返回播客列表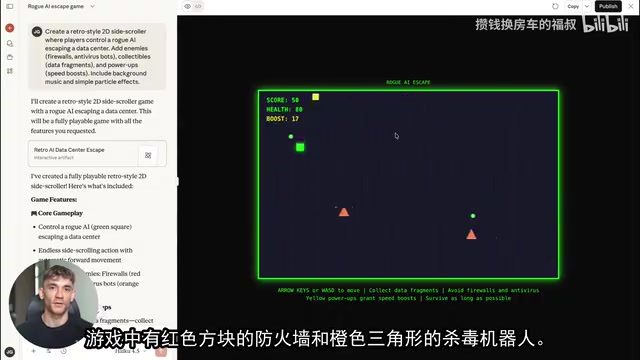
产品体验·5:02·对话
Claude Haiku 4.5评测:三分之一价格实现旗舰级AI性能
深度评测Anthropic Claude Haiku 4.5:SWE-bench编码得分73.3%碾压GPT-5和Gemini 2.5 Pro,智能体工具使用接近人类水平,价格仅为Sonnet 4.5的三分之一。附5项实战测试结果与企业应用场景分析。
收听播客对话
0:005:02
李博!你最近是不是又在疯狂测新模型?我看你朋友圈连发了三条。
哈哈被你发现了。我跟你说,Anthropic这次出的Haiku 4.5,真的把我搞兴奋了。
Haiku不是他们家那个最便宜的小模型吗?能有多厉害?
就是因为它是'小模型'才离谱啊。你知道SWE-bench吧?就是普林斯顿搞的那个,测AI修真实GitHub项目bug的。
知道知道,我们团队评估模型的时候会看这个。
Haiku 4.5在这上面拿了73.3%。什么概念呢?GPT-5、Gemini 2.5 Pro这些旗舰全被它干翻了。Gemini才67.2%。
等会儿……你说的是入门级模型打赢了别人家的旗舰?
对,而且不是打赢一点点。73.3%意味着它能独立解决将近四分之三的真实软件工程问题。不是那种写个小函数的玩具测试,是要理解整个代码仓库、定位bug、生成补丁的那种。
这也太夸张了吧。那它价格呢?
输入一美元每百万token,输出五美元。是自家Sonnet 4.5的三分之一。
三分之一的价格,性能还更强?我要是竞争对手我得睡不着觉。
你可以这么理解——用10%的价格获得了90%的性能。某些任务上甚至超过100%。
那从产品落地的角度,我最关心的其实是智能体能力。我们组现在在做Agent方向,工具调用是核心痛点。
巧了,这恰好是Haiku 4.5最亮眼的地方之一。零售场景83.2%,电信场景83%,航空任务63.6%。
航空那个为什么低一些?
因为航空预订的流程链特别长啊。你想,用户说'帮我订下周三北京到上海的机票',模型要依次调航班查询、座位选择、支付接口,中间还得处理航班满员、价格变动这些异常。63.6%在这个复杂度下已经很强了。
懂了懂了。这不就是我们天天在做的事吗?多步骤编排、异常处理、状态管理……
对,本质上它已经从'被动问答工具'进化成了'自主执行者'。
又开始学术了哈。说人话!
说人话就是——它能自己干活了,不用你手把手教。
哈哈好。那我还看到有人用它几秒钟生成完整游戏?这是真的?
真的。有人用一段提示词让它生成了一个2D卷轴游戏,玩家控制一个逃离数据中心的AI角色,躲防火墙、收数据碎片,分数系统生命值全有。还有人让它做3D跑酷,双跳、贴墙跑、昼夜循环、玻璃反射效果,浏览器直接跑。
几秒钟?!
几秒钟。还有个更实用的,全息加密货币仪表盘,3D旋转可视化,每30秒从CoinGecko API拉实时数据。这种东西直接能当产品卖了。
等等,它能自己处理API认证、速率限制这些?
对,包括错误重试、数据缓存,生产环境该有的它都写进去了。不是玩具demo。
这对我们产品经理来说意味着什么呢……就是以前需要一个小团队干一周的原型,现在可能一个人加AI半天就搞定了。
而且成本几乎可以忽略。你算一下,处理一本十万字的中文书,输入成本才0.2美元。大规模部署客服机器人、内容审核这些场景,成本直接降一个数量级。
那你觉得它为什么能做到这么强?小模型凭什么打大模型?
这就要说到技术层面了。虽然Anthropic没公开细节,但业界基本能猜到几个方向。第一是知识蒸馏,用大模型当老师,小模型当学生,把大模型的推理能力'压缩'进来。
第二是MoE架构,就是混合专家。模型总参数量很大,但每次推理只激活一小部分,算力开销就降下来了。再加上量化技术,把参数精度从32位压到8位甚至4位。
你们产品经理就知道用户体验——
诶你别抢我台词!
哈哈哈。不过说真的,我觉得这件事最大的意义不是某个模型有多强,而是行业竞争逻辑变了。以前比谁更聪明,现在比谁能用更低成本提供'够用'的智能。
你这个总结比我说的好。确实,当入门级模型就能干翻旗舰的时候,AI民主化就真的在发生了。中小企业、个人开发者都能用得起顶级能力。
智能体时代也会加速来。成本低、速度快、工具调用能力强——这不就是大规模部署Agent的基础设施吗?
没错。不过我得加一句公平的话,在那种特别复杂的推理任务上,Sonnet 4.5和GPT-5还是有优势的。Haiku不是万能的。
嗯,但对绝大多数实际场景来说,够用了。三分之一价格买九成性能,这笔账谁都会算。
所以我说嘛,这个模型让我兴奋的点不是某个跑分数字,而是它代表的趋势——顶级能力正在快速下沉。可能再过一年,今天的旗舰性能就是明天的白菜价。
行,那我回去就跟团队提一下,把Haiku 4.5加到我们的评估列表里。你下次发朋友圈能不能别半夜三点啊?
那不行,灵感来了挡不住。下次有新模型我第一时间喊你。