#AI编程基准
共 4 篇相关文章
·10 分钟
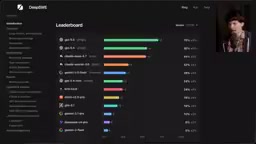
DeepSWE基准测试深度解析:揭露SWE-Bench缺陷与真实编程能力排名
深度解析DeepSWE编程基准测试如何揭露SWE-Bench Pro的数据污染和作弊问题。GPT-5.5以70%通过率领先,开源模型差距明显。涵盖测试结果、成本对比与开发者实用建议。
阅读全文 →
·9 分钟
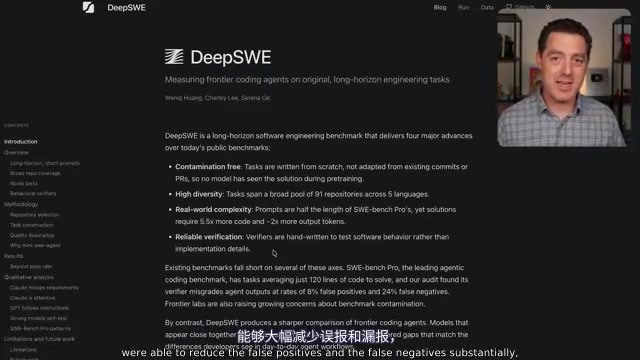
DeepSWE基准测试揭示真相:GPT 5.5大幅领先Opus 4.7
DeepSWE长周期软件工程基准测试显示GPT 5.5以70%通过率领先Opus 4.7超15个百分点,且成本仅为其三分之一。深度解析DeepSWE的无污染验证机制、模型行为差异及对AI编程格局的影响。
阅读全文 →
·5 分钟
ViBench:专为AI应用构建能力设计的评测基准
深入解析ViBench评测基准,了解它如何弥补SWE-bench在应用构建能力评估上的不足,从端到端生成、视觉交互、功能完整性等维度全面衡量AI编程工具的实际表现。
阅读全文 →
 产品体验
产品体验·6 分钟
Claude Opus 4.8深度解析:判断力、诚实度与性价比全面评测
深入解析Claude Opus 4.8的核心升级:判断能力提升、诚实反馈机制优化、Fast Mode成本降至三分之一。对比DeepSeek、GPT-5.5等竞品,分析Opus 4.8在AI编程和长上下文推理场景中的实际价值。
阅读全文 →