共 2 篇相关文章
详解llama.cpp如何启用MTP多Token预测加速技术,涵盖CUDA环境配置、桌面端设置、模型选择及实测性能数据,Qwen3 27B实测近60 Token/s。
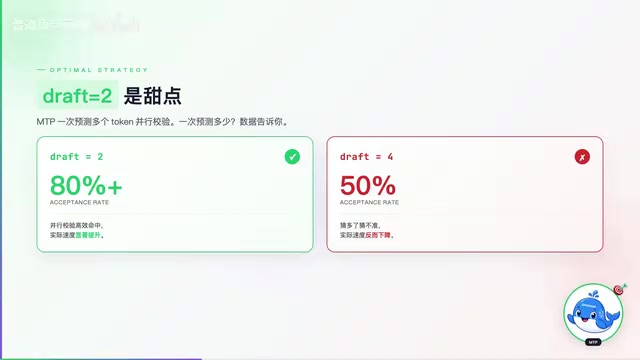
Qwen3.6实验性MTP-GGUF版本实测,单GPU将35B-A3B模型推理速度提升至220 token/s,比原版快1.4倍且精度零损失。详解MTP原理、最优Draft Tokens策略及RTX 5090实测数据。