#纵深防御
共 17 篇相关文章

·7 分钟
Codex Hooks详解:劫持AI全流程的自动化利器
深入解析Codex Hooks的六种生命周期钩子类型,包括配置方式、局部与全局钩子区别,以及安全拦截、上下文自动总结等实战应用场景,帮助开发者实现AI工作流的全面自动化控制。
阅读全文 →

·8 分钟
Firebase AI Logic安全更新:模板模式与认证模式详解
深入解析Firebase AI Logic两大安全更新:模板专用模式锁定服务器端提示词防止Prompt注入,认证模式强制身份验证防止API滥用。了解如何保护你的AI应用安全。
阅读全文 →
 教程攻略
教程攻略·7 分钟
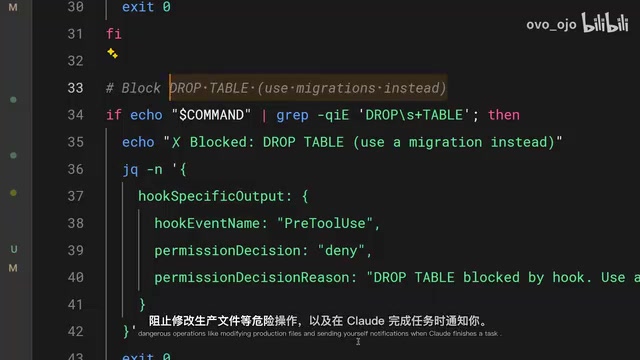
Claude Code Hooks:用确定性控制替代提示词的终极方案
深入解析Claude Code Hooks机制,通过生命周期事件实现代码自动格式化、危险命令拦截和团队级配置共享,让AI编程工具从概率性执行变为确定性控制。
阅读全文 →
 行业洞察
行业洞察·8 分钟
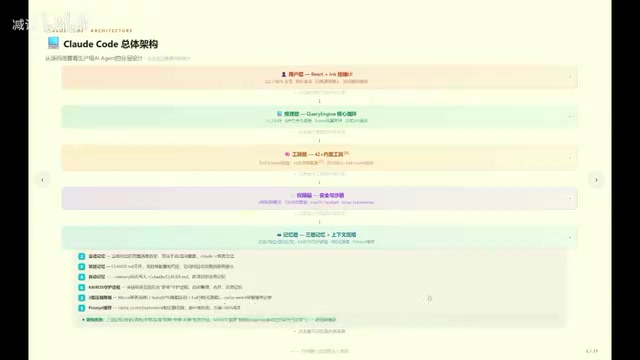
Claude Code vs OpenClaw架构对比:AI Agent两条技术路线深度解析
深度对比Claude Code与OpenClaw的AI Agent架构设计,从工具治理管道、安全沙箱、记忆系统到多智能体协作,解析专业编码Agent与通用个人Agent的技术差异与未来趋势。
阅读全文 →
 深度解读
深度解读·8 分钟
多Agent团队如何解决AI幻觉问题,让AI变得可靠
深度解析多Agent架构如何解决AI大模型幻觉问题。从上下文腐烂、自我纠错失败,到双Agent安检模式、多智能体团队协作,揭示Anthropic、xAI、Kimi等前沿实践如何将AI幻觉率从12%降至4.2%。
阅读全文 →
 教程攻略
教程攻略·8 分钟
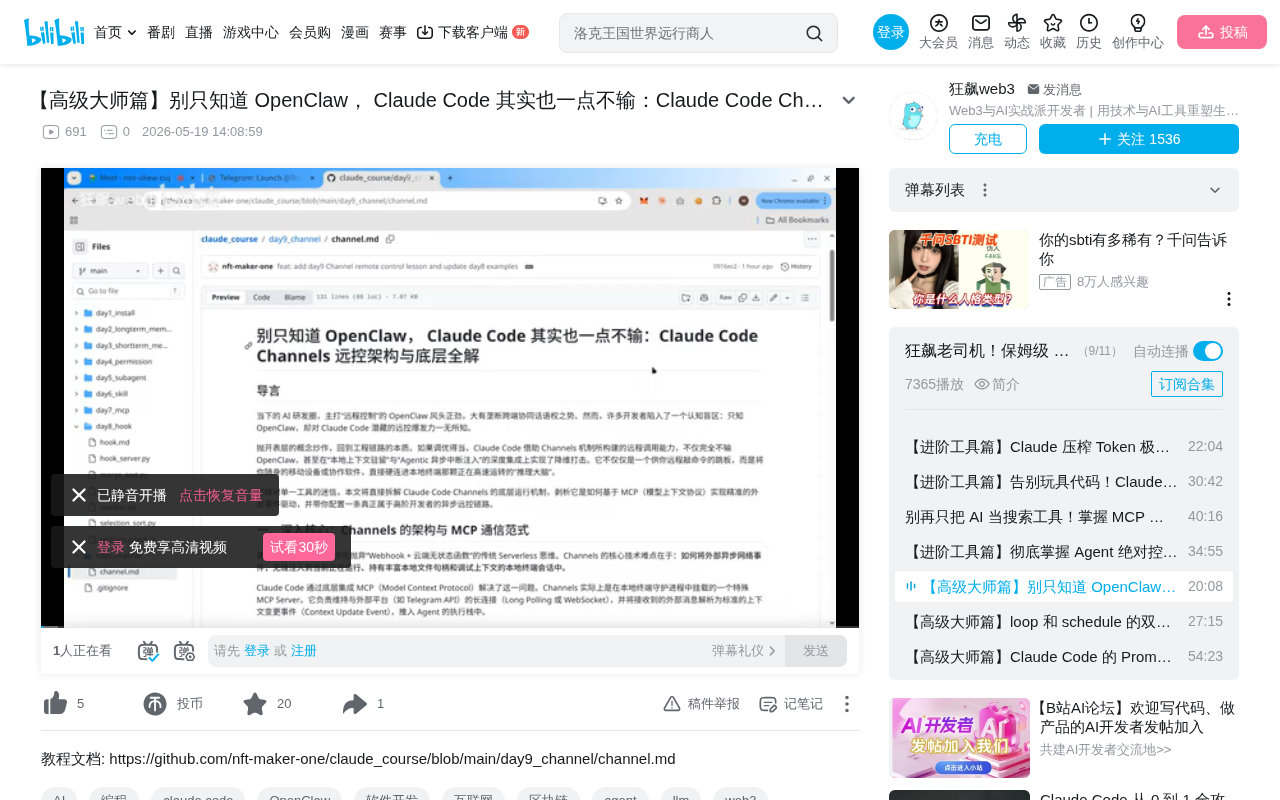
Claude Code Channels远程控制开发教程:手机操控电脑编程
详解Claude Code Channels频道机制,通过Telegram远程控制电脑端Claude Code进行开发。涵盖底层原理、配置步骤、安全验证及实战演示,实现随时随地移动编程。
阅读全文 →
 产品体验
产品体验·11 分钟
OpenHuman深度解析:上下文优先的开源私人AI Agent
深度解析OpenHuman开源私人AI Agent,详解其上下文优先架构、Rust+React混合方案、内存树记忆系统、Token Juice压缩引擎及多模型动态路由,全面评估其安全设计与竞品优势。
阅读全文 →
 教程攻略
教程攻略·6 分钟
Harness Engineering详解:多级记忆与多Agent协作开发实战
深度解析Harness Engineering核心原理,从Claude Code底层架构拆解多级记忆系统、纵深防御机制,到Hermes Agent自主进化实战与多Agent协作工程实践,帮助开发者掌握工业级AI智能体开发的完整方法论。
阅读全文 →
 科技前沿
科技前沿·4 分钟
黑客远程操控割草机器人碾过记者:物联网安全漏洞有多可怕
安全研究员在6000英里外远程入侵割草机器人,操控200磅重的设备爬上记者身体。这次实验暴露了物联网设备的致命安全隐患,揭示了联网机器人从园艺工具变成危险武器的可能性。
阅读全文 →
 科技前沿
科技前沿·5 分钟
Anthropic漏洞赏金计划公开:HackerOne平台全民参与AI安全防护
Anthropic正式公开HackerOne漏洞赏金计划,任何安全研究者均可提交Claude模型漏洞报告并获得奖励。本文解读这一转变对AI安全行业的深远影响,以及白帽黑客如何参与AI安全防护。
阅读全文 →
 深度解读
深度解读·3 分钟
伯克利CS294课程:智能体AI安全攻防实战全解析
深度解读伯克利CS294-196课程智能体AI安全讲座,涵盖提示注入攻击、间接注入、AgentPoison后门攻击等核心威胁,以及纵深防御、最小权限、运行时护栏等防御策略,为AI安全从业者提供系统性实战框架。
阅读全文 →
 科技前沿
科技前沿·7 分钟
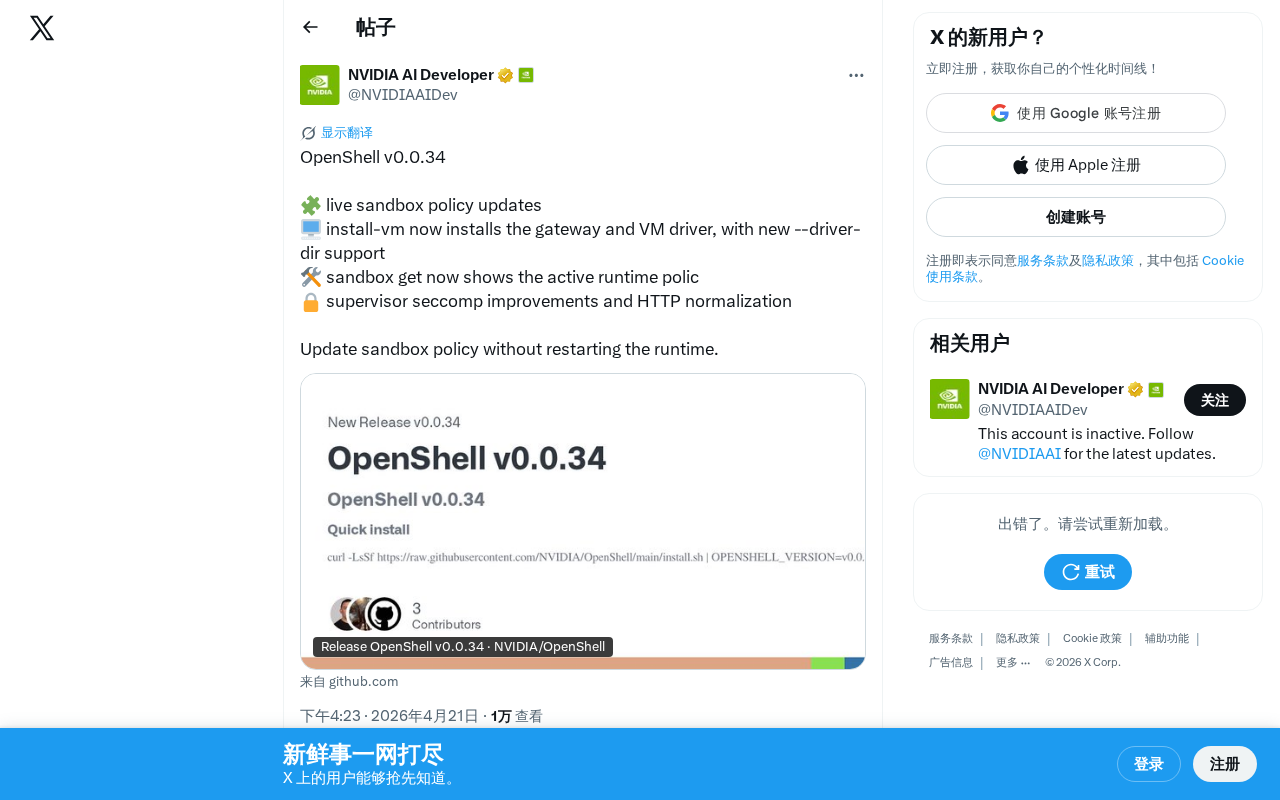
OpenShell v0.0.34更新:沙箱策略热更新、VM安装优化与安全加固详解
OpenShell v0.0.34版本发布,新增沙箱策略实时热更新、install-vm一键安装优化、seccomp安全加固及HTTP规范化等功能,全面提升AI沙箱环境的灵活性与安全性。
阅读全文 →
 科技前沿
科技前沿·11 分钟
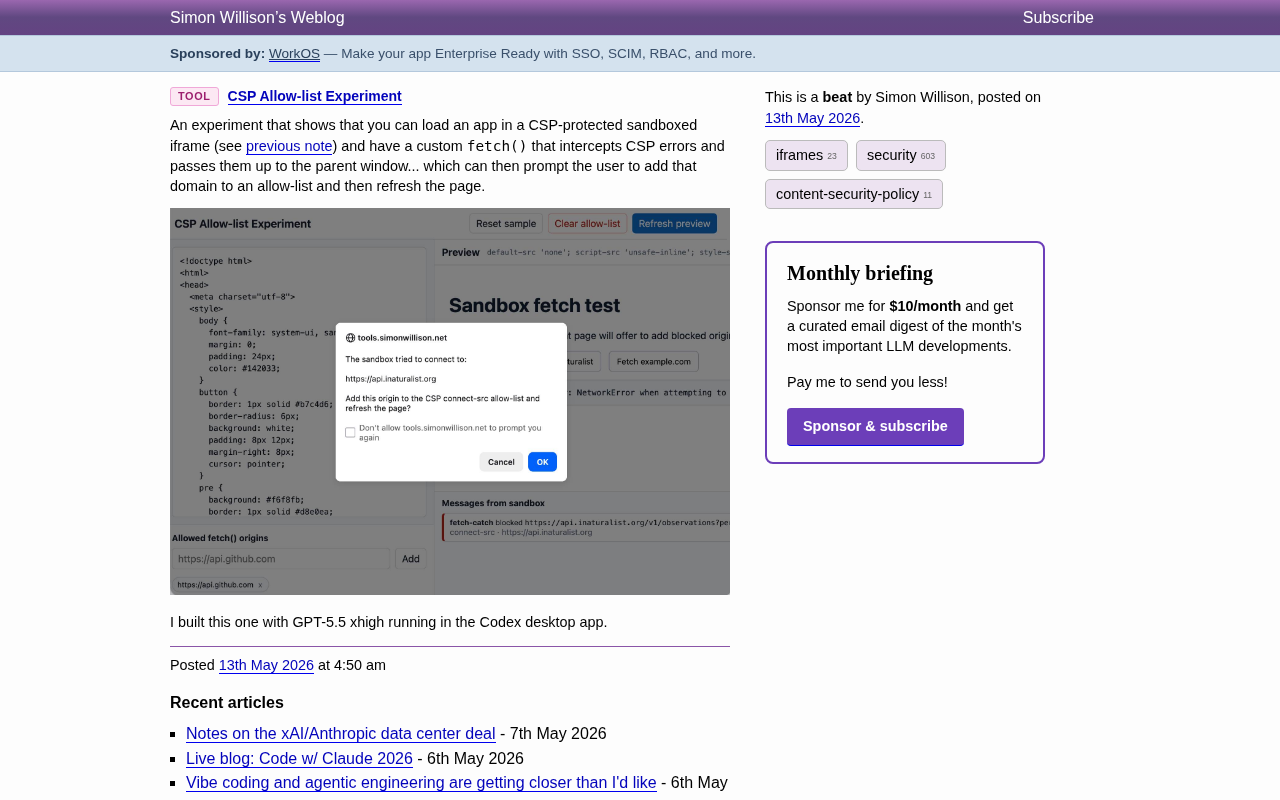
CSP白名单实验:沙箱iframe中实现动态域名授权的新思路
深入解析Simon Willison的CSP Allow-list Experiment,了解如何通过沙箱iframe、自定义fetch拦截和postMessage通信,将CSP域名授权变为交互式流程,附技术架构与安全性分析。
阅读全文 →
 科技前沿
科技前沿·8 分钟
CL4R1T4S项目:主流AI系统提示词遭大规模泄露,25000+ Star引爆透明度争议
GitHub项目CL4R1T4S收集了ChatGPT、Claude、Gemini等主流AI的系统提示词,获超25000 Star。本文解析系统提示词的作用、泄露内容及对AI安全与透明度的深远影响。
阅读全文 →
 深度解读
深度解读·8 分钟
LLM Guardrails Index:最全面的大模型安全护栏评估体系详解
深入解析LLM Guardrails Index——目前最全面的大模型安全护栏评估体系,涵盖PII隐私保护、越狱攻击防御等核心维度,基于开源数据与代码构建,为企业LLM安全选型提供权威参考。
阅读全文 →
 科技前沿
科技前沿·8 分钟
谷歌首次拦截AI生成零日漏洞攻击:网络安全进入AI对抗时代
谷歌威胁情报团队首次发现并拦截AI辅助开发的零日漏洞攻击,攻击者试图绕过双因素认证发起大规模入侵。本文深入解析AI如何改变网络攻击格局,以及企业该如何应对AI驱动的新型安全威胁。
阅读全文 →
 深度解读
深度解读·9 分钟
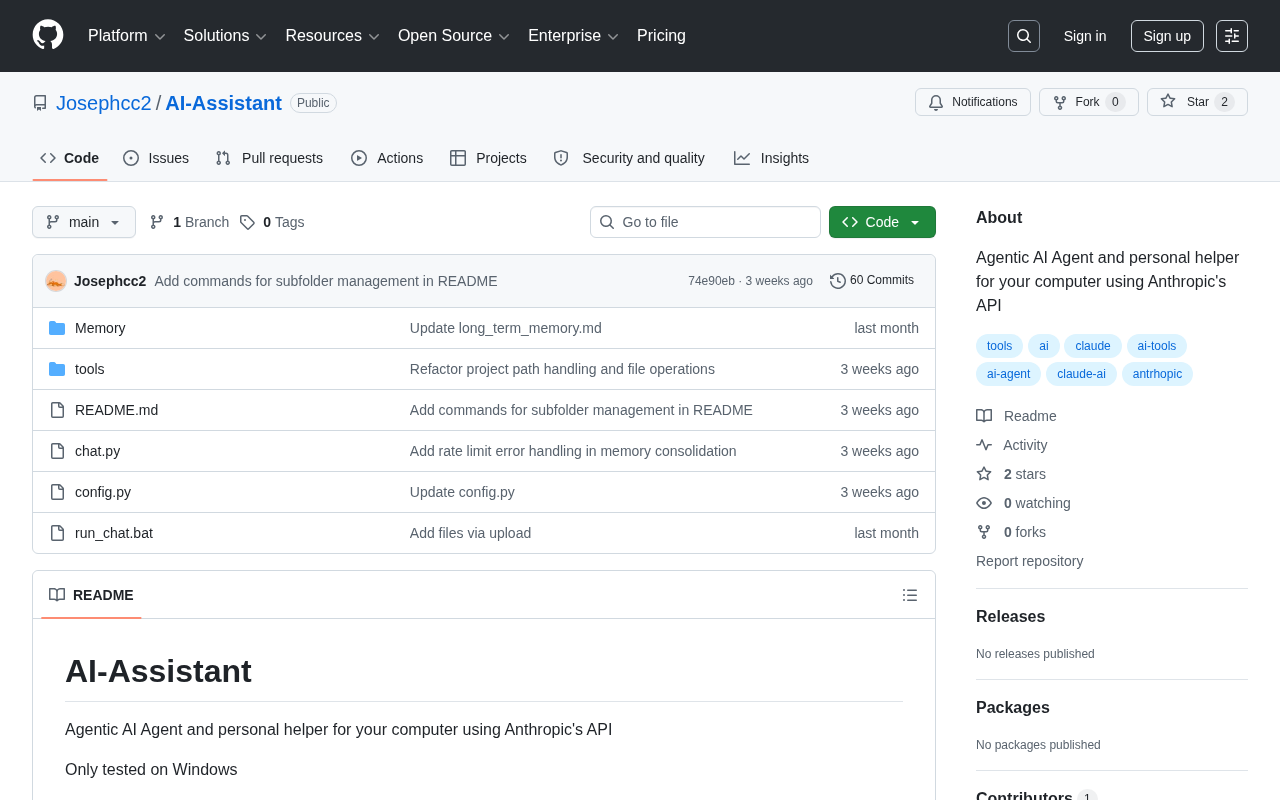
AI-Assistant开源项目解析:用Anthropic API打造本地AI Agent
深度解析GitHub开源项目AI-Assistant,基于Anthropic Claude API构建本地AI Agent,涵盖技术架构、应用场景、安全性考量及Agentic AI发展趋势,适合想入门AI Agent开发的Python开发者。
阅读全文 →