共 1 篇相关文章
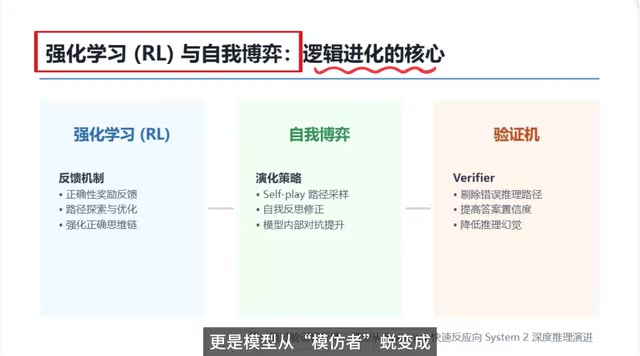
深入解析强化学习(RL)、自我博弈(Self-Play)和验证机如何协同驱动大语言模型推理能力进化,帮助AI从模仿人类逻辑的SFT阶段跃迁到具备自主深度推理的System 2思维模式。