返回播客列表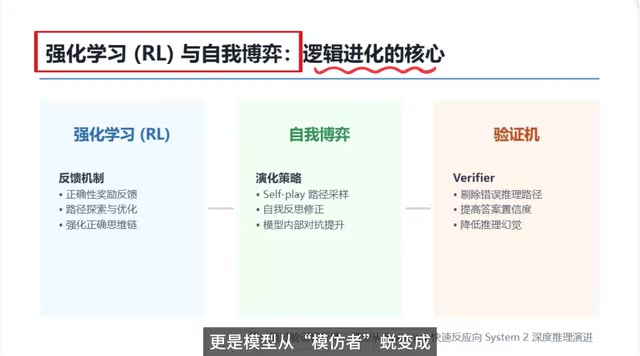
深度解读·0:08·对话
强化学习驱动AI推理进化:从模仿者到真正的思考者
深入解析强化学习(RL)、自我博弈(Self-Play)和验证机如何协同驱动大语言模型推理能力进化,帮助AI从模仿人类逻辑的SFT阶段跃迁到具备自主深度推理的System 2思维模式。
收听播客对话
0:000:08
李博!上次你跟我聊SFT训练那些事儿,我回去琢磨了好几天,越想越觉得有个问题没解决。
深入解析强化学习(RL)、自我博弈(Self-Play)和验证机如何协同驱动大语言模型推理能力进化,帮助AI从模仿人类逻辑的SFT阶段跃迁到具备自主深度推理的System 2思维模式。