Qoder's Context Engineering in Practice: Four-Layer Retrieval Engine and Memory System Architecture
Qoder's Context Engineering in Practic…
Qoder tackles AI coding's Chatbot-to-Agent transition through context engineering and multi-layer retrieval architecture.
As AI programming evolves from Chatbot to Agent mode, context management complexity surges. Qoder (Tongyi Lingma's international edition) addresses this through three design principles: RepWiki for auto-generating repository documentation, Quest Mode for Spec Driven asynchronous programming, and powerful context engineering supporting 100K+ file retrieval. Its technical architecture includes a context engine (summarization, offloading, isolation), four-layer retrieval engine, memory engine, and tiered model scheduling, balancing cost and quality.
From Chatbot to Agent: A Paradigm Shift in Context Management
As large language model capabilities continue to advance—particularly after the release of Claude Sonic 3.5—AI programming products are undergoing a form migration from Chatbot to Agent. The core challenge this transformation brings is an exponential increase in context management complexity.
In the traditional Chatbot paradigm, context is primarily driven by human input—developers ask questions, paste images, share code snippets, and the AI responds to complete the flow. But in Agent mode, models gain the ability to interact with external environments through tool calls, fetching relevant information from codebases on demand, enabling dynamic context loading. Meanwhile, the Agent's autonomous decision-making capability makes execution flows extremely long, causing overall Token consumption to surge dramatically.
To understand the technical roots of this challenge, we need to grasp the basic concept of context windows. A Context Window is the maximum text length a large language model can process in a single inference, typically measured in Tokens. Tokens are the smallest units of text processing for models—in English, each word corresponds to roughly 1-2 Tokens, while each Chinese character is approximately 1.5-2 Tokens. From GPT-3's 4K context to Claude 3.5's 200K, the window has expanded 50x, but this doesn't mean information utilization efficiency scales linearly. Research has revealed the "Lost in the Middle" phenomenon—models pay significantly less attention to information in the middle of the context compared to the beginning and end, making context management a core engineering challenge.
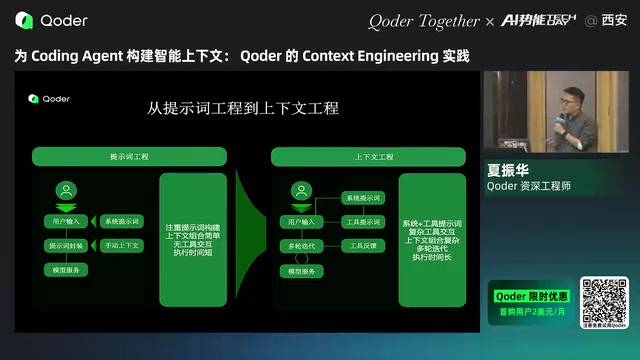
R&D engineers at Qoder (the international version of Tongyi Lingma) noted in their presentation: previously, with the Chatbot form, optimization focused mainly on prompt engineering, but in long-context scenarios, builders need to think about how to provide better context, how to organize context, and how to compress and summarize when the window is limited.
Qoder's Three Core Product Design Principles
Making Implicit Knowledge Explicit: RepWiki Auto-Generated Repository Documentation
Code repositories contain vast amounts of "dark knowledge"—knowledge misalignment between different collaborators, and an even larger knowledge gap between humans and AI. Qoder's RepWiki feature automatically generates a complete Wiki knowledge base for repositories, including system architecture, core entities, data flows, and more.
What makes this feature unique is that it not only solves the problem of developers being reluctant to write documentation, but also achieves near-real-time Wiki updates through code change detection and Commit detection. According to the presenter, the feature received excellent feedback during internal promotion at Alibaba: "Some developers said: I didn't even know my repository's system architecture was this sophisticated."
Spec Driven Mode: Quest Mode Asynchronous Programming
Academic research shows that writing out all requirements (points 1-8) at once for the AI produces significantly better results than providing them one at a time across 8 interactions. There's a profound technical reason behind this finding: Spec Driven development originates from the "Design by Contract" philosophy in software engineering, emphasizing the complete definition of system behavior specifications before coding begins. Multiple 2024 research papers on LLM programming capabilities found that LLMs perform significantly better when processing structured, complete requirement descriptions compared to fragmented interactive instructions. This is because a complete spec provides global constraint information, reducing ambiguity in the model's local decision-making—similar to how human developers are far more efficient when given a complete PRD rather than iterating on the fly.
Based on this finding, Qoder designed Quest Mode—where humans and AI collaboratively write a comprehensive spec document before task execution, then the AI autonomously handles implementation, verification, and reporting.

Quest Mode also supports cloud-based remote execution. Developers can submit requirements before leaving work (e.g., "add tests to achieve 100% coverage") and review results the next morning, truly enabling an asynchronous AI work mode.
Powerful Context Engineering Capabilities
Qoder's Agent Mode features a built-in code retrieval engine supporting search across 100,000 code files. According to testing, competitors typically only support a few thousand to ten thousand files. This means Qoder can locate relevant code much faster in complex repositories.
Deep Dive into Core Technical Architecture
Context Engine: Solving Long-Context Degradation
Data shows that as Agent task duration grows and the context window accumulates content, task completion quality drops rapidly. Qoder's context engine addresses this challenge from three dimensions:
Context Summarization Mechanism: When continuous model calls approach the 128K or 200K context limit, automatic summary compression is triggered.
Context Offloading: Addressing the problem of MCP tool descriptions consuming large amounts of Tokens (e.g., a GitHub MCP Server with 20-30 tools might consume over 10,000 Tokens), exploring dynamic offloading of unnecessary tool descriptions. Here it's worth explaining the MCP (Model Context Protocol) background: MCP is an open protocol launched by Anthropic in late 2024, aimed at standardizing interactions between large language models and external tools/data sources. In the MCP architecture, each tool (such as GitHub API, database queries) needs its functionality, parameters, and return values described via JSON Schema, and these descriptions themselves consume context space. A typical MCP Server might contain dozens of tool definitions, each consuming hundreds of Tokens, which cumulatively creates significant pressure on the limited context window. Therefore, dynamically offloading tool descriptions not needed for the current task becomes an important means of saving context space.
Context Isolation: Achieved through multi-agent collaboration. As an analogy: "Have an assistant find which files in the code need changes, but I don't need to know how you searched—just tell me these five files are relevant."
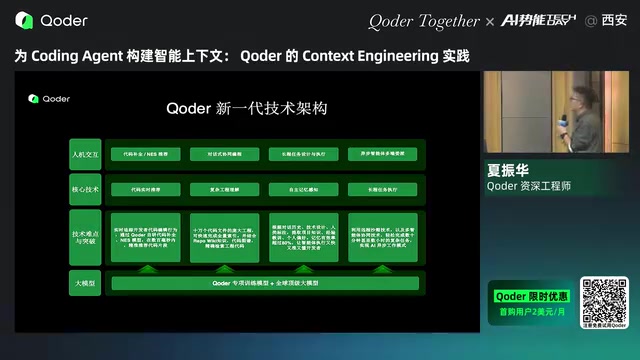
Context Caching: Critical Optimization for Cost and Speed
Taking Claude as an example, cache hits cost $0.30 per million Tokens, while cache misses cost $3.00—a 10x difference. If daily model calling costs are $1 million, the cost difference between 90% cache hit rate and 10% hit rate is enormous. Caching affects not only cost but also inference speed directly.
The technical principles of Prompt Caching deserve deeper understanding: when consecutive requests share the same prefix content (such as system prompts, tool definitions, existing conversation history), the server can reuse previously computed KV Cache (Key-Value Cache, i.e., intermediate computation results from the Transformer attention mechanism), avoiding redundant calculations. This requires the client to carefully design Prompt structure, placing stable, unchanging content at the front and dynamically changing content at the back to maximize cache hit rates. For AI programming Agents, system prompts, tool definitions, and repository-level context remain stable across multiple interaction rounds, making them naturally cache-friendly zones; while the user's specific instructions and latest code changes are placed at the end, ensuring the overall structure favors cache reuse.
Four-Layer Retrieval Engine Architecture
Qoder's repository retrieval employs a four-layer engine design:
-
Semantic Retrieval Engine: An Embedding model developed in collaboration with the Tongyi model team, enabling vectorized code retrieval. Embedding (vector embedding) is a technique that converts text into high-dimensional numerical vectors, making semantically similar content closer in vector space. Code Embedding faces unique challenges: the same functionality may have completely different implementations, variable naming styles vary widely, and code semantics are highly context-dependent. The Embedding model trained by the Tongyi model team for code scenarios needs to understand programming language syntax structures, API call patterns, design patterns, and other domain knowledge to achieve accurate semantic matching.
-
Keyword Retrieval Engine: A self-developed high-performance tool for fast code snippet matching. Keyword retrieval remains indispensable in code scenarios because identifiers like function names, class names, and variable names are often best matched exactly—semantic retrieval may actually introduce noise when handling such precise queries.
-
Code Graph Engine: Analyzes relationships and call chains between functions and classes through AST analysis, supporting real-time updates. AST (Abstract Syntax Tree) is a core concept in compiler theory that parses source code into a tree structure where each node represents a syntactic construct (such as function declarations, variable assignments, conditional branches). Code graphs built on AST can not only identify static code structure but also trace function call chains, class inheritance relationships, module dependencies, and other semantic information. Compared to pure text retrieval, code graphs can answer structural questions like "who calls this function" and "which modules would be affected by modifying this class"—which is crucial for Agents understanding the impact scope of code modifications.
-
RepWiki Knowledge Engine: Provides high-level engineering knowledge to help Agents understand the full project picture.
Recall results from the four-layer engines are sorted by a Re-rank model, returning code snippets most relevant to the user's query. The Re-rank model performs fine-grained ranking on initial recall results, comprehensively considering relevance, code quality, and context fitness to ensure the information ultimately presented to the Agent is both precise and concise.
Memory Engine: Beyond Simple Markdown Files
Compared to competitors (such as Claude Code's memory.markdown), Qoder's memory engine features deep design on both the storage and consumption sides:
Storage Mechanism includes three levels:
- User-triggered explicitly ("Remember how this repository should be started")
- Asynchronous extraction of common memory points after task completion
- Long-cycle asynchronous scanning: evaluating which memories are frequently used (reinforcement) and which haven't been used for a long time (forgetting)
This design draws from cognitive science research on human memory. The human brain's memory system reinforces important information through "spaced repetition" and naturally eliminates no-longer-needed information through the "forgetting curve." Qoder's memory engine simulates this mechanism: frequently used memory points gain increased weight and are more easily recalled in subsequent retrievals; memory points that haven't been triggered for extended periods have their weight decay, preventing outdated information from interfering with current decisions.
Consumption Mechanism operates at two timing points:
- Active retrieval of relevant memories when users ask questions
- Dynamic triggering during task execution (e.g., when the Agent discovers it needs to write tests, it automatically retrieves test-related memory points)

Model Scheduling and Credits Billing Strategy
Qoder's model scheduling is divided into four tiers: Performance (top-tier international models), Efficient (cost-effective models at 1/3 the price of Performance), Lite (free, based on domestic large-parameter models), and Specialized models (for scenarios like Wiki generation and memory compression).
This tiered scheduling strategy reflects the core contradiction in AI programming products regarding cost control: top-tier models (like Claude 3.5 Sonnet, GPT-4o) excel at complex reasoning tasks but are expensive, while many subtasks (such as code formatting suggestions, simple completions, documentation generation) don't require the strongest model's capabilities. Through intelligent routing, the system can significantly reduce API call costs without noticeably degrading user experience.
Regarding billing, Qoder was among the first in the industry to adopt Credits-based billing. Compared to per-conversation billing (which charges the same for simple and complex tasks) or per-Token billing (where numbers are too large to comprehend), the Credits model combined with an Auto mechanism routes tasks to appropriate models based on complexity. Real-world testing shows costs are better than most competitors.
Future Outlook: Natural Language Programming and Asynchronous Delegation
The Qoder team makes three predictions about the future of AI Coding: more requirements will be completed autonomously by AI, with agents handling more complex long-horizon tasks; asynchronous delegation will gradually become mainstream; and programming agents will be ubiquitous.
However, the presenter specifically emphasized that they do not encourage "pure wishful thinking programming"—the approach of never reviewing code implementation, ignoring software architecture, and only providing feedback like "it's still wrong." Professional developers should use natural language to lower the barrier to entry while still paying attention to implementation processes and quality. As he vividly put it: code written through pure vibe coding ends up like stacking power strips on top of power strips—it looks like it works, but inside it's a tangled mess.
This viewpoint touches on the fundamental positioning question for AI programming tools: is it a tool that replaces developers, or one that augments them? Given current technological maturity, AI is already quite reliable at local code generation, but still requires human professional judgment for system-level architectural decisions, performance optimization tradeoffs, and security assurance. Qoder's product philosophy clearly leans toward the latter—making AI a more powerful collaborative partner through better context engineering, rather than attempting to completely replace the human developer's thinking process.
Key Takeaways
- Qoder supports retrieval across 100,000+ code files through a four-layer retrieval engine (semantic, keyword, code graph, RepWiki), significantly outperforming competitors
- The memory engine implements a complete closed loop of automatic storage, asynchronous extraction, and dynamic consumption, simulating human memory's reinforcement and forgetting mechanisms
- Context engineering solves long-context quality degradation from three dimensions: summary compression, tool description offloading, and multi-agent isolation
- Quest Mode, based on the Spec Driven philosophy, supports cloud-based asynchronous execution, transforming human-AI collaboration from real-time supervision to asynchronous delegation
- Credits billing combined with Auto model routing automatically selects appropriate models based on task complexity, optimizing the balance between cost and performance
Related articles
 Industry Insights
Industry InsightsAI Product Development in Practice: Model Selection, Building Moats, and Paths to Commercialization
Practical strategies for AI product development: why not to train models from scratch, when to use APIs vs. fine-tuning, building product moats, and the full path from evaluation systems to commercialization.
 Industry Insights
Industry InsightsNo Product Fits Your Needs? Building It Yourself Is the Best Starting Point for Indie Developers
Can't find a product that fits? Building from personal pain points is the best entry for indie developers. Niche needs + AI tools = rapid product creation.
 Industry Insights
Industry InsightsOpenAI Codex Tutorials Mass-Copied on Bilibili, Highlighting AI Content Farm Problem
At least 9 Bilibili accounts mass-published identical OpenAI Codex tutorial videos, exposing content farm operations in the AI tools space.