The Ultimate Guide to Squeezing Every Drop from Mythos/Fable: Burning Through $8,000 in Inference Credits in 10 Days
How to maximize $8,000 in Fable/Mythos inference credits from a $200 Claude subscription before the deadline.
A practical guide to squeezing maximum value from Anthropic's Fable/Mythos model before it leaves the subscription plan on June 22. Covers five-hour timer manipulation via Cron jobs, dual account rotation, multi-Agent orchestration workflows for PR review and triage, Mac Mini remote deployment via Tailscale, and sub-Agent model optimization — all demonstrated through real-world usage that burned $8,000+ in inference on just $200 in subscriptions.
Introduction: A Model That's Keeping Developers Up at Night
Anthropic's newly released Fable model (essentially Mythos with safety guardrails) is driving developers wild. Theo, a well-known tech YouTuber, shared his extreme usage experience over the past 10 days — burning through $4,350 in inference costs on a single laptop, plus $1,112 on a Mac Mini, totaling over $5,400 in inference volume, while actually paying only $200 in subscription fees.
In the billing system of large language models, a Token is the most basic unit of measurement — one token corresponds to roughly 3/4 of an English word, or about 1-2 Chinese characters. Inference refers to the process where a model receives input and generates output. Unlike model training, inference is a real-time computation that occurs every time the model is used. Take Claude as an example: API pricing typically charges separately for input tokens and output tokens, with high-end models costing tens of dollars per million output tokens. The millions of tokens Theo consumed would cost $5,400 at API prices, but the subscription model bundles these costs into a fixed monthly fee, creating a massive price gap — and that's exactly what "subsidy" means here.
This isn't a tutorial on "how to save tokens." Quite the opposite — it's a practical guide on how to maximize these heavily subsidized inference credits before Fable gets removed from the subscription plan (deadline: June 22).
Understanding the Rate Limits: Dual Restrictions and How to Work Around Them
How the Five-Hour Session Limit Works
Claude Code's Pro and Max subscriptions have two layers of limits: a five-hour session limit and a weekly total limit. The key discovery is that the timer only starts counting down when you send your first message.
This means a simple optimization strategy: before you're ready to start working, go to claude.ai, send a "hi," then immediately stop — letting the timer start early. That way, when you actually begin intensive work 4.5 hours later, the limit resets within 30 minutes instead of making you wait another 4 hours after you've used it up.
Theo even set up a Cron job to automatically trigger a Claude Code message every 5 hours, ensuring the timer is always counting down. Cron is a task scheduler in Unix/Linux systems that allows users to automatically execute commands or scripts on a preset schedule. On macOS, although Apple recommends using launchd as an alternative, traditional Cron syntax is still widely used. Theo leveraged this mechanism to auto-send messages and manipulate the timer — essentially a form of "time arbitrage" against the rate limit system, perfectly offsetting cooldown periods with actual work time so that every time he sits down to work, there's plenty of quota available.
The Math Behind Weekly Limits
Based on real-world testing, each time you hit 100% of the five-hour limit, it consumes roughly 25% of the weekly quota. In other words, you can max out the five-hour window 4 times per week before exhausting the weekly limit.
Dual Account Rotation Strategy
Theo maintains two $200 Claude Code accounts simultaneously, switching between them in the terminal with a simple /login command. Even more cleverly — switching accounts doesn't interrupt a running workflow. The next tool call automatically routes to the new account, meaning you can seamlessly switch to another account just as one is about to hit its ceiling.
Workflow Design: Making Every Token Count
PR Review and Multi-Agent Judging System
Theo demonstrated a real-world case: his Lakebed project had three PRs (#35, #37, #39) implementing the same feature, each independently built by Codex and Claude Code. He had Mythos create a complete review workflow consisting of:
- 13 independent audit Agents
- 7 judging Agents
- Multiple harvesting and synthesis Agents
Multi-Agent Systems are a classic architectural pattern in artificial intelligence, originating from distributed AI research. In the LLM era, it refers to multiple AI instances each taking on different roles, coordinating through mechanisms to collaboratively complete complex tasks. The core advantages of this architecture are: a single Agent's context window is limited (even the most advanced models only have 100K-200K tokens of effective processing capacity), but through division of labor they can handle information far exceeding the capacity of a single conversation; different Agents can employ different prompting strategies and evaluation criteria, simulating role specialization in human teams; multiple independent judgments combined through "voting" or weighted synthesis mechanisms can significantly improve the reliability of conclusions, similar to the concept of Ensemble Learning.
The entire workflow burned through 1.8 million tokens in 30 minutes, consuming 21% of a fresh usage window. This pattern of "Agents reviewing other Agents' work" has staggering token consumption, but it produced comprehensive analysis that would be nearly impossible for a human to complete in the same timeframe.
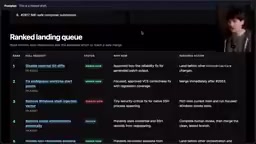
Daily PR Triage Automation
For developers maintaining multiple open-source projects, a more practical application is having Mythos scan all repository PRs every morning and generate a prioritized queue, sorted by "merge difficulty" and "attention-worthiness."
Theo's T3 Code project has 400+ issues and 300+ PRs — traditional methods simply can't manage this effectively. The Agent-generated triage report led to a simple bug-fix PR that had been neglected for a month getting merged in 5 minutes.
The Power of HTML Plan Files
Theo built a simple service to host plan files in HTML format, allowing Agents to output readable URLs. The advantages of this approach include:
- More readable than Markdown
- Viewable on a phone browser anytime
- Links can be directly pasted to another Agent to continue work
- Creates a complete loop of "Codex writes code → Mythos reviews → Codex revises based on review"
Remote Workflows: Free Your Laptop with a Mac Mini
Mac Mini as an Always-On Agent Host
A critical workflow improvement is offloading long-running Agent tasks to a Mac Mini. Access is available through three methods:
- Direct SSH (same network) or via Tailscale (remote)
- macOS built-in Screen Sharing (with Tailscale traversal)
- T3 Code remote system (control from another computer or phone)
Tailscale is a zero-trust networking tool built on the WireGuard protocol that creates a virtual private network for each device without requiring a traditional VPN server. Its core advantage is NAT traversal — even when devices are behind different home routers or corporate firewalls, it can establish direct peer-to-peer encrypted connections with latency typically measured in just a few milliseconds. Unlike traditional VPNs that require exposing public ports, Tailscale uses coordination servers to exchange keys without relaying data, significantly reducing security risks. For scenarios where you need to remotely control a development machine at home, it's virtually the zero-configuration optimal solution.
This fundamentally changes the usage pattern — from "running short tasks so you can close your laptop anytime" to "letting Agents do long exploratory work." You no longer need to expect directly usable results every time; instead, you expect interesting findings that guide subsequent work.
Fable/Mythos Orchestration Capabilities and Sub-Agent Optimization
Orchestration Is Fable's Core Superpower
Fable excels at orchestrating multi-Agent workflows, but there's an important caveat: Fable tends to have sub-Agents also use the Fable model, which leads to unnecessary token consumption.
Orchestration in AI systems refers to the process where a top-level controller handles task decomposition, Agent assignment, result aggregation, and conflict resolution. A good orchestration layer needs to understand the global structure of a task and determine which subtasks require high-intelligence models and which only need fast execution models. This is similar to microservices architecture in software engineering — not every service needs the most powerful hardware; rational resource allocation achieves optimal cost-effectiveness.
Explicitly telling Fable to use Opus or Sonnet as sub-Agent models during orchestration can significantly reduce consumption without sacrificing quality. Fable's value lies in top-level planning and coordination; the actual execution work can be handed off to more economical models.
Advanced Automated Agent Loops
More advanced use cases include:
- One Agent creates a PR, another Agent monitors and automatically reviews it
- Agents using browser screen recording to prove modifications work
- Codex waking up every 5 minutes, automatically distributing work across different threads
- Combining Sentry or Datadog data to let Agents autonomously discover and fix issues
Sentry is a real-time error tracking platform that automatically captures exceptions, stack traces, and contextual information from applications; Datadog is a full-stack observability platform covering infrastructure monitoring, APM (Application Performance Management), and log management. When these tools are combined with AI Agents, they form an autonomous repair loop: monitoring system detects a new error in production → notifies Agent via Webhook → Agent analyzes the stack trace and related code → generates a fix PR → another Agent reviews and merges it. This pattern compresses Mean Time To Repair (MTTR) from hours to minutes, representing the cutting edge of AIOps (AI for IT Operations) practice.
Mindset Shift: From Fear-Driven to Excitement-Driven
As Sawyer suggested: "You need to be more ambitious than before. Have the model rewrite your entire production app from scratch, have it deploy, add account systems, multiplayer collaboration features — all the things you normally wouldn't bother with for personal projects."
Theo emphasized an important mindset distinction:
- Wrong mindset: Frantically using AI out of fear of losing your job → Results in anxiety and low-quality output
- Right mindset: Exploring the limits with the excitement of building → Results in custom tools, forked software, and more efficient workflows
The key principle is: Lower the bar for "what's worth building," raise the standard for "how far to take it." When you find yourself asking "can an Agent do this?" — just let it try, then learn from the failure. The underlying logic of this mindset shift is: when marginal cost approaches zero (no additional charges per use under a subscription model), traditional cost-benefit analysis no longer applies. You should think like a researcher with an unlimited experiment budget — every failed attempt is a free learning opportunity, and every success is pure gain.
Conclusion: A Window Where $200 Unlocks $8,000 in Value
In the final days before Fable is removed from the subscription plan, this is a rare window to experience what AI-assisted development looks like in the future — where the boundaries of developer productivity lie when inference cost is no longer a bottleneck. While spending $8,000 per month on inference isn't realistic, paying $200 for an equivalent experience is absolutely worth trying.
The unsustainability of this pricing strategy is also worth reflecting on: Anthropic's current subsidy model is essentially trading venture capital funding for user growth and usage data, similar to early Uber's two-sided subsidies for riders and drivers. When the subsidy window closes, developers will need to reassess which workflows still have positive ROI at real API prices — and right now is the best time to explore those boundaries in a zero-risk environment.
Key Takeaways
Related articles
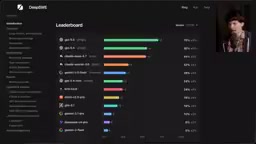
DeepSWE Benchmark Deep Dive: Exposing SWE-Bench Flaws and the True Coding Ability Rankings
Deep dive into how DeepSWE exposes SWE-Bench Pro's data contamination and cheating issues. GPT-5.5 leads at 70%, open-source models lag far behind. Covers results, cost comparisons, and practical developer advice.
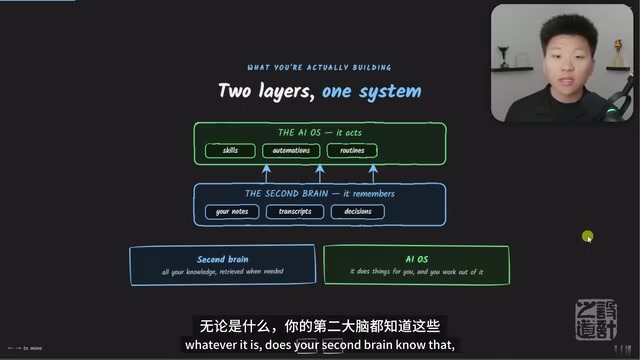
Guide to Building a Second Brain with Claude AI: The Four-C Framework for Your Personal AI Operating System
Learn how to build an AI second brain with Claude using the Four-C Framework (Context, Connection, Capability, Cadence) to create a personal AI operating system with practical examples.
Zero-Code Mini Program Development with Codex: Building 7 Features in 5 Days — A Hands-On Story
A creator used OpenAI Codex to build an image editing mini program with 7 features in 5 days — zero coding. Learn about Codex's AI capabilities and tips for getting started.