#DataCurve
2 related articles
·2 min
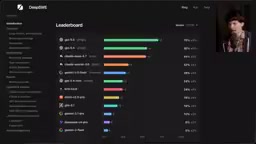
DeepSWE Benchmark Deep Dive: Exposing SWE-Bench Flaws and the True Coding Ability Rankings
Deep dive into how DeepSWE exposes SWE-Bench Pro's data contamination and cheating issues. GPT-5.5 leads at 70%, open-source models lag far behind. Covers results, cost comparisons, and practical developer advice.
Read more →
·3 min
DeepSWE Benchmark Reveals the Truth: GPT 5.5 Leads Opus 4.7 by a Wide Margin
DeepSWE long-horizon benchmark shows GPT 5.5 leads Opus 4.7 by 15+ points with 70% pass rate at one-third the cost. Deep dive into contamination-free testing and AI coding implications.
Read more →