返回播客列表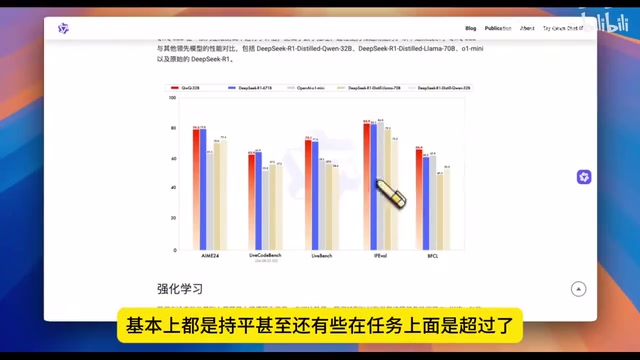
深度解读·5:48·对话
阿里QwQ-32B开源:32B参数如何媲美671B的DeepSeek R1
阿里开源推理模型QwQ-32B仅用32B参数,在多项基准测试中媲美甚至超越DeepSeek R1满血版(671B)。本文深度解析其两阶段强化学习训练策略、性能对比数据,以及强化学习带来的能力涌现现象,揭示小参数模型以小博大的核心秘密。
收听播客对话
0:005:48
最近AI圈有个事儿挺炸裂的——阿里开源了一个叫QwQ-32B的推理模型,32B参数,也就是320亿参数。结果在各种基准测试里,跟DeepSeek R1满血版打得有来有回,部分任务还反超了。要知道DeepSeek R1可是671B参数,6710亿。这差了将近20倍啊。
对,这个事情确实让很多人挺意外的。你看我们之前一直有个根深蒂固的观念,就是OpenAI在2020年提出的Scaling Law嘛,模型越大、数据越多、算力越猛,效果就越好。QwQ-32B的出现其实是在说——嘿,这个定律的边界没你想的那么死。
不过我得替听众问一句,这个对比是不是有点不太公平?因为DeepSeek R1用的是MoE架构,就是混合专家架构,虽然总参数671B,但每次推理的时候实际激活的参数大概只有37B左右。
这个问题问得好。确实,MoE架构的特点就是不是所有参数都同时工作的,每次推理只激活一部分专家网络。所以从激活参数量来看,37B对32B,其实差距没那么夸张。但你要注意,QwQ-32B的总参数量就是32B,它是一个密集模型,所有参数都在干活。而且从部署成本来看,671B的模型你就算用MoE,完整跑起来也得好几张A100或者H100,硬件成本几十万起步。但32B的模型量化之后,一张RTX 4090就能跑,这个差距是实打实的。
这就很有意思了。那它到底是怎么做到的?阿里好像也没发正式论文,就写了一篇很短的博客?
对,227个字的博客,非常精炼。但核心思路其实很清楚——两阶段强化学习。这是关键中的关键。我们知道传统大模型训练一般是先预训练,再做监督微调,最后可能加一点RLHF来对齐人类偏好。但QwQ-32B把强化学习的地位大幅提升了,不再只是最后的调味料,而是变成了主菜。
两个阶段分别是什么?
第一阶段特别聪明,它只在数学和编程这两类任务上做强化学习。为什么选这两个?因为它们的答案可以被精确验证。你想啊,1加1等于2,代码跑一下测试用例就知道对不对。这意味着你根本不需要额外训练一个奖励模型,也不需要人工标注,系统自己就能判断模型做得对不对。这个奖励信号是非常干净、非常准确的。
嗯,这个逻辑我理解。如果一上来就在写作、对话这种开放性任务上做强化学习,你怎么判断模型写得好不好呢?得靠另一个模型来打分,而那个模型本身可能就有偏差。
没错,这就是所谓的奖励黑客问题——模型不是真的变强了,而是学会了讨好评委。所以先在数学和编程上打好推理基础,是一个非常聪明的课程设计。你可以把它想象成练武功,先把内功心法练扎实了,再去学各种招式,事半功倍。
那第二阶段呢?
第二阶段就是把强化学习扩展到通用领域了。这时候用了两种验证机制:一种是通用奖励模型,专门用来评判写作、对话这类开放性任务的输出质量,这个奖励模型是基于人类偏好数据训练出来的;另一种是基于规则的验证器,主要检查输出格式对不对,比如思考过程有没有放在thinking标签里,JSON格式合不合规之类的。
我觉得这里面最让我兴奋的其实是阿里团队发现的一个现象——强化学习居然不会导致灾难性遗忘。这个你能展开说说吗?
这个发现确实非常有价值。做过模型微调的人都知道,灾难性遗忘是个老大难问题。比如你拿医学数据去微调一个通用模型,医学问答能力上去了,但写代码、做数学题的能力可能就掉下来了。这是因为微调的时候,新的权重更新会覆盖掉之前学到的知识。但QwQ-32B在强化学习过程中,加入通用领域的训练后,其他能力不仅没掉,还出现了协同提升。比如写作能力提升的同时,聊天能力也跟着变好了。
这背后的原因是什么?为什么强化学习就不会有这个问题?
其实目前还没有完全定论,但一个比较合理的解释是——强化学习优化的是策略层面的决策能力,而不是简单地去拟合某个特定的数据分布。你可以这么理解,监督微调像是让模型死记硬背一套新教材,背多了就把旧教材忘了。而强化学习更像是在教模型一种思维方式,这种思维方式是通用的,所以对已有知识的破坏更小。
这个类比很好。那如果我们往大了看,QwQ-32B的成功对整个行业意味着什么?
我觉得至少有三点。第一,参数量不再是唯一的竞争维度了,训练策略和数据质量可能比单纯堆参数更重要。第二,强化学习正在成为推理模型训练的核心范式,从DeepSeek R1到QwQ-32B,这个趋势越来越明显。第三,也是对普通开发者最实际的——高性能推理模型的门槛大幅降低了。32B模型量化后大概16到20GB显存就能跑,一张消费级显卡就够了。而且它是Apache 2.0开源协议,商用也没有法律障碍。
对企业来说还有一个很重要的点——本地部署意味着数据不用传到云端,隐私和合规问题从根本上就解决了。
完全正确。其实你把这些点串起来看,QwQ-32B验证的不只是一个模型,而是一条路线——小模型通过精巧的训练策略,完全可以释放出大模型级别的能力。这条路线如果被更多团队跟进,接下来开源AI的发展可能会非常有意思。
嗯,从拼参数到拼训练方法,这个转变确实意义深远。好了,今天关于QwQ-32B就聊到这里。一句话总结的话——不是模型越大越好,而是练得越聪明越好。