GPT-5 SWE-bench Evaluation: GPT-5-mini Crushes the Competition on Cost-Effectiveness vs Claude Sonnet 4
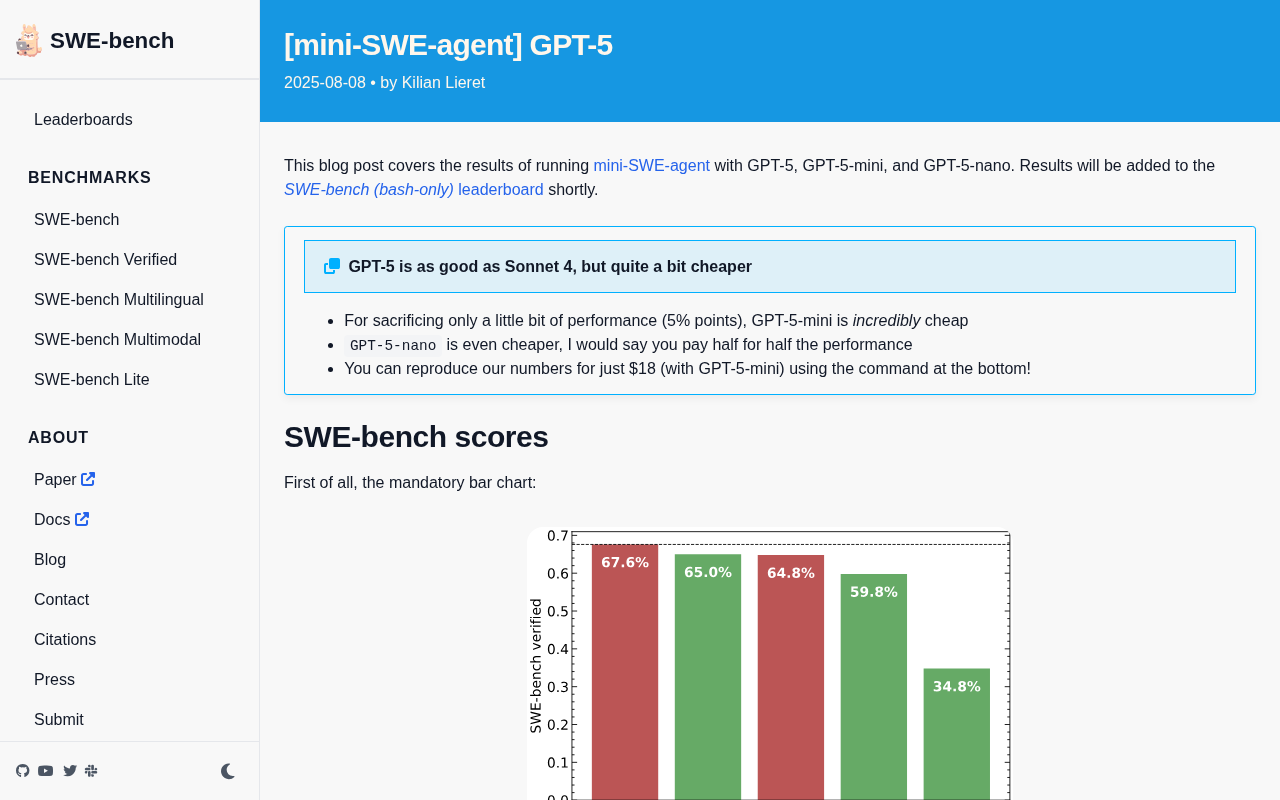
GPT-5-mini delivers near-Sonnet 4 coding performance at less than one-fifth the cost on SWE-bench.
The mini-SWE-agent team evaluated GPT-5, GPT-5-mini, and GPT-5-nano on SWE-bench. Results show GPT-5 matches Claude Sonnet 4 while Claude Opus 4 remains the top performer. The standout finding is GPT-5-mini, which loses only ~5 percentage points of performance at less than one-fifth the cost of Sonnet 4, making it the optimal choice for large-scale coding Agent deployments.
How do OpenAI's newly released GPT-5 series models perform on software engineering benchmarks? The mini-SWE-agent team conducted a systematic evaluation immediately after launch, and the results are surprising—GPT-5's performance is on par with Claude Sonnet 4, but the real highlight is its stunning cost-effectiveness, especially GPT-5-mini, which can only be described as a "price killer."
SWE-bench Evaluation Results: Claude Opus 4 Remains King
mini-SWE-agent is a minimalist yet highly effective software engineering Agent framework that solves programming tasks by having LLMs interact with a Linux shell. The team used this framework to test GPT-5, GPT-5-mini, and GPT-5-nano on the SWE-bench (bash-only) benchmark.
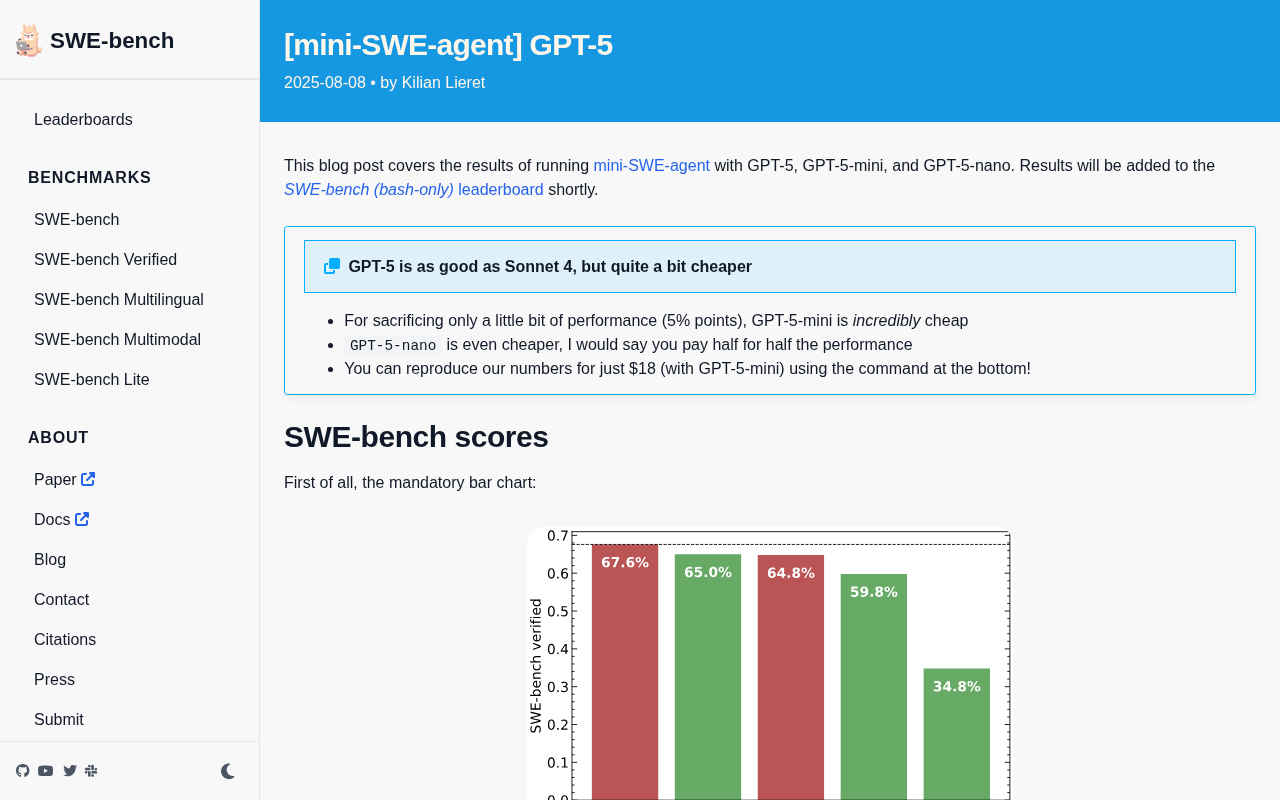
Key findings:
- Claude Opus 4 remains the undisputed champion, maintaining the highest score on SWE-bench
- GPT-5 is essentially on par with Claude Sonnet 4, with minimal performance gap between the two
- GPT-5-mini sacrifices only about 5 percentage points of performance, but at dramatically lower cost
- GPT-5-nano is even cheaper, roughly "half the money for half the performance"
One thing you might not have noticed: all GPT-5 series models used default settings (reasoning verbosity and reasoning effort both set to medium), while Sonnet 4 used zero temperature settings. This differs from the evaluation approach in OpenAI's official blog, which uses the Agentless system—Agentless is essentially a RAG-based system that proposes multiple "one-shot" edit solutions and selects the best one, whereas mini-SWE-agent is a truly interactive Agent.
GPT-5 Cost Analysis: The Agent's "Fail Fast on Success, Slow on Failure" Characteristic
In Agent evaluations, cost analysis is far more complex than simple API call pricing. The mini-SWE-agent team highlighted a key insight: Agents are fast when they succeed, but continue consuming resources when they fail.
For fair comparison, all models ran under constraints of a $3 budget and 250-step limit. In practice, however, most successful tasks completed before 50 steps. The team's step-performance curves revealed several important patterns:
Diminishing Returns Effect in the GPT-5 Series
GPT-5 series models show strong diminishing returns after approximately 30 steps. The team explicitly recommends: Do not let GPT-5 series models run beyond 50 steps, as additional steps yield almost no performance improvement and only increase costs.
By contrast, Claude Sonnet 4 requires more steps to reach peak performance, not fully saturating until around 100 steps. This means Sonnet 4 may have stronger "endurance" on complex problems, but it also means higher per-task costs.
GPT-5-mini: The Cost-Effectiveness King for Coding Agents
When we analyze performance and cost on the same chart, GPT-5-mini's advantage becomes extremely clear:
- GPT-5 is cheaper than Sonnet 4, with exact savings depending on how much you value marginal performance
- GPT-5-mini is the real winner—its maximum cost is less than one-fifth of Sonnet 4's, with only about 5 percentage points of performance loss
- The entire SWE-bench evaluation using GPT-5-mini can be reproduced for just $18, an unimaginably low cost by previous standards
mini-SWE-agent's Minimalist Agent Design Philosophy
Another highlight of this evaluation is the design of mini-SWE-agent itself. Unlike complex systems such as Agentless, mini-SWE-agent's core code is extremely concise—the entire Agent is a single Python class with clear core logic:
- Query the model to get the next action
- Parse the action to extract bash commands from the model's response
- Execute the command in the environment
- Return observations by feeding execution results back to the model
- Loop until the task is complete or limits are reached
The benefit of this minimalist design: it doesn't require specially designed RAG pipelines for each programming language, nor complex candidate solution generation and selection mechanisms. The Agent only needs to interact with the shell, solving problems through a natural explore-edit-verify loop.
The prompt design in the configuration file is also worth noting: the system prompt requires the model to include a THOUGHT section (explaining the reasoning process) and exactly one bash code block in each response, using explicit format examples and boundary constraints to ensure controllable Agent behavior.
Practical Implications for Developers: How to Choose a Coding Agent Model
This evaluation has several important implications for real-world applications:
Model selection strategy: If you're building a coding Agent or automated development tool, GPT-5-mini is likely the best default choice. It strikes an excellent balance between cost and performance, particularly suited for scenarios requiring large-scale execution (such as automated fixes in CI/CD, batch code reviews, etc.).
The importance of step limits: Don't blindly increase an Agent's running steps. For the GPT-5 series, setting a 50-step cap is reasonable; beyond this threshold, you're just burning money rather than solving problems.
Agent vs RAG approach trade-offs: mini-SWE-agent's results demonstrate that even a minimalist Agent architecture, paired with a powerful foundation model, can achieve performance comparable to complex RAG systems. This lowers the barrier to building programming assistance tools.
Conclusion
The GPT-5 series' performance on SWE-bench proves that OpenAI has caught up with Anthropic's Sonnet 4 in model capability while achieving a significant breakthrough in cost efficiency. Claude Opus 4 remains the performance ceiling, but for most practical application scenarios, GPT-5-mini delivers "good enough" performance at extremely low cost, potentially redefining the economic model of AI programming tools. As these results are added to the SWE-bench leaderboard, we look forward to seeing more innovative applications built on these models.
Related articles
NVIDIA ACE SDK: On-Device AI Inference for Intelligent Game NPC Companions
Deep dive into NVIDIA ACE Game Agent SDK's integration with Unreal Engine 5, exploring how on-device AI inference enables low-latency, privacy-safe intelligent NPC dialogue and behavior.
Sakana AI Launches Marlin: An AI Agent…
Sakana AI Launches Marlin: An AI Agent That Autonomously Completes Strategic Research in 8 Hours
Sakana AI launches Marlin, its first commercial product — an autonomous strategic research assistant that completes deep research in 8 hours, targeting finance, consulting, and think tanks.
NVIDIA Halos Explained: Full-Stack Functional Safety System Architecture for Physical AI Robots
Deep dive into NVIDIA Halos for Robotics' full-stack functional safety architecture, covering hardware redundancy, safety runtime, behavior monitors, and how safety envelopes constrain AI uncertainty for scalable physical AI deployment.