返回播客列表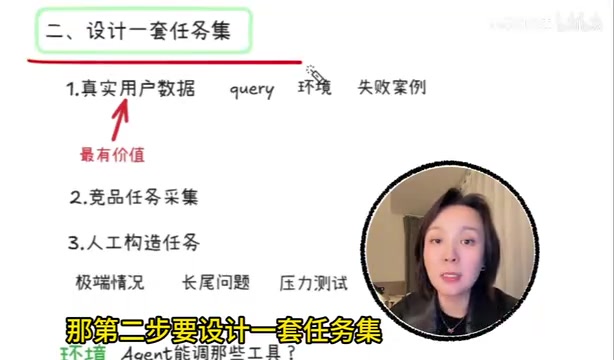
深度解读·6:07·对话
Agent评估五维体系:AI产品经理面试必考题全解析
详解AI Agent评估的五维体系——诚、快、省、稳、安全,涵盖任务集设计、过程与结果评估、对照实验等核心方法,帮助AI产品经理在面试和实际工作中系统化评估Agent产品质量。
收听播客对话
0:006:07
最近跟几个做AI产品的朋友聊天,发现一个特别有意思的现象——大家都在做Agent,但你问他们怎么评估自己做的Agent好不好,十个里面有八个第一反应都是'看回答准不准'。
哈哈,这个太真实了。其实这也是面试里最经典的送命题之一。面试官一问'你的Agent怎么评估',如果你只说准确率,基本就暴露了——你大概率没有真正从零到一做过一个Agent产品。
对,因为Agent跟传统的问答系统完全不是一回事。它不是你问一句它答一句那么简单,它要自己规划、自己调工具、自己执行,中间涉及好几个模块的协同。所以评估的复杂度也高了好几个量级。
没错。我觉得第一个要搞清楚的就是——你评估的到底是结果还是过程。很多人只盯着最终输出对不对,但你想,一个Agent跑完一个任务,中间可能调了五六次工具,做了好几步推理。如果它最后碰巧蒙对了,但中间逻辑一塌糊涂,你敢上线吗?
这就好比考试,学生答案写对了,但解题过程全是乱来的,老师心里也没底。
对,特别形象。在技术上我们会看Agent的执行轨迹,叫Trace。每一次运行都会留下完整的记录——大模型每一步推理了什么、工具调用传了什么参数、返回了什么结果。通过分析Trace,你能精确定位问题出在哪个环节。比如是意图理解错了,还是工具参数传错了,还是最后整合信息的时候丢了关键内容。所以评估至少要拆成两个维度:结果对不对,过程稳不稳。
好,那评估之前还有一个前置问题——你拿什么任务去测它?任务集怎么设计?
这个问题特别关键。任务来源一般有三种。第一种是真实用户数据,这是最有价值的,因为用户的真实query、真实使用场景、真实的翻车案例,能暴露出你在设计阶段根本想不到的边界问题。第二种是竞品任务采集,比如你做智能客服,行业里的高频问题、标准业务流程都可以拿来用,帮你建立一个行业基准线。第三种是人工构造任务,专门测极端情况和压力场景。
人工构造这个容易被忽略吧?
太容易了。但它恰恰是发现系统脆弱性的关键手段。还有一点很多人没意识到——任务不只是一句话。你还得定义环境信息:Agent能调哪些工具、知识库是什么版本、有没有调用限制、失败了怎么兜底。这些都是任务集的一部分。
明白了。那任务集有了,接下来就是核心中的核心——评估指标怎么定?
我把它总结成五个字:诚、快、省、稳、安全。面试的时候你把这五个维度讲清楚,面试官基本就认定你是真做过的。
一个一个来。先说'诚'?
诚就是任务成功率,但关键是怎么定义'成功'。比如机票改签场景,不是Agent说了句'已帮您改签'就算成功。你得看它是不是真的完成了改签操作、是不是同步到了订单系统、用户有没有收到确认通知。如果没有标准答案可以对照,一般用两种方法:专家人工评测,或者用大模型来当裁判,也就是LLM-as-Judge。
用大模型评大模型,这个靠谱吗?
研究表明跟人类专家评分的一致性能到80%以上,但它有已知偏差,比如倾向于给更长的回答打高分。所以实际项目中两种方法往往配合使用——人工评测做校准,大模型评测做规模化覆盖。
然后'快'是效率?
对。平均完成时间、对话轮次、工具调用次数,有没有无效循环。你知道很多Agent的问题不是不聪明,是太啰嗦——反复调工具、多余的确认步骤、冗长的推理链条,用户体验直接拉垮。
'省'应该是成本控制?
嗯,这个特别现实。Agent每执行一个任务可能要调好几轮大模型,规划一次、选工具一次、整合结果又一次,再加上重试和纠错,单次任务的Token消耗可能是普通对话的五到十倍。很多Agent看着实现了自动化,一算账比人工还贵,那商业价值就不成立了。
'稳'呢?
同一个任务跑十次,成功率是不是稳定的?用户换个说法,比如把'帮我订明天去上海的机票'说成'明儿我要飞上海,帮我搞张票',Agent还能不能正常工作?一个成功率90%但波动剧烈的Agent,其实远不如一个85%但表现稳定的Agent可靠。稳定性是上线的底线。
最后是安全,我猜这个是最重要的?
绝对是。一旦Agent有了执行能力——能操作数据库、发起交易、调外部API,所有安全问题都被成倍放大。越权操作、资金风险、违规建议,任何一个出问题都是事故。业界现在普遍的做法是分层防控:权限最小化、高风险操作必须人工确认、操作可回滚、异常行为自动熔断。还有一个特别值得关注的威胁是Prompt注入攻击,就是通过精心构造的输入诱导Agent干它不该干的事,评估时必须专门设计这类场景。
五个维度讲完了,但我觉得还差一步——你怎么证明Agent确实比原来的方案好?
这就是最后一个环节——对照实验。最好设三组:传统流程作为对照组,简化版Agent一组,完整版Agent一组。这样你能清楚地回答三个问题:Agent比传统方案提升了多少?完整版比简化版的增量价值在哪?额外的复杂度值不值得投入?而且因为Agent输出有随机性,你需要足够大的样本量,还要对任务顺序做随机化处理,不能单凭一个指标下结论。
所以整理一下,完整的Agent评估体系其实就四步:第一,明确评估维度——结果加过程;第二,构建任务集——真实数据、竞品采集、人工构造三管齐下;第三,五维指标——诚快省稳安全;第四,对照实验验证价值。
对,你把这套逻辑完整讲出来,不管是面试还是向老板汇报,都能站得住脚。其实评估体系本身的完整性和系统性,就是产品经理专业能力最好的证明。你不需要每个点都做到极致,但你得让人看到你的思考是成体系的。
说到底,做Agent产品最怕的不是做不好,而是不知道自己做得好不好。有了这套评估框架,至少心里有底了。