共 2 篇相关文章
深度解析DeepSWE编程基准测试如何揭露SWE-Bench Pro的数据污染和作弊问题。GPT-5.5以70%通过率领先,开源模型差距明显。涵盖测试结果、成本对比与开发者实用建议。
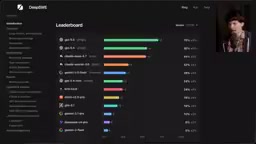
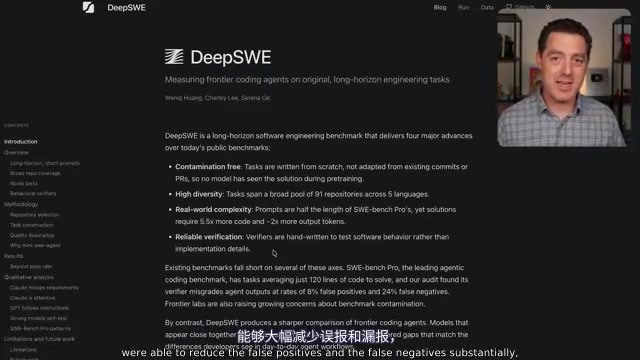
DeepSWE长周期软件工程基准测试显示GPT 5.5以70%通过率领先Opus 4.7超15个百分点,且成本仅为其三分之一。深度解析DeepSWE的无污染验证机制、模型行为差异及对AI编程格局的影响。