返回播客列表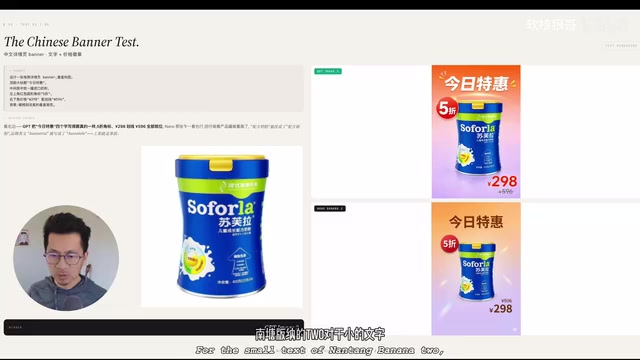
产品体验·6:36·对话
GPT Image 2 vs Nano Banana 2:电商生图实测对比,5大场景谁更强?
实测对比GPT Image 2与Nano Banana 2在电商海报、模特一致性、九宫格展示、场景控制、背景替换5大场景的表现,深入分析中文渲染、文字准确性等关键差异,附选型建议。
收听播客对话
0:006:36
最近电商圈里讨论最多的一个话题——OpenAI新出的GPT Image 2,到底能不能打?尤其是在中文电商这个场景下,它跟之前大家用得比较多的Nano Banana 2比起来,到底谁更强?今天我们就来聊聊这个,我们实际拿了五个典型的电商生图场景做了测试,结果其实挺出乎意料的。
对,说出乎意料是因为很多人觉得GPT Image 2出来以后应该是碾压级别的嘛,但实际测下来不是这样的。两个模型各有各的强项,选哪个完全取决于你做什么品类、什么场景。
嗯,那我们先简单聊聊这两个模型的基础差异吧。速度上我感受最明显——Nano Banana 2确实快不少。
对,Nano Banana 2官方说3到5秒出图,实测会稍微长一点,但确实比GPT Image 2快很多。GPT Image 2慢的原因其实很有意思,它用的是所谓的Thinking Mode,就是在真正画图之前,模型会先'想一想'——构图怎么安排、文字放哪里、元素之间什么关系,想清楚了再动笔。你可以理解为一个画家先打草稿再上色,而不是直接往画布上泼颜料。
这个比喻好。所以它慢是有道理的,不是白慢。
没错,这个机制后面会看到,直接决定了它在文字渲染上的巨大优势。另外价格上GPT Image 2其实更便宜一些。但生态集成方面Nano Banana 2目前领先,它已经接入了Photoshop、Canva、Figma这些设计师常用的工具。GPT Image 2刚出来,主要还是在OpenAI自己的API生态里。所以如果你团队已经建好了基于Canva的工作流,切到GPT Image 2是有迁移成本的。
好,那我们进入正题。第一个测试是电商海报图生成,给一张低分辨率的产品图,让模型生成一张完整的海报。
这个测试两个模型在大标题文字和产品外形还原上都没什么问题,差距出现在小文字上。Nano Banana 2对小字的处理明显不行,会出现笔画错位、字形变异的情况。你想啊,中文跟英文不一样,英文就26个字母线性排列,中文每个字都是一个复杂的结构体,一个笔画画错了,'大'就变成'太'了,意思完全不同。
而且小字本身像素空间就小,模型要在那么小的区域里精确还原每一笔,确实难度很大。
对,GPT Image 2在这方面的突破,我觉得一方面是训练数据里加入了大量中文场景样本,另一方面就是它的Thinking Mode——生成之前先对文字内容做了逻辑校验。所以第一轮,GPT Image 2完胜。
第二个测试是模特角色一致性,就是同一个模特要出现在不同场景的图片里,脸不能变。这个在电商里太常见了。
嗯,这个在技术上叫Identity Preservation,是AI生图领域的老大难问题。以前要实现这个效果,得用LoRA微调或者DreamBooth这些技术,给模型喂一堆照片专门训练。现在这两个模型都在尝试用很少的参考图就实现一致性,这个要求其实非常高。测试结果是,虽然严格来说AI分析认为生成的已经不完全是同一个人了,但从普通消费者的角度看,差别不大。这一轮Nano Banana 2略胜,它的人像质感更好一些。
第三个测试就有意思了——九宫格产品展示图,电商详情页的标配。这个测试直接暴露了一个大问题。
哎,这个真的是让人冒冷汗。Nano Banana 2自己脑补了配方表、营养标签这些我们根本没提供的内容,而且编造了大量虚假文字。你想想,这是奶粉啊!配料表上写什么、营养成分标多少,那是受《食品安全法》和《广告法》严格监管的。模型自己编一个营养标签出来,这要是直接上了详情页,那就是法律问题了。
这就是AI领域说的'幻觉'问题,在文本模型里是编造不存在的事实,到了图像生成里就变成凭空添加不存在的视觉元素。
没错。根源在于我们只给了一张低分辨率的图,信息不够,模型就会根据训练数据里的统计规律去'脑补'。GPT Image 2在这方面克制得多,不会乱加东西。所以这一轮GPT Image 2胜出,不是因为它生成得多好看,而是Nano Banana 2的过度联想带来了不可控的合规风险。
第四个测试是生活场景控制,把产品自然地融入一个生活场景里。
这一轮其实见仁见智。Nano Banana 2生成的场景更有生活气息,就是那种真实的、有人住过的感觉。GPT Image 2呢,更像是精心摆拍的广告片,光线处理很柔和。Nano Banana 2的问题是色调偏暗,不过这个理论上可以通过优化提示词来调整。总体来说这轮Nano Banana 2略占优势。
最后一个终极测试——背景替换后的文字一致性。这个结果太戏剧化了。
哈哈对,这轮简直是名场面。首先小文字处理上,Nano Banana 2重新渲染后出现了大量像'汗渍'一样的伪影。然后数字准确性上,原文写的是'适用于3到14岁儿童',Nano Banana 2给改成了'3到15岁'——它在猜,不是在还原。最离谱的是'乳铁蛋白'四个字,GPT Image 2完美还原了,Nano Banana 2给变成了'灵异之味'。
灵异之味……这要是放到奶粉包装上,消费者看了怕不是要报警。
哈哈哈,真的。这个问题的本质是,图像生成模型处理文字的时候,它是在'画'字,不是在'排版'。它不理解这些字的意思,只是试图在像素层面复现它见过的图案。背景一变,像素分布就得重新推断,就特别容易出错。GPT Image 2靠Thinking Mode在生成前多做了一步语义校验,所以这轮完胜。
好,五轮测下来,GPT Image 2赢了三轮,Nano Banana 2赢了两轮。那实际做电商项目的话,你的建议是什么?
其实很简单——看品类选模型。如果你做的是食品、保健品、母婴这些对标签信息特别敏感的品类,文字准确性是生命线,选GPT Image 2。如果你做的是服装、家居、美妆这些更注重氛围感和人像质感的品类,Nano Banana 2可能更合适。但更重要的是,不要指望一个模型一键搞定所有事情。
你是说模块化工作流?
对,成熟的做法是把流程拆开——先用抠图模型把产品抠出来,再用AI生成背景场景,然后合成到一起,最后用超分模型提升清晰度。每个环节都可以单独优化和质检,可控性比端到端的一键生成高太多了。另外,给模型提供高分辨率的参考图、详细的提示词、多角度的素材,这些都能显著提升效果。AI生图不是魔法,它是一个需要精心喂料才能出好活的工具。
说得好。所以结论就是——没有万能模型,只有适合你场景的模型,再加上一套靠谱的工作流,才能真正在电商生图上跑起来。