强化学习驱动AI推理进化:从模仿者到真正的思考者
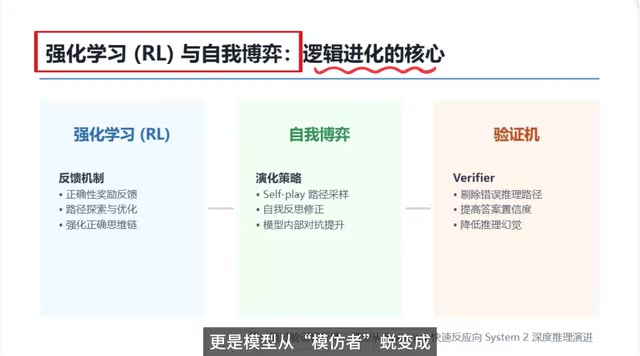
强化学习与自我博弈是推理模型突破SFT模仿天花板、实现深度推理的核心驱动力。
文章指出SFT训练的模型受限于"模仿天花板",难以实现真正的自主推理。要突破这一瓶颈,需要三大核心机制:强化学习通过奖惩反馈引导模型自主探索正确推理路径;自我博弈让模型生成多条候选路径并自我反思修正,形成提升闭环;验证机从训练阶段剔除虚假推理,降低推理幻觉。三者协同驱动模型从System 1直觉反应跃迁至System 2深度推理。
引言:突破SFT的天花板
在推理模型训练系列的前两期中,我们聊过SFT(监督微调)和思维链(Chain of Thought)注入的重要性——高质量标注数据是推理能力的基石。但问题在于,靠标注数据训练出来的模型,说到底只是在模仿人类的逻辑,很难突破数据本身设定的上限。
SFT(Supervised Fine-Tuning,监督微调)的本质是通过人工标注的输入-输出对来训练模型,使其学会模仿标注者的行为模式。这种方法的根本局限在于"模仿天花板"(Imitation Ceiling)——模型的表现上限受限于标注数据的质量和多样性。即使标注者是领域专家,其标注数据也只能覆盖有限的推理模式。更关键的是,SFT训练的模型倾向于学习输入到输出的表面映射关系,而非真正理解推理过程中的因果逻辑。这就是为什么在复杂多步推理任务中,纯SFT模型往往表现出"脆弱性"——稍微改变问题的表述方式或增加推理步骤,模型的准确率就会急剧下降。
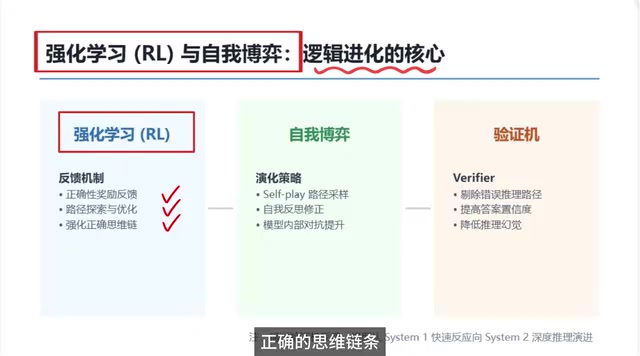
要让模型真正进化,拥有超越模仿层面的自主推理能力,就必须迈入下一个关键阶段:强化学习(RL)与自我博弈(Self-Play)。这是推理模型逻辑进化的核心驱动力,也是模型从"模仿者"蜕变为"思考者"的分水岭。
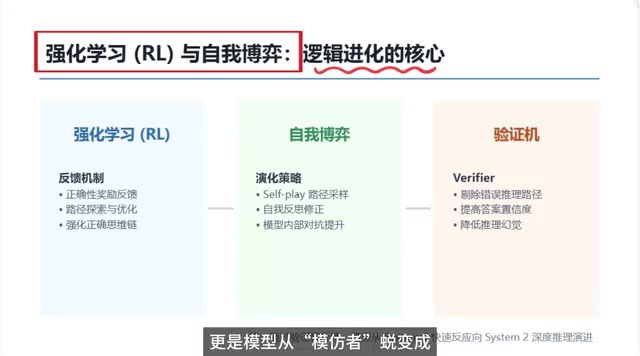
强化学习:推理训练的核心引擎
RL不是简单微调,而是专业陪练
强化学习在推理训练中扮演的角色,和普通微调有本质区别。普通微调更像"死记硬背"——模型看到输入就对应输出,缺乏灵活应变的能力。而强化学习更像一个专业陪练教练,通过奖励反馈机制引导模型自主探索、自主进化。
具体来说,强化学习的工作机制是这样的:
- 正向奖励:对合理、严谨、逻辑通顺的推理路径给予正向激励
- 负向抑制:对混乱、跳跃、错误的逻辑链条进行惩罚
- 迭代强化:通过持续的逻辑探索和正负反馈循环,逐步巩固模型内部正确的思维链条
在推理模型的强化学习训练中,奖励函数(Reward Function)的设计是核心难题之一。常见的方案包括基于结果的奖励(Outcome-Based Reward)和基于过程的奖励(Process-Based Reward)。前者只关注最终答案是否正确,后者则对推理链条中的每一步都给予评分。OpenAI在训练o1模型时采用的正是过程奖励模型(Process Reward Model, PRM),它能对推理的中间步骤进行细粒度评估。主流的RL算法包括PPO(Proximal Policy Optimization,近端策略优化)和更新的GRPO(Group Relative Policy Optimization,分组相对策略优化),后者由DeepSeek团队提出,通过组内相对排序来计算奖励,省去了单独训练价值网络(Critic Model)的开销,显著降低了训练成本。
这个过程的精妙之处在于,模型不再被动地记忆"标准答案",而是在反复试错中学会了如何思考、如何推导。每一次正确的推理路径被强化,每一次错误的逻辑被修正,模型的推理能力就往前迈一步。
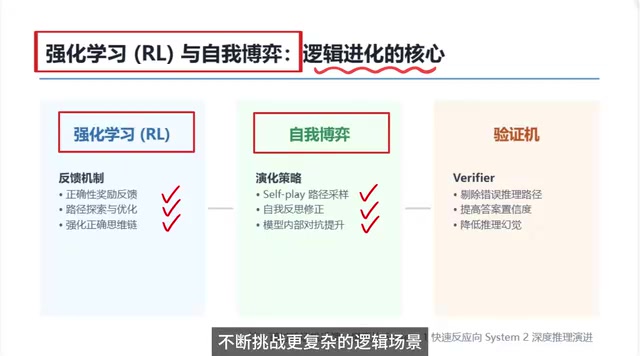
自我博弈:左右互搏的进化之道
模型自己和自己下棋
自我博弈(Self-Play)是推理模型进化的另一大利器。通俗地讲,就是模型自己和自己"左右互搏"。这个概念最早在AlphaGo中大放异彩,如今被引入大语言模型的推理训练,同样展现出惊人的效果。
自我博弈的思想最早可追溯到博弈论和强化学习的交叉领域。2016年DeepMind的AlphaGo通过与人类棋谱学习加自我对弈击败了世界冠军,而2017年的AlphaGo Zero更进一步,完全抛弃人类棋谱,仅通过自我博弈就超越了所有前代版本。在大语言模型领域,自我博弈的实现方式有所不同:模型并非与"对手"对弈,而是通过对同一问题生成多条候选推理路径(通常使用较高的采样温度来增加多样性),然后利用奖励模型或验证机制对这些路径进行排序和筛选。这种方法也被称为"拒绝采样"(Rejection Sampling)或"Best-of-N"策略。DeepSeek-R1的训练过程就大量使用了这种自我博弈机制,让模型在数学和代码推理任务上展现出了涌现式的自我反思能力。
自我博弈的核心流程包括四个步骤:
- 大量路径采样:模型针对同一个问题,生成多条不同的推理路径
- 自主构建思路:在没有外部标注的情况下,模型独立制定推理策略
- 自我反思校验:模型对自己生成的多条路径进行横向比较和评估
- 自我修正错误:发现逻辑漏洞后主动调整和优化推理链条
这种机制在模型内部形成了一种自我对抗、自我提升的闭环。模型不断挑战更复杂的逻辑场景,挖掘更稳健、更有深度的推理策略。就像一个棋手通过自我对弈不断精进棋艺,模型也在自我博弈中持续拓展推理能力的边界。
验证机:推理路径的严格裁判
为什么验证机不可或缺?
在整个进化流程中,还有一个不可或缺的关键角色——验证机(Verifier)。它就像一位严格的专业裁判,专门负责甄别推理路径的真伪和质量。
为什么需要这个角色?因为很多模型生成的推理过程看上去说得头头是道,实际上逻辑漏洞百出,纯属"一本正经地胡说八道"。这就是业内常说的"推理幻觉"问题——模型输出的内容形式上像推理,本质上却经不起推敲。
推理幻觉(Reasoning Hallucination)是比普通事实幻觉更隐蔽的问题。模型可能生成格式完美、用词专业的推理链条,但其中包含逻辑跳跃、循环论证或前提错误等问题。验证机的技术实现主要分为两类:一类是基于规则的验证器(Rule-Based Verifier),适用于数学计算、代码执行等有确定性答案的场景,可以通过执行代码或数学验证来判断结果正确性;另一类是基于模型的验证器(Model-Based Verifier),即训练一个专门的神经网络来评估推理路径的质量。OpenAI提出的过程奖励模型(PRM)就属于后者,它在GSM8K等数学推理基准测试中显著提升了模型的推理准确率。值得注意的是,验证机本身也可能存在偏差,因此业界也在探索多验证器集成和对抗验证等更鲁棒的方案。
验证机的核心职责包括:
- 剔除虚假推理:识别并过滤那些表面合理但逻辑不成立的推理路径
- 从根源降低幻觉:不是在输出端打补丁,而是在训练阶段就把错误逻辑清除掉
- 质量把关:只有经过验证机审核通过的逻辑路径才能保留下来
有了验证机的把关,模型的输出就不再是"碰运气",而是经过严格筛选的严谨逻辑推导。
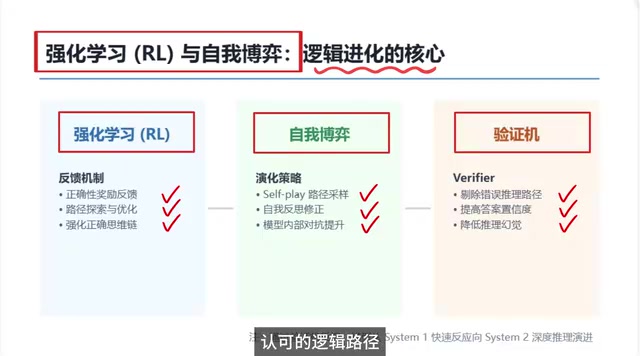
完整闭环:从System 1到System 2的跃迁
反馈-博弈-验证的三位一体
把上面三个核心机制整合起来,推理模型进化的完整闭环就清晰了:
| 机制 | 角色 | 核心作用 |
|---|---|---|
| 强化学习(RL) | 陪练教练 | 通过奖惩反馈强化正确推理路径 |
| 自我博弈(Self-Play) | 对弈伙伴 | 在自我对抗中探索更优推理策略 |
| 验证机(Verifier) | 专业裁判 | 甄别并过滤虚假推理路径 |
正是依靠反馈、博弈、验证这三者构成的完整闭环,模型才能真正完成认知层面的跃迁——从类似心理学中System 1(快速直觉反应) 的模式,进化到 System 2(深度逻辑推理) 的模式。
System 1和System 2的概念来自诺贝尔经济学奖得主丹尼尔·卡尼曼(Daniel Kahneman)的经典著作《思考,快与慢》(Thinking, Fast and Slow)。System 1是快速、自动、直觉式的思维模式,比如识别人脸或完成简单算术;System 2是缓慢、费力、需要集中注意力的深度推理模式,比如解复杂数学题或进行逻辑论证。传统的大语言模型(如GPT-4的标准推理模式)主要运行在类System 1的模式下——一次前向传播直接生成答案,推理深度受限于模型参数中编码的知识。而以OpenAI o1、DeepSeek-R1为代表的推理模型,通过在推理时分配更多的计算资源(即"测试时计算",Test-Time Compute),让模型能够进行多步思考、回溯和验证,本质上是在模拟System 2的深度推理过程。这种从System 1到System 2的跃迁,被认为是通向AGI(通用人工智能)的关键路径之一。
这不只是性能指标上的提升,更是模型思维范式的根本性转变。模型不再只是"快速给出一个看起来合理的答案",而是能够"深入思考、多路径探索、严格验证后给出经得起推敲的答案"。
下期预告
理解了推理训练的底层逻辑之后,下一步我们要关注的是:模型在实际推理时究竟怎么思考和搜索的?下一期将深入拆解思维树(Tree of Thought)的搜索机制,看看模型如何进行多分支探索,以及在走错路时如何自动回溯纠错。敬请期待。
核心要点
- 强化学习通过奖惩反馈机制引导模型自主探索正确推理路径,而非简单模仿标注数据
- 自我博弈让模型通过路径采样、自我反思和自我修正形成自我提升的闭环
- 验证机作为严格裁判,从训练阶段就剔除虚假推理路径,从根源降低推理幻觉
- 反馈-博弈-验证三位一体的完整闭环,驱动模型从System 1快速直觉跃迁到System 2深度推理
- SFT训练的模型只能模仿人类逻辑,RL与自我博弈才是突破推理上限的关键
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。