OpenAI Codex Powers a Self-Improving Tax AI Agent: A New Paradigm for Closed-Loop Evolution

OpenAI and Thrive's Tax AI achieves closed-loop self-evolution by learning from its own mistakes.
OpenAI and Thrive Holdings have launched a Codex-based Tax AI system with closed-loop self-improvement capabilities: when human reviewers correct errors, the system automatically traces the root cause, generates system-level improvements, and completes test validation before deployment. This marks a pivotal shift for AI Agents from static tools to continuously evolving systems, and its "human-in-the-loop + self-improvement" model is poised to become the standard architecture for enterprise-grade AI Agents.
Overview: When AI Agents Learn to Evolve from Their Own Mistakes
OpenAI recently unveiled a landmark AI application case — the Tax AI system built in partnership with Thrive Holdings. This Codex-based tax AI Agent not only handles complex tax preparation workflows but, more importantly, possesses self-improvement capabilities: when a human reviewer corrects an AI error, the system automatically traces the root cause of the failure, improves its own logic, and completes test validation before deployment.
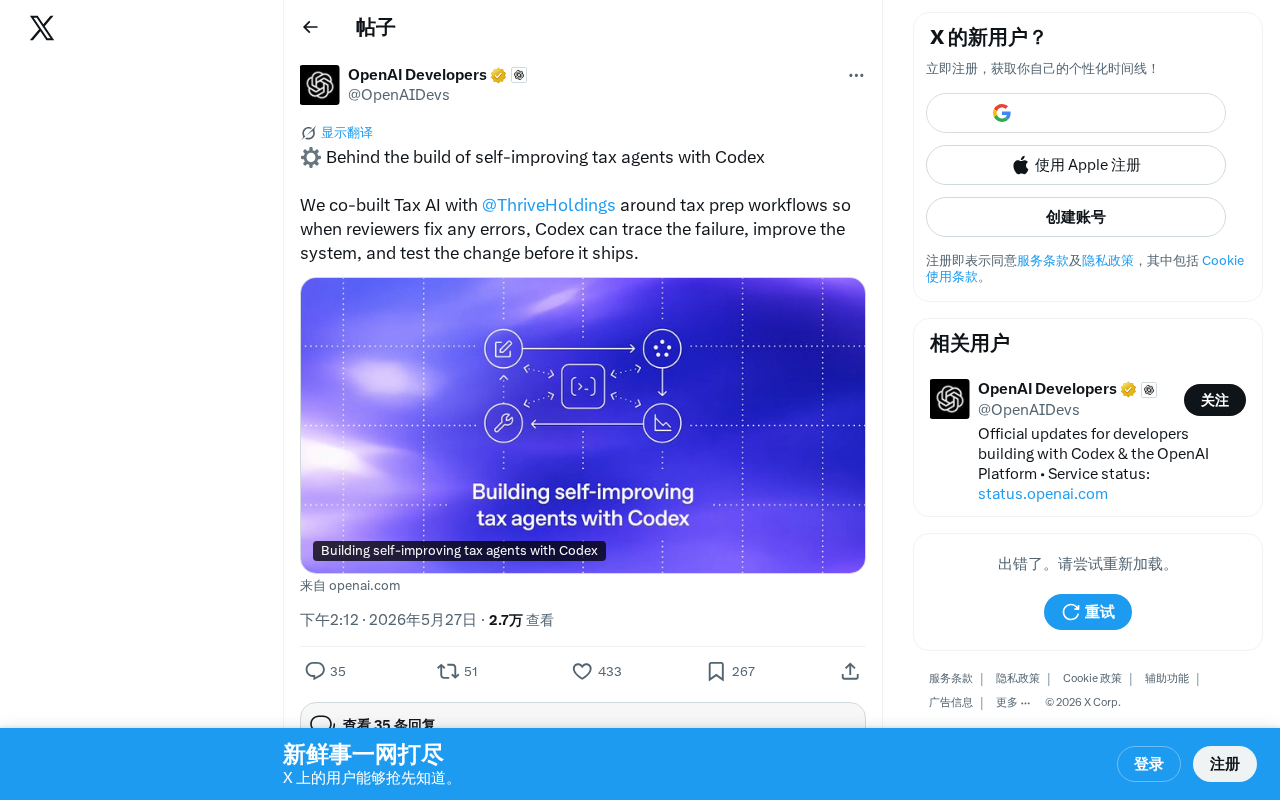
This marks a pivotal shift for AI Agents — moving from "deploy once" to "continuous evolution" — with far-reaching implications for the entire AI application industry.
Core Mechanism: A Three-Step Closed-Loop Self-Improvement Process
1. Trace the Failure
Tax preparation is a field that demands extreme precision — any calculation error or misapplication of rules can have serious consequences. In traditional AI systems, when human reviewers catch and correct errors, those corrections typically remain at the individual case level and never feed back into the system itself.
Tax AI takes a fundamentally different approach. When a reviewer corrects an error, Codex automatically traces the error back to its root cause — not through simple logging, but by performing a retrospective analysis of the entire reasoning chain, pinpointing exactly which step and what logic led to the incorrect judgment.
2. Improve the System
Based on the results of error tracing, Codex can automatically generate system improvement proposals. Specific measures may include adjusting prompt strategies, modifying how business rules are encoded, or optimizing data processing pipelines. The key point is that these improvements are system-level — not ad hoc patches for individual cases.
This means similar errors will be automatically avoided in subsequent processing, and system accuracy will continuously climb as usage increases.
3. Test Before Ship
Every improvement must pass test validation before being officially deployed. This is a critical safety gate — in high-stakes domains like taxation, unverified system changes could trigger cascading problems. After completing an improvement, Codex automatically runs a test suite to ensure the modification doesn't break existing functionality while actually resolving the target issue.
Why This Case Deserves Attention
The Leap from Tool to Autonomous System
Most AI applications today are still fundamentally "tools" — they execute tasks specified by humans but don't learn or improve from execution results. Tax AI demonstrates an entirely new paradigm: an AI system that can transform human feedback into system-level improvements, forming a true closed-loop learning cycle.
Human-in-the-Loop (HITL) is a classic paradigm in machine learning, referring to the incorporation of human judgment during model training or inference to improve system quality. Early HITL was primarily used during the data labeling phase, where humans labeled training samples before batch-updating model parameters. With the rise of Reinforcement Learning from Human Feedback (RLHF), HITL extended into the model alignment phase — ChatGPT's training process relied heavily on human raters ranking model outputs by preference. What Tax AI demonstrates is the third evolutionary layer of HITL: converting human feedback directly into runtime system-level code improvements, rather than waiting for the next model training cycle. This "online closed-loop" approach dramatically shortens the window from error discovery to system repair, compressing AI system iteration speed from "quarterly" to "per-event."
This "human-in-the-loop + self-improvement" model is likely to become the standard architecture for enterprise-grade AI Agents. Human reviewers are no longer just error correctors — they become the driving force behind system evolution.
Codex's Role as AI Engineering Infrastructure
Interestingly, OpenAI chose Codex for this project — its model with the strongest code generation and comprehension capabilities. This suggests that Tax AI's self-improvement mechanism likely involves automatic code-level modifications and generation, rather than simple parameter tuning.
OpenAI Codex is a large language model based on the GPT architecture, specifically fine-tuned for code comprehension and generation tasks. Originally released in 2021, it powered products like GitHub Copilot. Compared to general-purpose language models, Codex incorporates a massive amount of open-source code repositories in its training data, enabling it to understand program logic, recognize code structures, infer function intent, and translate between multiple programming languages. This capability allows Codex not only to "write code" but also to "understand systems" — comprehending why a piece of business logic produces an error and generating targeted fix patches. In the Tax AI scenario, this means system improvements don't stop at surface-level prompt adjustments but can penetrate deep into the code implementation of business rules, achieving genuine architecture-level self-repair.
Codex plays a role here more akin to an "AI software engineer" — one that can understand system architecture, locate problematic code, write fix proposals, and verify results. This further confirms the central importance of AI programming capabilities in building autonomous Agents.
Deep Validation in a Vertical Domain
Tax preparation is a rule-intensive, extremely low-tolerance-for-error domain. Tax Preparation in the United States is a highly regulated professional services field involving federal tax law (IRC), state tax laws, and IRS (Internal Revenue Service) filing rules that are updated annually — federal tax code alone exceeds 4 million words. Professional tax software like TurboTax and H&R Block have long dominated the market, but these systems are essentially rule engines relying on manually coded decision trees, struggling to handle edge cases and complex cross-rule interactions. The core challenge for AI entering the tax domain isn't just accuracy — it's explainability and auditability, as tax authorities require every calculation to be traceable to specific regulatory provisions.
OpenAI's decision to validate self-improving AI Agents in such a high-difficulty scenario is effectively a stress test of the entire technical approach under the most stringent compliance conditions, indicating considerable confidence in the reliability of this mechanism. Once this model is fully validated in the tax domain, expansion into similar fields like legal compliance, financial auditing, and medical diagnostics will be a natural progression.
Industry Implications and Outlook
This case reveals an important trend in AI Agent development: the competitiveness of future AI systems will depend not only on initial capabilities but also on the speed and quality of self-improvement. An AI Agent that can systematically learn from every piece of human feedback holds far greater long-term value than a static system — even one with stronger initial capabilities.
For enterprises, when selecting and deploying AI solutions, it's essential to evaluate the system's feedback loop design: Is there a mechanism to convert human review results into system improvements? Are improvements adequately tested? These questions are becoming key metrics for measuring AI Agent maturity.
At the same time, self-improvement capabilities raise new demands for AI safety governance. AI systems capable of self-modifying code introduce entirely new risk dimensions to the safety governance layer. Traditional software change management relies on manual code review, static analysis tools, and staged release strategies, with a clear responsible party for each change. When AI systems gain the ability to autonomously generate and deploy code modifications, traditional governance frameworks face fundamental challenges: Who is responsible for automatically generated fix proposals? How do you prevent the system from introducing new vulnerabilities while fixing an existing error? Tax AI's "test validation" step is a critical design element for addressing this challenge — using automated test suites to set safety boundaries for every improvement. This aligns with the "test-driven development" philosophy in software engineering.
Related articles
 Industry Insights
Industry InsightsAI Product Development in Practice: Model Selection, Building Moats, and Paths to Commercialization
Practical strategies for AI product development: why not to train models from scratch, when to use APIs vs. fine-tuning, building product moats, and the full path from evaluation systems to commercialization.
 Industry Insights
Industry InsightsNo Product Fits Your Needs? Building It Yourself Is the Best Starting Point for Indie Developers
Can't find a product that fits? Building from personal pain points is the best entry for indie developers. Niche needs + AI tools = rapid product creation.
 Industry Insights
Industry InsightsOpenAI Codex Tutorials Mass-Copied on Bilibili, Highlighting AI Content Farm Problem
At least 9 Bilibili accounts mass-published identical OpenAI Codex tutorial videos, exposing content farm operations in the AI tools space.