198页Codex中文手册深度解读:从入门到高阶全流程
为什么你需要一份系统的Codex学习指南
OpenAI的Codex作为当前最强大的AI编程助手之一,正在被越来越多的开发者和效率爱好者关注。Codex最初基于GPT-3微调而来,专门针对代码生成任务进行了优化训练,其训练数据包含了GitHub上数十亿行公开代码。2025年,OpenAI推出了全新的Codex云端软件工程代理,它运行在云端沙箱环境中,能够并行处理多个任务,包括编写功能代码、修复Bug、回答代码库相关问题以及创建Pull Request。与早期版本不同,新版Codex以codex-1模型为核心,该模型经过强化学习训练,能够严格遵循指令、按照既定风格编写代码并执行测试验证,标志着AI编程助手从简单的代码补全进化到了自主软件工程的新阶段。
然而现实是,大多数人的学习路径是这样的:硬啃英文文档、在网上东拼西凑零散教程、入门看不懂原理、实操不会配置——想用它写代码、提效办公,却始终不得要领。
近日,一份由字节跳动内部大佬整理的198页Codex中文使用手册在社区引发热议。这份手册专门为新手和进阶学习者量身打造,从基础安装到高阶多Agent协作,覆盖了Codex使用的完整链路。今天我们就来深度拆解这份手册的核心内容,看看它到底值不值得花时间研读。
手册核心架构:四大模块层层递进
第一层:安装认证与桌面工作流入门
对于零基础用户来说,最大的门槛往往不是Codex本身有多复杂,而是环境配置这一步就劝退了大量人。这份手册的第一部分直接从安装认证讲起,覆盖桌面工作流的基础操作,确保读者能在最短时间内把Codex跑起来。
这种"先跑通再理解"的教学思路非常务实。很多技术文档喜欢先讲一大堆原理,结果读者还没动手就失去了耐心。而这份手册选择让用户先看到结果,再回头理解为什么——这也是大厂内部培训材料的典型特征。在教育学中,这种方法被称为"体验式学习"(Experiential Learning),由教育理论家大卫·库伯提出,强调通过具体体验建立学习动机,再逐步深入抽象概念,其学习留存率远高于传统的"先理论后实践"模式。
第二层:Commands指令与项目配置全拆解
掌握基础操作后,手册进入第二个核心模块——Commands指令体系和项目配置。这部分可以说是Codex使用的"中枢神经",决定了你能在多大程度上驾驭这个工具。
指令系统的掌握程度直接影响使用效率。一个熟练的Codex用户和一个新手之间的差距,往往不在于谁更懂编程,而在于谁更会"下指令"。这里的"下指令"本质上就是提示工程(Prompt Engineering)的实践——如何用精确、结构化的自然语言描述需求,使AI模型输出最符合预期的结果。研究表明,经过优化的提示词可以将AI代码生成的准确率提升30%-50%。手册对指令体系的全线拆解,意味着读者可以系统性地建立起自己的指令知识库,而不是靠零散的经验积累。
第三层:MCP工作流与Skills模板
这是手册中最具实用价值的部分之一。MCP(Model Context Protocol)工作流是当前AI编程工具的核心协议,理解它等于理解了Codex的底层运作逻辑。
MCP(模型上下文协议)是由Anthropic于2024年底推出的开放标准协议,旨在为AI模型与外部数据源、工具之间建立统一的通信接口。可以将MCP理解为AI领域的"USB-C接口"——它定义了一套标准化的连接方式,使得AI模型能够无缝访问文件系统、数据库、API服务、开发工具等各类外部资源。在Codex的使用场景中,MCP工作流允许用户将代码仓库、项目文档、测试框架等上下文信息通过标准协议注入到AI模型中,使其能够在充分理解项目背景的前提下生成更精准的代码。MCP采用客户端-服务器架构,支持本地和远程两种连接模式,目前已被Cursor、VS Code、Windsurf等主流AI编程工具广泛集成。
更值得关注的是可复用Skills模板的概念。手册教用户把常用操作封装成"一键提效包"——这本质上是在教你构建自己的AI工作流自动化体系。Skills模板的概念本质上是对"基础设施即代码"(Infrastructure as Code)思想在AI工作流领域的延伸。在传统DevOps实践中,工程师通过编写配置文件将服务器部署、环境配置等操作模板化;而在AI编程场景中,Skills模板则是将常用的AI交互模式——包括提示词、上下文配置、输出格式要求、后处理逻辑等——封装为可复用的标准化单元。
比如你经常需要做代码审查、格式化、测试用例生成这类重复性工作,完全可以把这些操作模板化,后续一键调用。用户可以将这些高频操作定义为Skills,实现团队级别的效率复制,将隐性经验转化为显性知识资产。
这种思路的价值远超Codex本身。它培养的是一种"把重复劳动抽象为可复用流程"的思维方式,这在任何AI工具的使用中都是通用的。这与软件设计模式中的"模板方法模式"异曲同工——定义算法骨架,将具体步骤延迟到子类实现,从而在保持流程一致性的同时允许灵活定制。
高阶玩法:多Agent协作与后台任务调度
手册的最后一个大模块直接进入了高阶领域:Subagents多Agent协作、后台任务调度、周期检查以及结果联合合并。
多Agent协作的实际意义
多Agent协作并不是一个噱头概念。多Agent协作(Multi-Agent Collaboration)是当前AI系统设计中的前沿范式,其核心思想源自分布式计算和微服务架构——将一个复杂任务分解为多个专业化的子任务,由不同的AI代理(Agent)各自负责处理,最终通过协调机制整合结果。
在Codex的Subagents体系中,主Agent(Orchestrator)负责任务分解和调度,子Agent各自在独立的沙箱环境中执行具体工作。在实际的软件开发场景中,一个复杂任务往往需要拆解为多个子任务并行处理:一个Agent负责代码生成,一个负责测试验证,一个负责文档编写,最后再把结果合并。这种工作模式能够显著提升复杂项目的处理效率。
这种架构的优势在于:首先,每个Agent可以拥有独立的上下文窗口,避免了单一Agent处理复杂任务时的上下文溢出问题——要知道,即使是最先进的大语言模型,其上下文窗口也是有限的,单个Agent处理超大型代码库时很容易"遗忘"关键信息;其次,多个Agent可以并行执行,大幅缩短总体处理时间;最后,专业化分工使得每个Agent能够在其擅长的领域发挥最大效能。这一模式与软件工程中的"分治策略"和DevOps中的流水线思想高度一致。
后台任务调度与周期检查
后台任务调度意味着你可以让Codex在后台持续运行特定任务,比如定期检查代码质量、自动运行测试套件、监控项目依赖更新等。这已经不是简单的"AI帮你写代码",而是AI作为你的持续集成助手在工作。
后台任务调度在Codex中的实现,实际上是将传统CI/CD(持续集成/持续部署)流水线中的自动化理念与AI能力相结合。传统CI/CD工具如Jenkins、GitHub Actions等通过预定义的脚本在代码提交后自动执行构建、测试、部署等流程;而Codex的后台任务调度则更进一步,它不仅能执行预设的自动化脚本,还能利用AI的理解和推理能力进行智能化的代码质量分析、潜在Bug检测、依赖安全审计等工作。
周期检查和结果联合合并则进一步完善了这个自动化闭环。周期检查机制类似于Cron Job的定时任务调度,但融入了AI的判断能力——例如,它不仅能检测到依赖包有新版本,还能评估升级的兼容性风险并自动生成迁移方案。你可以设定检查频率,让多个Agent的产出在最终环节被统一校验和整合,确保输出质量。结果联合合并则借鉴了Git中的合并(Merge)策略,通过冲突检测和智能解决机制,将多个Agent的并行产出整合为一致的最终输出。
这份Codex中文手册适合谁
从内容结构来看,这份手册的目标受众覆盖面相当广:
- 零基础编程小白:从安装配置开始,手把手带入门,不需要任何前置知识
- 在职程序员:MCP工作流和多Agent协作等高阶内容,可以直接应用到日常开发中,尤其适合正在探索AI辅助开发(AI-Assisted Development)的团队
- 效率提升爱好者:Skills模板和后台任务调度的思路,适用于任何想借助AI提效的场景,无论是内容创作、数据分析还是项目管理
- 学生群体:系统化的学习路径,比自己在网上零散搜索效率高出数倍,同时也能帮助建立对现代软件工程实践的整体认知
总结与思考
这份198页的Codex中文手册最大的价值,不仅在于它把散落在各处的知识点做了系统整合,更在于它体现了大厂内部对AI工具使用的方法论沉淀。从基础操作到高阶协作,从单点技能到工作流自动化,它展示的是一条完整的AI编程能力成长路径。
当然,任何手册都只是起点。真正的能力提升还是要靠大量的实操练习。但有一份结构清晰、可直接落地的指南作为参考,至少能让你少走很多弯路,把时间花在真正有价值的实践上。
在AI工具迭代如此迅速的今天,与其被动等待零散信息的投喂,不如主动建立系统化的学习框架。值得注意的是,AI编程工具的发展正在从"辅助编码"向"自主工程"快速演进——从GitHub Copilot的行级补全,到Cursor的项目级理解,再到Codex的多Agent自主协作,每一次跃迁都在重新定义开发者与AI的协作边界。掌握系统化的AI工具使用方法论,而非仅仅学会某一个工具的操作,这或许是这份手册给我们最大的启示。
相关推荐
DeepSeek+Resonix:1.5亿Token仅花8元的低成本AI编程方案
实测DeepSeek API搭配Resonix编程工具,1.5亿Token仅花费8元人民币。深入解析DeepSeek定价策略、Resonix 95%缓存命中率的实现原理,以及与GPT模型编码能力的真实对比。
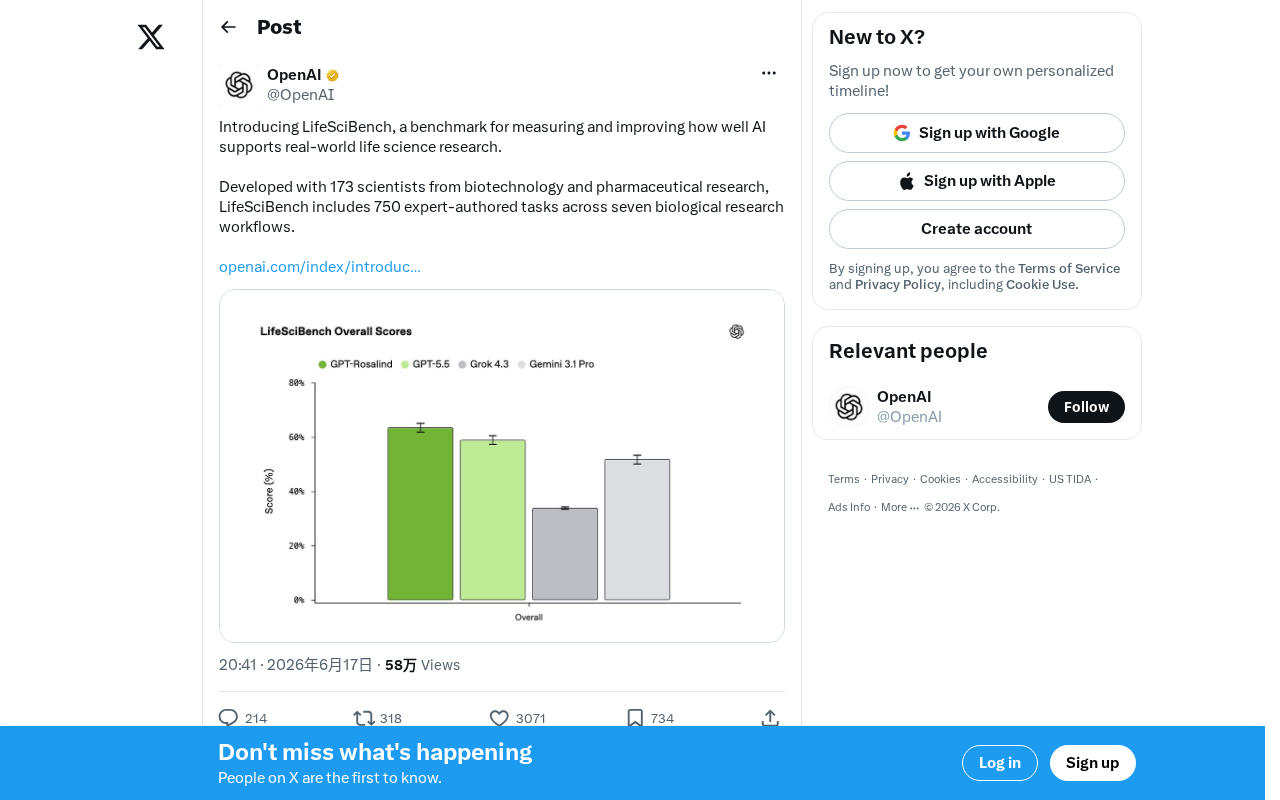
LifeSciBench:173位科学家打造的生命科学AI基准测试
LifeSciBench是由173位生物技术与制药领域科学家共同开发的生命科学AI基准测试,涵盖750项专家任务和七大研究工作流程,为AI在生命科学领域的评估提供专业标准。

OpenAI o3诊断罕见儿童疾病:NEJM AI研究深度解读
OpenAI联合波士顿儿童医院在NEJM AI发表研究,展示o3 Deep Research模型如何帮助临床医生诊断此前未解决的罕见儿童疾病病例,为等待多年的家庭带来答案。