SciMDR: How a 7B Small Model Rivals GPT-5 in Scientific Reasoning

SciMDR framework enables a 7B model to match GPT-5 in scientific literature reading comprehension
Yale University and collaborators introduce SciMDR, a two-stage data synthesis pipeline that solves the "impossible triangle" of scale, reliability, and complexity in scientific synthetic data. The framework first extracts atomic claims from papers and reverse-engineers high-quality Q&A pairs, then embeds them back into full-length documents to train evidence localization abilities. The resulting 7B-parameter model scores 49.1 on scientific benchmarks, far surpassing GPT-4o and approaching GPT-5 performance.
Yale University, the University of Chicago, and TCS Research have jointly introduced the SciMDR framework. Through a two-stage data synthesis pipeline, this framework enables a model with only 7 billion parameters to achieve performance comparable to GPT-5 in scientific literature reading comprehension. This research reveals a profound insight: in vertical domains, breakthroughs in data quality can bridge the gap created by differences in model parameter count.
The "Valley of Death" in Scientific Reading: Why Even Large Models Struggle
Despite the impressive performance of large language models in code generation, creative writing, and other domains, they often fall into a "valley of death" when confronting real scientific literature. Scientific papers typically feature ultra-long contexts of tens of thousands of words, sparsely distributed key information, and interleaved text-figure characteristics that demand cross-page associative comprehension. Specialized terminology and complex logical derivations form an "academic black box" that further compounds reasoning difficulty.
The fundamental reason scientific literature comprehension remains challenging for AI lies in the essential structural differences between scientific text and general text. A typical academic paper contains 8,000-15,000 words of body text, 20-50 mathematical formulas, 10-30 figures and tables, and numerous cross-paragraph logical references. This information density and cross-modal nature far exceeds the mainstream corpora (such as web text and books) that large models encounter during pre-training. Moreover, the argumentative structure of scientific papers is often non-linear—a conclusion may depend on a specific assumption in the methods section, which in turn requires a mathematical proof in the appendix to be fully understood. This "long-distance dependency" places extremely high demands on the model's context window utilization efficiency.

The deeper problem lies in the "impossible triangle" dilemma facing synthetic training data—scale, factual reliability, and real-world complexity are difficult to achieve simultaneously. Synthetic Data is one of the core strategies in current AI training, with the basic approach of using existing strong models to generate new training samples to enhance weaker models. However, in the scientific domain, this strategy faces unique challenges. The "impossible triangle" borrows from the Mundell impossible trinity concept in finance: scale (requiring hundreds of thousands of samples), factual reliability (answers must be factually correct), and real-world complexity (questions need to be answered in real long-document environments)—traditional methods can satisfy at most two of these three simultaneously. This is because as context length increases, even GPT-4-level models experience "attention dilution," causing generated answers to contain factual errors or logical leaps.
Existing solutions typically take one of two compromise paths:
- Greenhouse Effect Approach: Providing AI with only a single figure or extremely short atomic context. The generated Q&A data has perfect logic but completely lacks real-world complexity. Once removed from the idealized environment into real long documents, AI rapidly loses navigation and reasoning capabilities.
- Brute Force Approach: Having AI read an entire long paper and then generate Q&A pairs. While the format approximates real applications, excessive information noise dilutes model attention, and the generated Q&A often contains false logic, ultimately contaminating the training process.
SciMDR's Breakthrough: Two-Stage Pipeline Architecture
SciMDR's core innovation lies in its "dimension reduction construction + dimension elevation reshaping" two-stage strategy, elegantly unifying the otherwise contradictory requirements of factual accuracy and real-world complexity.
Stage One: Dimension Reduction—Locking in Absolute Factual Correctness
SciMDR first extracts atomic-level core claims from massive volumes of papers, surgically isolating minimal conclusions such as "Model X is faster than Model Y." Because the context is minimized, AI produces virtually no logical hallucinations at this step, thereby constructing a highly accurate foundational fact base.
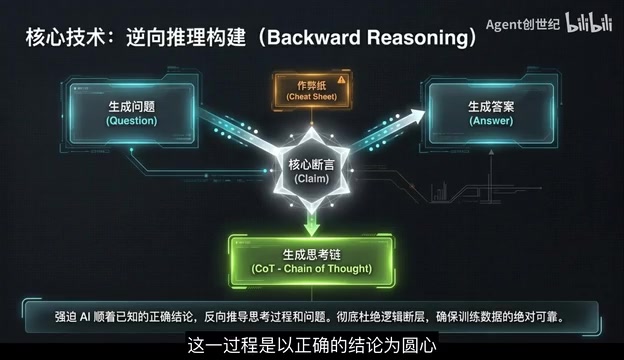
After locking in core claims, SciMDR employs reverse reasoning construction to generate high-quality data. Traditional data synthesis uses a "forward generation" mode: given document → generate question → generate answer → generate reasoning chain. In this pipeline, errors at each step propagate and amplify downstream. Reverse reasoning inverts this flow: starting from the correct conclusion as the origin, it backward-derives questions, answers, and complete Chain-of-Thought reasoning, with verification values generated to assist in quality checking. This is analogous to "backward induction" in mathematics—when the endpoint is known, the correctness of the traced-back path is easier to guarantee. The introduction of verification values provides additional quality gating, ensuring the generated reasoning chains are logically self-consistent. This method forces AI to trace reasoning paths backward from known correct answers, completely eliminating logical disconnections caused by forward generation.
Stage Two: Dimension Elevation—Returning to the Real-World Jungle
The second stage places these verified Q&A pairs back into the original papers—complete with tens of thousands of words, dozens of figures and tables, and complex formulas in their full-length context. The purpose is to construct highly challenging training samples that teach AI not only correct logic but also the ability to precisely locate evidence within noisy real-world environments.
This stage introduces the critical Evidence Localization Injection (ELI) mechanism, which forces AI to perform spatial navigation within the document before answering—for example, outputting specific instructions like "scan full text" or "locate to Figure 3." Evidence Localization Injection is essentially a structured attention guidance mechanism. In traditional long-document Q&A, models must independently discover relevant evidence among tens of thousands of tokens—a process highly dependent on the self-organizing capability of the model's internal attention mechanism and easily disrupted by irrelevant information. The ELI mechanism explicitly annotates the physical location of evidence in training data (such as "Section 3, Paragraph 2" or "the x-axis of Figure 4"), transforming evidence retrieval from implicit attention computation into an explicit spatial navigation task. This closely mirrors human behavior when reading papers—we typically first scan quickly to locate relevant sections, then read specific content in depth. This "locate first, reason second" step-by-step strategy effectively reduces the cognitive load of single-step reasoning, enabling the model to develop the ability to penetrate long-text noise and precisely lock onto key evidence even amid massive amounts of irrelevant information.
Dataset and Evaluation Benchmark: Industrial-Scale Training Resources
The SciMDR dataset demonstrates impressive industrial scale: covering 20,000 cutting-edge scientific papers, containing 300,000 verified high-quality Q&A pairs, each sample accompanied by rigorous reasoning chains. Chain-of-Thought (CoT) is a prompt engineering technique proposed by the Google Brain team in 2022, with the core finding that when models are required to show intermediate reasoning steps, their performance on complex reasoning tasks improves significantly. CoT's effectiveness stems from two mechanisms: first, decomposing complex problems into multiple simpler sub-problems, reducing the reasoning difficulty at each step; second, intermediate steps provide an externalized representation of "working memory," alleviating information forgetting issues in Transformer architectures during long-range reasoning. In SciMDR, CoT is not merely an auxiliary tool during inference but a core component of the training data—each Q&A pair comes with a complete reasoning chain, enabling the model to internalize scientific reasoning patterns during training.
In terms of data composition, figure-text fusion and pure chart tasks each account for over 40%, while pure text accounts for only 15%. This multimodal distribution provides abundant high-quality corpora for training scientific AI.

To assess model performance in real scientific research scenarios, the research team also released the SciMDEval expert-level evaluation benchmark, containing 907 manually annotated high-difficulty questions specifically designed to test evidence localization capabilities across documents spanning dozens of pages. This benchmark decomposes scientific thinking into five core dimensions:
| Dimension | Assessed Capability |
|---|---|
| EQ | Figure-text supporting relationships |
| CIM | Mapping from abstract theory to concrete instances |
| HVI | Cross-clue reasoning and prediction |
| CAC | Critical analysis—determining whether text overstates data |
| ARS | Argument extraction and synthesis |
This dimensional decomposition marks AI's formal transition from simple "describe what you see" to becoming a research assistant with critical thinking capabilities.
Experimental Results: Performance Breakthrough of the 7B Model
The researchers selected Qwen2.5-VL-7B, a model with only 7 billion parameters, as the base model. Qwen2.5-VL-7B is a multimodal vision-language model released by Alibaba's Tongyi Qianwen team, representing the vision-enhanced version of the Qwen2.5 series. The model uses a Vision Transformer (ViT) as its visual encoder, combined with large language model text comprehension capabilities, supporting mixed image-text input. The 7B (7 billion) parameter scale allows inference on a single consumer-grade GPU (such as an A100 40GB), with deployment costs far lower than closed-source models with hundreds of billions of parameters like GPT-4o. Choosing a 7B model as the base has significant practical implications: it represents a computational scale affordable for academic institutions and small-to-medium enterprises. If top-tier performance can be achieved at this scale, it means the democratization of high-quality scientific AI tools becomes possible.
Through specialized training with SciMDR's high-quality data, the research team transformed it into a professional scientific reasoning model.

In the most rigorous SciMDEval real scientific research evaluation, the SciMDR-7B model achieved a score of 49.1 points, an improvement of 29.3 points over the base model. This result not only significantly surpasses GPT-4o's 24.7 points but also matches the estimated performance level of the top-tier model GPT-5. In chart Q&A tasks such as ChartsQA, it also significantly outperforms open-source models of the same or even 8B scale, including LLaVA-OV and InternVL3.
Ablation Experiments Reveal Core Secrets
Ablation Study is a standard methodology in deep learning research for verifying the contribution of individual components. Its approach is similar to gene knockout experiments in biology—by sequentially removing a component from the system and observing changes in overall performance to quantify that component's importance. SciMDR's ablation experiment design is particularly elegant: it not only validates individual component contributions but also reveals synergistic effects between components.
Experimental results further reveal the key factors behind SciMDR's high performance:
- Localization Injection + Full Chain-of-Thought: Performance reaches peak at 49.1 points
- Disabling Localization Injection: AI gets lost in long-text noise, with performance plummeting to 22.8 points (a 53.6% drop), demonstrating that in long-document scenarios, "knowing where to look" is more fundamental than "knowing how to think"
- Retaining only Localization, Removing Chain-of-Thought: Complex reasoning capability drops dramatically to 16.9 points, showing that even finding the correct location is insufficient without structured reasoning ability to reach correct conclusions
The experiments powerfully demonstrate that teaching AI "where to find evidence" and "how to think step by step" are equally important—neither can be dispensed with.
Practical Capabilities: From Chart Interpretation to Engineering-Level Understanding
In CIM (Concept-Instance Mapping) practical cases, SciMDR performs like a real engineer—it not only interprets legends but also precisely maps abstract "encoder/decoder" concepts from text to specific physical modules in architecture diagrams, accurately identifying stacked residual LSTM modules and clarifying their physical constraint feedback loops.
In HVI (Hidden Variable Inference) cases, the model acts as a professional data analyst, analyzing multiple violin plot comparisons of GPT-3.5 and LLM-A3's hidden behavioral tendencies, precisely inferring that GPT-3.5 possesses strong cross-scenario social intent, proving that its training achieved norm generalization rather than simple overfitting.
Conclusion and Implications
SciMDR's success sends a clear signal: in vertical domains, breakthroughs in data quality can compensate for insufficient model parameter counts. By resolving the quality contradiction of the synthetic data "impossible triangle," even a 7B small model can unleash top-tier scientific research potential. This framework's two-stage approach—first ensuring logical correctness in a controlled environment, then returning verified data to real complex scenarios—provides an extremely valuable methodological reference for model development in other vertical domains. As this framework progresses toward open-source release, we have good reason to expect more lightweight models achieving "punching above their weight" breakthroughs in specialized domains.
Related articles
New Species Discovered in New York's C…
New Species Discovered in New York's Central Park? Inside the Urban Insect Hunting Project
Scientists set up insect traps in NYC's Central Park and Prospect Park to discover unknown species. With 90% of Earth's species still unnamed, urban biodiversity research is becoming a new trend in ecology.
The Full Story of the Higgs Boson Disc…
The Full Story of the Higgs Boson Discovery: An Insider's Account of the 'God Particle'
A Fermilab physicist's insider account of the Higgs boson discovery: the transatlantic race with CERN, behind-the-scenes details of the 2012 announcement, 14 years of verification, and the true origin of the 'God Particle' name.
 Research
ResearchDeep Dive into Claude Code's Open-Source Architecture: The Design Philosophy Behind 510,000 Lines of Code
Deep analysis of Claude Code's open-source architecture: dual-loop design, 7-step tool pipeline, 4-layer token compression, memory systems, and multi-agent collaboration patterns.