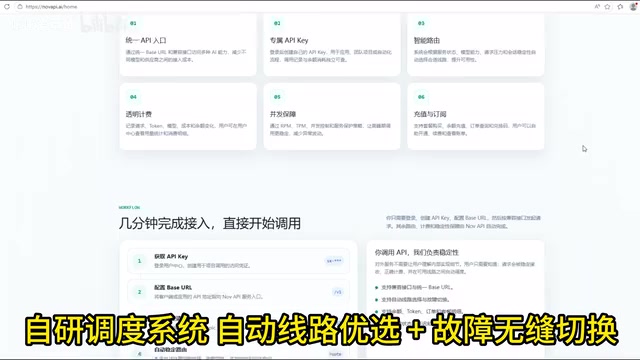
Beyond simple API forwarding, the scheduling layer design deserves closer attention:
- Automatic Route Optimization: Dynamically selects the optimal request path based on latency and load conditions
- Automatic Failover: When an official API experiences issues, the system automatically switches to backup routes to prevent business interruption
- Rate Limit Buffering: Provides request queuing and retry mechanisms to a certain degree during peak periods
This fault tolerance logic is especially critical for production environments. When calling official APIs directly, developers need to write their own retry logic and fallback strategies whenever they encounter 429 (rate limiting) or 500 (server error) responses. HTTP 429 (Too Many Requests) is the standard response for API rate limiting, and all major model providers enforce strict rate limits. For example, OpenAI sets per-minute request (RPM) and per-minute token (TPM) caps for different user tiers. When rate limiting is triggered, the response header typically includes a Retry-After field indicating how many seconds the client should wait. In engineering practice, developers need to implement an Exponential Backoff retry strategy — waiting 1 second on the first retry, 2 seconds on the second, 4 seconds on the third, and so on — while adding random Jitter to prevent multiple clients from retrying simultaneously and causing a "thundering herd" effect. While this logic seems simple, making it robust and reliable in production requires handling timeouts, idempotency, dead letter queues, and many other edge cases. Aggregation platforms build these capabilities in, reducing engineering complexity.
Team Collaboration and Enterprise Deployment Scenarios
For individual developers, the value of API aggregation is mainly about convenience. But for teams and enterprise users, it also addresses another layer of concerns — observability and cost management.
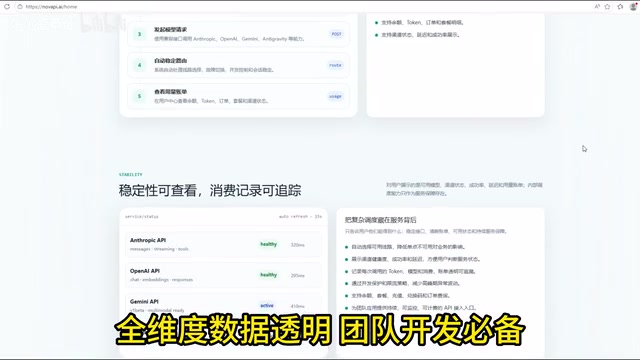
Data Transparency and Usage Monitoring
A mature API aggregation platform typically provides comprehensive backend management capabilities:
- Token Consumption Tracking: Clear visibility into how many tokens each API call consumes
- Billing and Order Records: Support for viewing cost breakdowns by team member or by project
- Channel Status Monitoring: Real-time visualization of metrics like latency and success rates for each model's API
Tokens are the basic unit of measurement for how large language models process text, and they don't simply equate to a single character or word. For English text, one token corresponds to roughly 4 characters or 0.75 words; for Chinese text, one character typically consumes 1.5 to 2 tokens. Model pricing is usually based on input tokens and output tokens separately, with significant price differences — for example, Claude 3.5 Sonnet is priced at $3 per million input tokens and $15 per million output tokens. In real projects, system prompts and conversation history context all count toward input tokens, meaning a seemingly brief request may consume far more tokens than expected. Precise token tracking helps teams identify which calling patterns are "burning money," enabling them to optimize prompt design or adjust context window strategies.
These capabilities are practically essential in enterprise scenarios. Once a team exceeds 5 people, API costs can easily spiral out of control without unified usage monitoring.
Use Cases and Selection Considerations
Of course, API aggregation isn't a silver bullet. Here are a few points developers should consider when evaluating:
- Latency-Sensitive Scenarios: The additional forwarding layer theoretically adds a few to tens of milliseconds of latency; scenarios with extremely high real-time requirements need hands-on testing
- Data Security and Compliance: Requests pass through a third-party platform, so enterprises handling sensitive data need to assess compliance risks
- Cost Comparison: Aggregation platforms typically add a service fee on top of official pricing; compare this against the cost of building your own solution
Regarding data security and compliance, when API requests are routed through a third-party aggregation platform, multiple considerations come into play. First is data transmission security — whether request content is encrypted with TLS end-to-end, and whether the platform caches or stores request/response data. Second is Data Residency — certain industry regulations (such as the EU's GDPR or China's Data Security Law) require that data not be transferred across borders or must be stored in designated regions. Third is audit and traceability — enterprises need to confirm whether the platform provides complete access logs to meet audit requirements for certifications like SOC 2 and ISO 27001. Additionally, certain industries like finance and healthcare have explicit security qualification thresholds for vendors, and using third-party relay services may require an additional Vendor Security Assessment process.
A Pragmatic Choice for Developers
In today's AI development ecosystem, the capability gap between models is narrowing, and stability and engineering efficiency are becoming the more critical competitive dimensions. Rather than switching between multiple official consoles and handling exception logic separately for each model, it's better to use a unified access layer to solve these infrastructure problems once and for all.
For development teams currently using multiple AI models simultaneously, API aggregation platforms are worth including in your technology evaluation. The key is to validate their stability and cost-effectiveness in your specific business scenarios, rather than following trends blindly.
Key Takeaways
Related articles
AI Agent Core Architecture Breakdown: From Concept to Enterprise-Grade Intelligent Agent Development
Deep dive into AI Agent architecture: perception, brain, and action modules. Covers RAG memory systems, tool calling mechanisms, Chain of Thought reasoning, and enterprise agent development roadmap.
Hands-On Tutorial: Build an AI Agent from Scratch with 200 Lines of Python
Build an AI Agent from scratch with 200 lines of Python, covering prompts, memory, tool calling, RAG, and Skills — a practical guide for developers.
Anthropic Reverses Controversial Policy of Secretly Throttling AI Researchers Using Claude
Anthropic reverses its controversial policy of secretly throttling Claude Fable/Mythos responses to frontier LLM development requests after community backlash, raising critical questions about AI transparency.