#mini-SWE-agent
3 related articles
·1 min
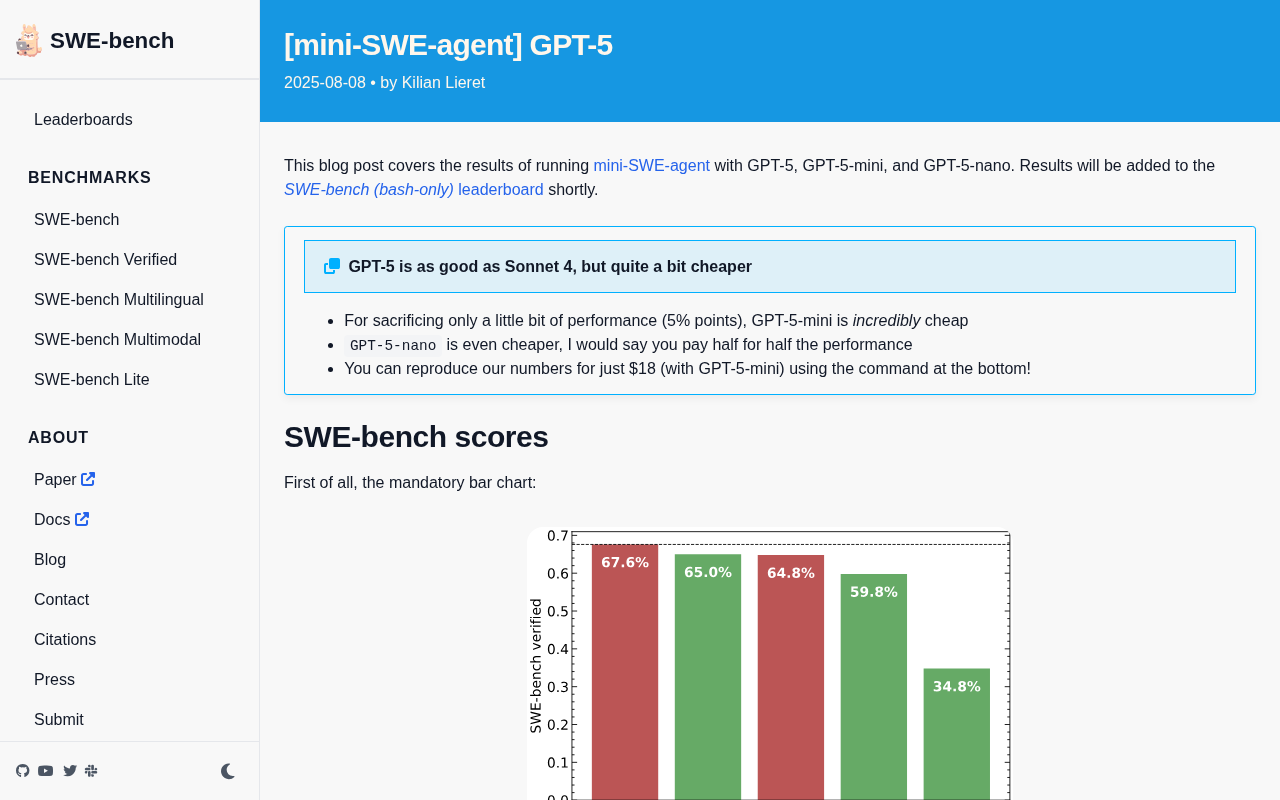
GPT-5 SWE-bench Evaluation: GPT-5-mini Crushes the Competition on Cost-Effectiveness vs Claude Sonnet 4
mini-SWE-agent's GPT-5 series evaluation on SWE-bench shows GPT-5 matches Claude Sonnet 4, while GPT-5-mini loses only ~5 points at less than 1/5 the cost.
Read more →
·2 min
SWE-bench Multilingual: A Comprehensive Guide to the Multi-Language Programming Benchmark
A deep dive into SWE-bench Multilingual benchmark covering 9 programming languages, 300 real GitHub tasks, its design methodology, language distribution, evaluation metrics, and significance for AI coding assistants.
Read more →

·2 min
mini-SWE-agent Roulette Mode: Why Randomly Switching Between LLMs Actually Performs Better
SWE-agent team finds mini-SWE-agent randomly switching between GPT-5 and Claude Sonnet 4 outscores either model alone on SWE-bench. Exploring the diversity hypothesis behind Roulette Mode.
Read more →