DeepSWE基准测试揭示真相:GPT 5.5大幅领先Opus 4.7
软件工程领域的AI基准测试一直饱受争议——大多数榜单无法反映真实的编程场景,模型得分高却不代表实际好用。一个名为DeepSWE的全新基准测试正在改变这一局面,它的测试结果显示GPT 5.5与Opus 4.7之间存在超过15分的巨大差距,颠覆了此前各大榜单上两者"不相上下"的印象。
DeepSWE为何值得关注
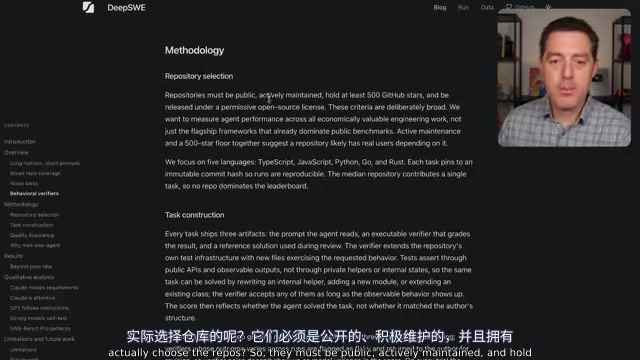
这个由datacurve.ai公司推出的基准测试,被称为"长周期软件工程基准",它在四个关键维度上实现了对现有公开基准的突破。
首先是无污染性。所有测试任务都是从零编写的,而非从GitHub的公开commit或PR中改编。这意味着没有任何模型在预训练阶段见过这些问题的答案。反观SWE-Bench Pro等主流基准,它们大量采用公开代码库的issue和commit,模型很可能在训练中已经"记住"了答案。
数据污染(Data Contamination)是大语言模型评估中最棘手的问题之一。当模型在预训练阶段接触过测试集中的数据时,其在该测试上的表现会被人为抬高,导致评估结果失真。由于GPT、Claude等模型的训练语料通常包含大量GitHub公开代码,任何基于公开仓库构建的基准测试都面临污染风险。SWE-Bench等早期基准从GitHub的Issue和Pull Request中提取任务,模型可能在训练中已经"见过"这些问题及其解决方案,相当于考试前看过了答案。DeepSWE通过从零编写全新任务来规避这一问题,这在方法论上类似于教育测试中的"原创题库"策略。
其次是高多样性。测试覆盖91个代码仓库、5种编程语言(TypeScript、Go、Python、JavaScript、Rust),而非仅仅围绕Python或少数几个大型项目。
第三是真实世界复杂度。DeepSWE的提示词长度仅为SWE-Bench Pro的一半,但解决方案需要5.5倍的代码量和2倍的输出token。这精准模拟了真实开发者的使用方式——大多数人只会告诉AI"修好它",而不会写一大段详细说明。
第四是可靠的验证机制。DeepSWE的验证器将误判率降到了极低水平。
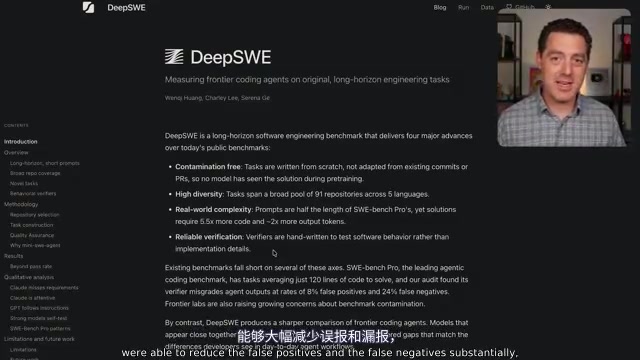
具体数据令人震撼:SWE-Bench Pro的假阳性率为8.5%(验证器接受了错误实现),而DeepSWE仅为0.3%;SWE-Bench Pro的假阴性率高达24%(验证器拒绝了正确实现),DeepSWE仅为1.1%。想象一下,在SWE-Bench Pro中,每4次正确答案就有1次被错误地判为失败。
在自动化代码验证的语境中,假阳性(False Positive)指验证器错误地接受了一个实际上不正确的实现——代码通过了测试但并未真正解决问题,这通常是因为测试用例覆盖不够全面,未能捕捉到边界条件或特定场景下的错误行为。假阴性(False Negative)则指验证器错误地拒绝了一个实际正确的实现——代码逻辑正确但因测试框架的局限性(如对输出格式的过度严格匹配、环境依赖问题等)而被判定失败。SWE-Bench Pro高达24%的假阴性率意味着模型每提交4个正确答案就有1个被误判为错误,这会系统性地压低所有模型的得分,并可能扭曲模型之间的相对排名——如果某个模型恰好更容易触发验证器的误判条件,它的真实能力就会被严重低估。
榜单结果:GPT 5.5全面碾压
在DeepSWE的排行榜上,GPT 5.5以约70%的通过率高居榜首,比Opus 4.7领先超过15个百分点。这与SWE-Bench Pro上两者分数接近的局面形成鲜明对比。完整排名依次为:GPT 5.5、GPT 5.4、Opus 4.7,随后是Sun 4.6、Gemini 3.5 Flash(约28%)等。
更关键的是,DeepSWE在分数分布上呈现出远比SWE-Bench Pro更大的区分度。在SWE-Bench Pro上,各模型的分数集中在约30分的区间内;而在DeepSWE上,从顶部GPT 5.5的70%到底部Cloud Haiku 4.5的0%,分数跨度极大。这种高区分度才是好基准测试应有的特征——在统计学中,一个好的测试应当能够有效区分不同能力水平的被试者,如果所有参与者的得分都集中在一个狭窄区间内,测试本身的信息量就非常有限。
效率与成本:GPT 5.5的三重优势
除了得分领先,GPT 5.5在效率和成本方面同样表现突出。
Token消耗方面,Opus 4.7每次解题的中位输出token数为60,000,而GPT 5.5仅需16,000——不到前者的三分之一。这意味着GPT 5.5用更少的"思考量"就能给出更好的答案。
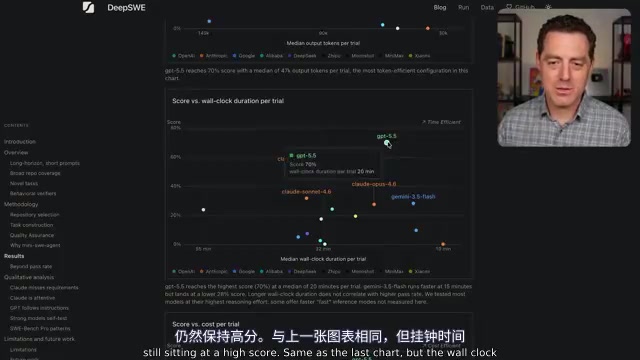
时间方面,GPT 5.5每次试验的Wall Clock时间约为20分钟,而Opus 4.7需要37分钟。Gemini 3.5 Flash虽然以15分钟的速度略胜,但其得分仅为GPT 5.5的约40%。
Wall Clock时间(墙钟时间)指从任务开始到完成的实际经过时间,包括模型推理、API调用延迟、代码执行等所有环节,是衡量端到端效率的核心指标。在实际开发场景中,开发者等待AI完成一次代码修复的时间直接影响工作流效率——一个需要37分钟才能返回结果的工具,在快节奏的开发迭代中可能会打断开发者的心流状态。Token消耗则反映了模型的"思维密度"——输出60,000个token意味着模型生成了大量中间推理步骤或冗余代码,而16,000个token完成同样任务则说明模型的推理更加精炼高效。从成本角度看,大语言模型API通常按token计费,token消耗量直接决定了每次调用的费用。Opus 4.7的高token消耗部分源于Claude模型家族倾向于"展开思考"的推理风格,这在某些场景下有助于提高准确性,但在DeepSWE的测试中并未转化为更高的通过率。
成本方面,这组数据对Anthropic来说相当尴尬:GPT 5.5每次试验的成本约为5.80美元,而Opus 4.7接近16美元——近3倍的价格,却换来更低的分数。Gemini 3.5 Flash虽然价格与GPT 5.5相当,但得分不到其一半。
综合得分、速度、成本三个维度,GPT 5.5在DeepSWE上展现出全面优势。
提示方式的范式转变
DeepSWE的提示词设计哲学值得深入讨论。它的prompt与开发者日常与AI对话的方式高度一致——聚焦行为描述、简短直接、不包含冗长的接口定义。
这反映了AI编程领域的一个重要趋势:不要告诉模型怎么解决问题,而是告诉它你想解决什么问题。 描述期望的应用行为,而非规定具体的代码修改方式。模型需要自主探索代码库,理解上下文,找到问题所在并实现修复。
这种行为描述式提示词(Behavior-Oriented Prompting)代表了AI编程交互的一个重要演进方向。传统的AI编程提示往往包含详细的技术规格——指定修改哪个文件、调用哪个API、使用什么数据结构,本质上是将解决方案的大部分思考工作留给了人类。而行为描述式提示只描述期望的最终行为(如"让这个API在超时后自动重试"),将代码库探索、上下文理解、方案设计等工作全部交给模型。这种方式对模型的代码理解能力(Code Comprehension)和自主代理能力(Agentic Capability)提出了更高要求——模型需要像一个新入职的开发者一样,先阅读和理解现有代码库的架构,再定位问题并实施修复。这也是为什么DeepSWE的提示词虽然更短,但解决方案却需要更多代码量的原因:模型必须自行完成从问题理解到方案实施的全链路工作。
模型行为差异:有趣的发现
DeepSWE还揭示了不同模型家族在编程任务中的行为特征差异:
- Claude容易遗忘多部分需求:当提示词要求实现多个并行行为(如"同时支持同步和异步"),Claude往往只实现明显的那个分支,忘记镜像修改其他部分。这一现象可能与Claude模型在处理长上下文时的注意力分配机制有关——当提示词中包含多个并列要求时,模型的注意力权重可能不均匀地集中在最先出现或最显著的需求上。
- Claude擅长环境感知:当提示词与仓库实际状态不匹配时,Opus 4.7会主动通过git log探索最近的变更,从Git历史中恢复正确的解决方案。这体现了Claude在工具使用(Tool Use)方面的优势——它能够灵活运用shell命令来获取额外上下文信息,而非仅依赖提示词中给定的信息。
- GPT严格执行指令:GPT 5.5在所有配置中,漏掉需求行为的比率最低。它会严格按照提示词和可见的代码契约来生成补丁。这种"指令忠实度"(Instruction Fidelity)在复杂的多步骤编程任务中尤为关键,因为遗漏任何一个需求都可能导致验证失败。
- 强模型倾向于自我验证:除非提示词明确禁止,更强的模型会主动为自己的代码编写测试——这本身就是高质量解决方案的一部分。这种行为反映了模型已经内化了软件工程的最佳实践:测试驱动开发(TDD)的理念认为,编写测试不仅是验证手段,更是帮助开发者理清需求和设计的思维工具。
局限性与展望
你可能没注意到,DeepSWE使用统一的MiniSuiteAgent作为测试脚手架,这意味着Opus 4.7并未在其最优搭档Claude Code环境中被测试。这在一定程度上可能低估了Opus的实际表现,但也更纯粹地反映了模型本身的能力。
在AI编程评测中,代理框架(Agent Scaffold)负责管理模型与代码环境之间的交互——包括文件读写、命令执行、上下文窗口管理等。不同的代理框架会显著影响模型的表现:例如Anthropic的Claude Code为Claude模型量身定制了工具调用策略和上下文管理机制,能够更好地发挥Claude的长上下文理解优势。使用MiniSuiteAgent这一统一框架测试虽然确保了公平性(所有模型在相同条件下竞争),但也意味着某些模型无法利用其专属优化。这类似于让所有赛车手驾驶同一款车比赛——测试的是车手技术而非车辆性能,但在实际应用中,"车手+车辆"的组合才是用户真正关心的。
此外,当前榜单中缺少Composer 2.5等新模型的数据,而据多方评测,Composer 2.5在性价比方面可能同样极具竞争力。
总体而言,DeepSWE代表了AI编程基准测试的一次重要进步。它不仅更贴近真实使用场景,也首次在量化数据层面印证了开发者社区的"直觉感受"——GPT 5.5确实在实际编程任务中领先一筹。随着更多模型被纳入测试、更多编程语言和任务类型被覆盖,DeepSWE有望成为评估AI编程能力的新标准。而对于开发者而言,这个基准测试传递的核心信息很明确:选择AI编程工具时,不要只看传统榜单上的分数,还要关注模型在真实场景下的综合表现——包括准确性、效率和成本的平衡。
核心要点
相关推荐
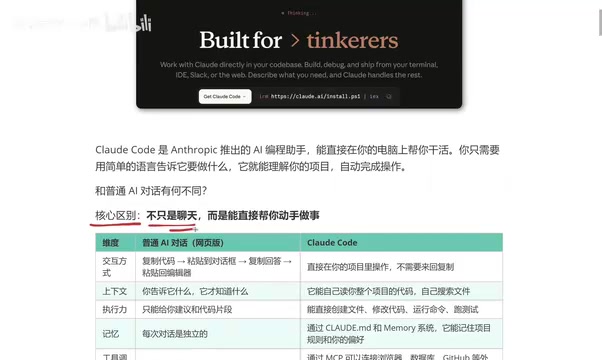
Claude Code是什么?与普通AI对话的五大核心区别
深入解析Claude Code与ChatGPT、DeepSeek等普通AI对话工具的五大核心区别,从交互方式、上下文理解、执行力、记忆能力到工具调用,全面了解这款AI编程助手的真正实力。
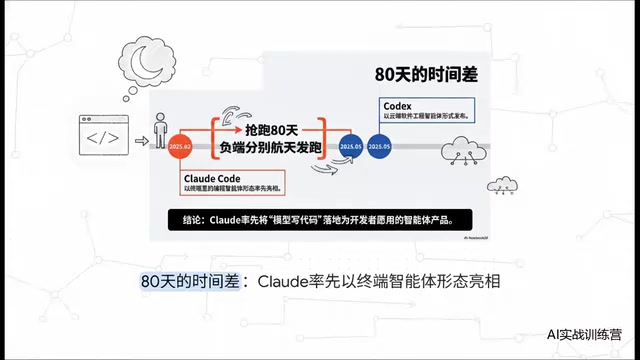
Claude Code vs Codex深度对比:技术趋同下谁更值得选
深度对比Claude Code与OpenAI Codex在先发优势、技术架构、市场份额和工程稳定性方面的差异。从18:4的创新领先到功能像素级对齐,解析AI编程工具趋同时代的终极选择标准。
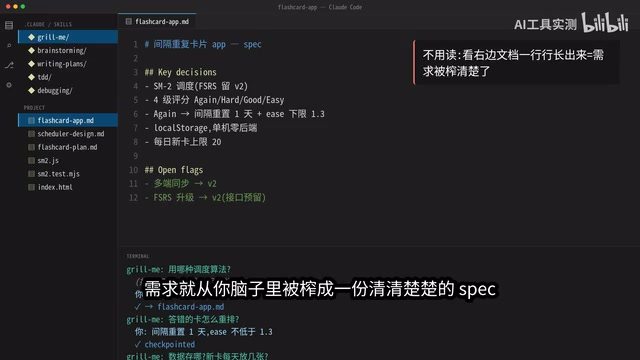
Claude Code每天必用的5个技巧:让AI反过来盘问你
分享Claude Code高效编程的5个实用技巧:Grill Me逼问需求、Brainstorming方案选型、Writing Plan执行计划、TDD测试驱动、Debugging精准修复,串成完整AI编程工作流,告别模糊需求和来回返工。