DeepSWE Benchmark Reveals the Truth: GPT 5.5 Leads Opus 4.7 by a Wide Margin
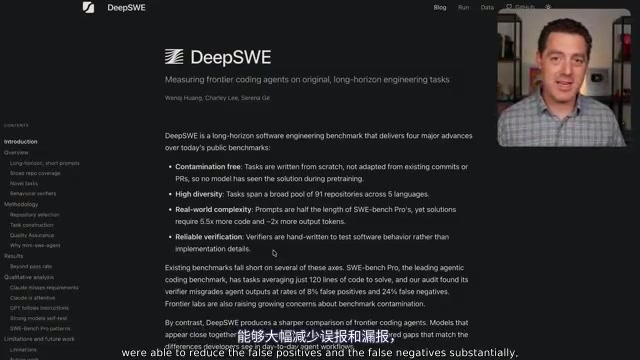
DeepSWE benchmark shows GPT 5.5 beating Opus 4.7 by 15+ points at one-third the cost.
The new DeepSWE benchmark from datacurve.ai tests AI models on contamination-free, long-horizon software engineering tasks across 91 repos and 5 languages. GPT 5.5 leads with ~70% pass rate, outperforming Opus 4.7 by over 15 points while costing just $5.80 per trial versus $16. The benchmark also reveals key behavioral differences: Claude forgets multi-part requirements but excels at environment awareness, while GPT shows superior instruction fidelity.
AI benchmarks in software engineering have long been controversial — most leaderboards fail to reflect real-world coding scenarios, and high scores don't necessarily translate to practical usefulness. A brand-new benchmark called DeepSWE is changing the game, with results showing a gap of over 15 points between GPT 5.5 and Opus 4.7, upending the "neck and neck" impression left by previous leaderboards.
Why DeepSWE Matters
This benchmark, developed by datacurve.ai and dubbed a "long-horizon software engineering benchmark," achieves breakthroughs over existing public benchmarks across four key dimensions.
First is contamination-free design. All test tasks are written from scratch rather than adapted from public GitHub commits or PRs. This means no model has ever seen the answers to these problems during pre-training. By contrast, mainstream benchmarks like SWE-Bench Pro heavily rely on issues and commits from public repositories, meaning models may have already "memorized" the answers during training.
Data Contamination is one of the thorniest problems in large language model evaluation. When a model has been exposed to test set data during pre-training, its performance on that test is artificially inflated, leading to distorted evaluation results. Since the training corpora for GPT, Claude, and similar models typically include vast amounts of public GitHub code, any benchmark built from public repositories faces contamination risk. Early benchmarks like SWE-Bench extract tasks from GitHub Issues and Pull Requests, and models may have already "seen" these problems and their solutions during training — essentially having peeked at the answer key before the exam. DeepSWE circumvents this issue by writing entirely new tasks from scratch, methodologically similar to the "original question bank" strategy used in educational testing.
Second is high diversity. The tests cover 91 code repositories and 5 programming languages (TypeScript, Go, Python, JavaScript, Rust), rather than focusing solely on Python or a handful of large projects.
Third is real-world complexity. DeepSWE's prompts are only half the length of SWE-Bench Pro's, yet solutions require 5.5x more code and 2x more output tokens. This accurately simulates how real developers interact with AI — most people simply tell the AI "fix it" rather than writing lengthy, detailed specifications.
Fourth is a reliable verification mechanism. DeepSWE's verifier reduces misjudgment rates to extremely low levels.
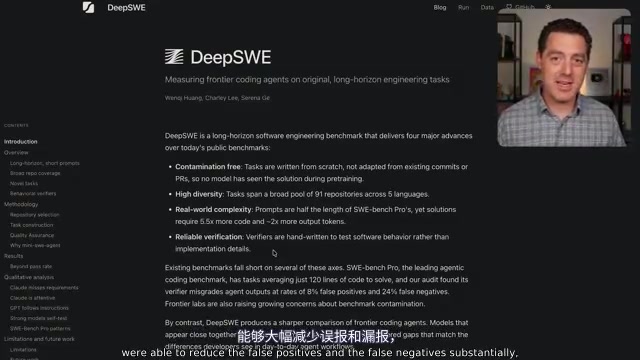
The specific numbers are striking: SWE-Bench Pro has a false positive rate of 8.5% (the verifier accepts incorrect implementations), while DeepSWE's is just 0.3%. SWE-Bench Pro's false negative rate is a staggering 24% (the verifier rejects correct implementations), compared to DeepSWE's 1.1%. Imagine that — in SWE-Bench Pro, 1 out of every 4 correct answers is incorrectly marked as a failure.
In the context of automated code verification, a false positive means the verifier incorrectly accepts an implementation that is actually wrong — the code passes tests but doesn't truly solve the problem, typically because test cases aren't comprehensive enough to catch edge cases or specific failure scenarios. A false negative means the verifier incorrectly rejects an implementation that is actually correct — the code logic is sound but fails due to limitations of the testing framework (such as overly strict output format matching or environment dependency issues). SWE-Bench Pro's 24% false negative rate means that for every 4 correct answers a model submits, 1 is misjudged as wrong. This systematically depresses all models' scores and can distort relative rankings — if a particular model happens to be more prone to triggering the verifier's misjudgment conditions, its true capability will be severely underestimated.
Leaderboard Results: GPT 5.5 Dominates Across the Board
On the DeepSWE leaderboard, GPT 5.5 sits at the top with approximately a 70% pass rate, leading Opus 4.7 by over 15 percentage points. This stands in stark contrast to SWE-Bench Pro, where the two models score nearly the same. The full ranking goes: GPT 5.5, GPT 5.4, Opus 4.7, followed by Sun 4.6, Gemini 3.5 Flash (around 28%), and others.
More importantly, DeepSWE exhibits far greater score differentiation than SWE-Bench Pro. On SWE-Bench Pro, model scores cluster within roughly a 30-point range; on DeepSWE, scores span from GPT 5.5's 70% at the top to Claude Haiku 4.5's 0% at the bottom. This high differentiation is exactly what a good benchmark should deliver — in statistics, a good test should effectively distinguish between subjects of different ability levels. If all participants' scores cluster within a narrow range, the test itself provides very limited information.
Efficiency and Cost: GPT 5.5's Triple Advantage
Beyond leading in scores, GPT 5.5 also excels in efficiency and cost.
In terms of token consumption, Opus 4.7's median output token count per problem is 60,000, while GPT 5.5 needs only 16,000 — less than a third. This means GPT 5.5 delivers better answers with far less "thinking."
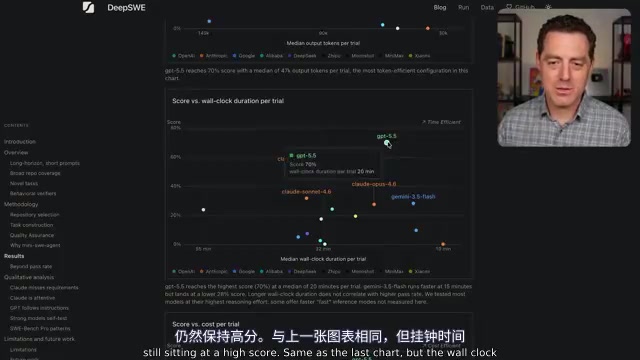
In terms of time, GPT 5.5's wall clock time per trial is approximately 20 minutes, while Opus 4.7 takes 37 minutes. Gemini 3.5 Flash edges ahead slightly at 15 minutes, but its score is only about 40% of GPT 5.5's.
Wall clock time refers to the actual elapsed time from task start to completion, including model inference, API call latency, code execution, and all other steps — it's the core metric for measuring end-to-end efficiency. In real development scenarios, the time a developer waits for an AI to complete a code fix directly impacts workflow efficiency — a tool that takes 37 minutes to return results can break a developer's flow state during fast-paced development iterations. Token consumption reflects a model's "reasoning density" — outputting 60,000 tokens means the model generates extensive intermediate reasoning steps or redundant code, while completing the same task in 16,000 tokens indicates more refined and efficient reasoning. From a cost perspective, LLM APIs typically charge per token, so token consumption directly determines the cost per call. Opus 4.7's high token consumption partly stems from the Claude model family's tendency toward an "expanded thinking" reasoning style, which can improve accuracy in some scenarios but did not translate into higher pass rates in DeepSWE's tests.
In terms of cost, the data is quite embarrassing for Anthropic: GPT 5.5 costs approximately $5.80 per trial, while Opus 4.7 runs close to $16 — nearly 3x the price for a lower score. Gemini 3.5 Flash is priced similarly to GPT 5.5 but scores less than half as much.
Across all three dimensions — score, speed, and cost — GPT 5.5 demonstrates a comprehensive advantage on DeepSWE.
A Paradigm Shift in Prompting
DeepSWE's prompt design philosophy deserves deeper discussion. Its prompts closely mirror how developers naturally converse with AI — focused on behavior descriptions, short and direct, without lengthy interface definitions.
This reflects an important trend in AI programming: Don't tell the model how to solve the problem — tell it what problem you want solved. Describe the desired application behavior rather than prescribing specific code changes. The model needs to autonomously explore the codebase, understand context, locate the issue, and implement a fix.
This behavior-oriented prompting represents a significant evolution in AI programming interaction. Traditional AI programming prompts often include detailed technical specifications — specifying which file to modify, which API to call, what data structure to use — essentially leaving most of the solution-design thinking to the human. Behavior-oriented prompts describe only the desired end behavior (e.g., "make this API automatically retry after timeout"), delegating codebase exploration, context understanding, and solution design entirely to the model. This approach places higher demands on the model's code comprehension and agentic capability — the model needs to act like a newly onboarded developer, first reading and understanding the existing codebase architecture, then locating the problem and implementing a fix. This is also why DeepSWE's prompts are shorter yet solutions require more code: the model must independently complete the entire pipeline from problem understanding to solution implementation.
Model Behavior Differences: Interesting Findings
DeepSWE also reveals behavioral characteristic differences across model families in programming tasks:
- Claude tends to forget multi-part requirements: When a prompt requires implementing multiple parallel behaviors (e.g., "support both sync and async"), Claude often implements only the obvious branch and forgets to mirror changes to other parts. This phenomenon may be related to Claude's attention allocation mechanism when processing long contexts — when prompts contain multiple parallel requirements, the model's attention weights may concentrate unevenly on the first-appearing or most prominent requirement.
- Claude excels at environment awareness: When prompts don't match the actual repository state, Opus 4.7 proactively explores recent changes via git log, recovering the correct solution from Git history. This demonstrates Claude's advantage in tool use — it can flexibly employ shell commands to obtain additional context rather than relying solely on information given in the prompt.
- GPT strictly follows instructions: GPT 5.5 has the lowest rate of missed requirements across all configurations. It strictly generates patches according to the prompt and visible code contracts. This "instruction fidelity" is especially critical in complex multi-step programming tasks, as missing any single requirement can cause verification failure.
- Stronger models tend to self-verify: Unless the prompt explicitly prohibits it, stronger models proactively write tests for their own code — which is itself part of a high-quality solution. This behavior reflects that models have internalized software engineering best practices: the philosophy of Test-Driven Development (TDD) holds that writing tests is not just a verification method but also a thinking tool that helps developers clarify requirements and design.
Limitations and Outlook
You may not have noticed, but DeepSWE uses a unified MiniSuiteAgent as its test scaffold, meaning Opus 4.7 was not tested in its optimal companion environment, Claude Code. This may underestimate Opus's actual performance to some degree, but it also more purely reflects the model's inherent capabilities.
In AI programming evaluation, an agent scaffold manages the interaction between the model and the code environment — including file I/O, command execution, context window management, and more. Different agent frameworks can significantly impact model performance: for example, Anthropic's Claude Code features custom tool-calling strategies and context management mechanisms tailored for Claude models, better leveraging Claude's long-context understanding strengths. While using MiniSuiteAgent as a unified framework ensures fairness (all models compete under identical conditions), it also means some models cannot leverage their proprietary optimizations. This is analogous to having all race car drivers compete in the same car — it tests driver skill rather than vehicle performance, but in real-world applications, the "driver + vehicle" combination is what users actually care about.
Additionally, the current leaderboard lacks data for newer models like Composer 2.5, which, according to multiple evaluations, may also be extremely competitive in terms of cost-effectiveness.
Overall, DeepSWE represents a significant advancement in AI programming benchmarks. It not only better approximates real-world usage scenarios but also, for the first time, quantitatively confirms the developer community's "gut feeling" — GPT 5.5 genuinely leads in practical programming tasks. As more models are included in testing and more programming languages and task types are covered, DeepSWE is poised to become the new standard for evaluating AI programming capabilities. For developers, the core message from this benchmark is clear: when choosing AI programming tools, don't just look at scores on traditional leaderboards — also consider a model's comprehensive performance in real-world scenarios, including the balance of accuracy, efficiency, and cost.
Related articles
AI Full-Stack Development Architecture: A Three-Layer Progressive Path from Prototype to Production
A detailed guide to AI full-stack development architecture covering Node.js+TypeScript+Monorepo engineering, Docker CI/CD deployment, and AI engine design with interview tips.
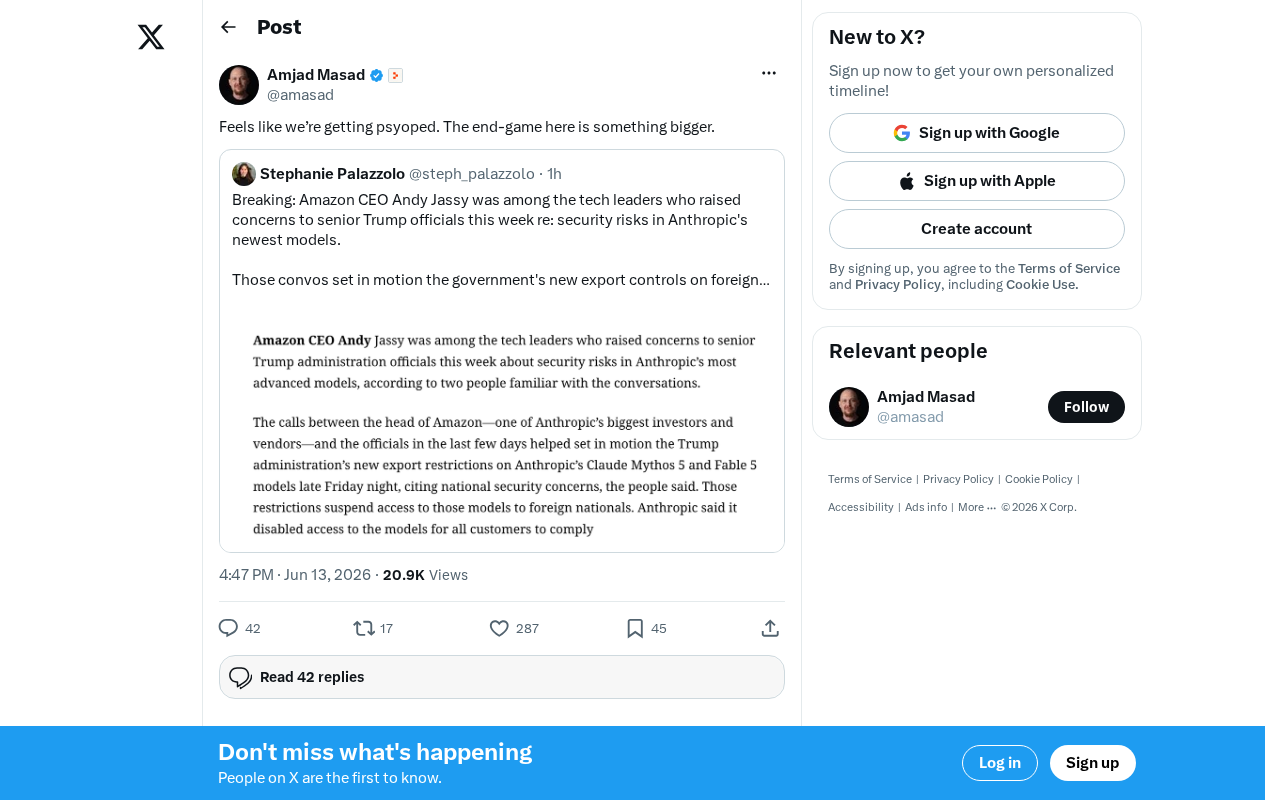
The AI Industry's Psychological Warfare: Narrative Manipulation, Ecosystem Lock-In, and the Endgame
Behind the AI industry's relentless product launches and narrative building lie deeper battles over data monopolies, ecosystem lock-in, and expectation management. A deep dive into the psyop phenomenon.
ByteDance Codex Chinese Manual: An In-Depth Guide to AI-Powered Programming
In-depth analysis of the ByteDance Codex Chinese Manual covering multi-language support, prompt standards, context management, and practical templates for AI programming.