返回播客列表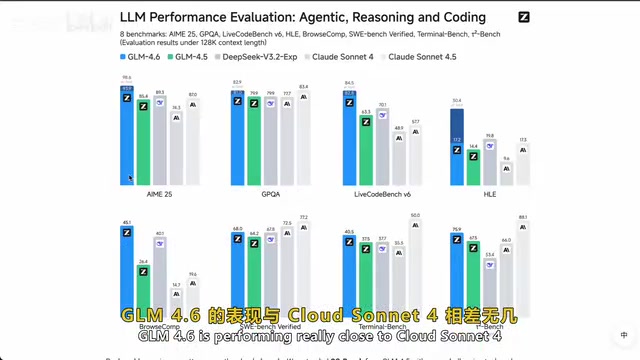
产品体验·4:31·对话
GLM-4.6深度实测:性能、价格与编程能力全面评估
深度实测智谱AI开源模型GLM-4.6,从MoE架构、编程实战、价格对比到适用场景全面解析。输入价格仅$0.06/百万Token,比Claude便宜7-20倍,一次生成代码无需调试,帮你判断是否值得纳入技术栈。
收听播客对话
0:004:31
哎李博,你最近是不是又在疯狂测新模型?我看你朋友圈连着发了三天截图。
哈哈被你发现了。智谱那个GLM-4.6刚出,我手痒忍不住跑了一堆测试。
等等,最近新模型也太多了吧,Claude 4.5刚出,Gemini 3.0也在路上,怎么又来一个?
对,所以这个时间点发布其实挺有意思的。但GLM-4.6打的牌跟别人不一样——它是开源的,而且价格便宜到离谱。
便宜到什么程度?给我一个直观的感受。
这么说吧,输入价格是Claude Sonnet 4.5的二十分之一。输出价格大概是七分之一。
二十分之一?!你确定没看错小数点?
没错,输入每百万Token才6美分,Claude是3美元。你算算,差了五十倍。
好吧这个数字确实震撼到我了。但便宜归便宜,性能呢?不会是那种一分钱一分货吧?
这就是它有意思的地方了。它用了MoE架构,就是专家混合模型。总参数3550亿,但推理的时候只激活320亿。
等会儿让我想想……就是说它其实是个大胖子,但干活的时候只派一小撮精英出来?
哈哈你这比喻很到位。对,你可以理解为一个公司有三千多人,但每个项目只调最合适的三百人来做。知识量是大公司的,但运行效率是小团队的。
这个我懂了。那实际写代码怎么样?我最关心这个,毕竟我们组天天用AI辅助开发。
我跟你说,我测了两个任务。第一个是让它写一个矩阵风格的数字雨动画网页,HTML加CSS加JavaScript全套。
一次生成,直接跑,绿色字符流畅滑落,动画效果完全没问题。零调试。
零调试?这个我得说一句,我们组用Claude写前端有时候还得改两三轮呢。
第二个测试更实用,让它写一个完整的任务管理App。添加、删除、标记完成、筛选,三四十秒全搞定。
三四十秒一个完整App……
而且交互流畅,复选框、状态切换都正常。一次输入完成,不用反复调prompt。
行,那我要泼冷水了啊。听起来太完美了,缺点呢?你们搞研究的不是最爱看benchmark吗?
你这个问题问得好。确实,在SWE-bench这种硬核编码评测上,Claude还是明显领先的。
SWE-bench是什么?翻译一下。
就是从GitHub真实项目里抽Bug,让模型自己定位问题、写修复补丁。考的是真实工程能力,不是刷题。
在这种复杂场景下,GLM-4.6确实还有差距。另外它Token效率偏低,有时候废话多了点。
但它便宜啊!废话多一点,乘以二十分之一的单价,我觉得大部分团队算完账还是赚的。
哈哈你们产品经理果然算账一流。不过你说的没错,对于百分之八十的日常开发场景,这个性价比确实无敌。
那我从产品角度追一个问题——它开源意味着什么?能本地部署对吧?
对,这是另一个大杀器。模型权重完全开放,配合vLLM这些推理框架,企业可以跑在自己的GPU集群上。
数据不出内网,不受API限速,推理成本可预测。金融、医疗、政务这些行业,这一点比什么都重要。
嗯,我们之前做医疗方向的产品确实碰到过这个问题,数据合规卡得死死的,根本不敢调外部API。
对吧。而且它上下文窗口扩到200K Token了,大概相当于一本五百页的书。处理大型代码库完全没压力。
200K……比上一版128K又多了不少。那Agent场景呢?我们组正在搭工作流。
Agent方面它表现很亮眼。工具调用准确、多步骤任务逻辑一致性好。我觉得这是它跟Claude拉开差异化的一个点。
便宜、开源、Agent能力强,还有个月费3美元的编码订阅……这是要把开发者全圈走啊。
你看,它不是要在每个维度上打败Claude,而是找到了一个很务实的定位——够好、够便宜、够自由。
嗯,在工程实践里,'够好且够便宜'确实比'最好但贵死'更有意义。这个道理我做产品三年太懂了。
所以我觉得GLM-4.6真正的意义不只是一个模型,而是证明了开源生态能在性能上逼近闭源,同时成本低一个数量级。这对整个行业都是好事。
行,那我总结一下:复杂编码极致性能选Claude,日常开发、Agent场景、预算敏感就冲GLM-4.6。这个判断没毛病吧?
没毛病。而且它还在迭代,后面只会越来越强。值得持续关注。