AI Gaming Showdown: O3 Pro Demonstrates Stunning Planning Capabilities
AI Gaming Showdown: O3 Pro Demonstrate…
O3 Pro demonstrates unprecedented AI planning capabilities in classic game testing
Researchers used a text-based game harness to test major AI models on classic games including Tetris, Super Mario Bros, and Sokoban. While most models struggled, OpenAI's O3 Pro demonstrated crushing planning superiority through its Test-Time Compute Scaling architecture. The study reveals three key findings: genuine planning ability is emerging in AI, games evaluate real AI capabilities better than traditional benchmarks, and cross-game knowledge transfer is already showing early signs.
When AI Meets Classic Games: A Novel Intelligence Test
We're accustomed to measuring AI capabilities with academic benchmarks—mathematical reasoning, code generation, text comprehension. But what happens when these supposedly "PhD-level" AIs are asked to play Tetris, Super Mario Bros, or Sokoban?
Recently, researchers built a text-based game testing harness that converts game states into textual descriptions fed to various AI models, then lets them decide the next move. This harness is essentially a middleware technology that serializes visual/interactive game states into structured text—since large language models process token sequences rather than pixels, researchers need to encode the game's 2D grid, entity positions, current scores, and other state information into natural language or symbolic descriptions (such as using character matrices to represent the Tetris board), then parse the model's text-based instructions back into executable operations for the game engine. This approach doesn't require training specialized vision models, but introduces information loss—models can only rely on symbolic state descriptions for reasoning and cannot perceive visual cues like animation frame rates.
The results were eye-opening: most AIs struggled in games, but OpenAI's O3 Pro demonstrated unprecedented planning capabilities.
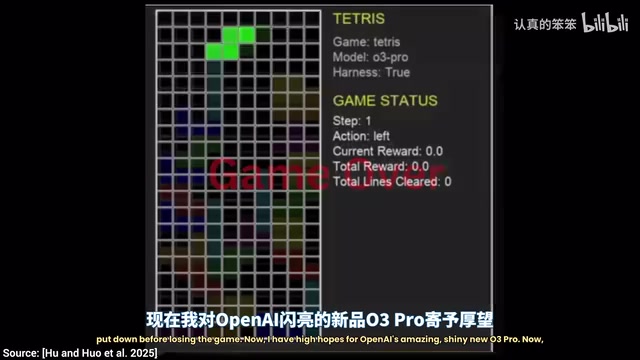
Tetris: From Total Chaos to Perfect Line Clears
Most AIs' Dismal Performance
First up was Llama 4. Despite performing well on traditional benchmarks, it was completely lost when facing Tetris. Previous models left massive gaps, could barely form complete lines, and quickly collapsed.
OpenAI's O4 Mini showed slight improvement, lasting longer but still failing to clear a single line. DeepSeek R1 started well and even managed to clear one line, but the situation quickly spiraled out of control. Claude 4 Opus performed similarly—these AIs seemed to be competing over who could "lose later" rather than actually winning the game.
Notably, these models' failures aren't coincidental. Current mainstream AI benchmarks like MMLU, HumanEval, and GSM8K share a common flaw: they're essentially static single-turn Q&A that cannot evaluate a model's continuous decision-making ability in dynamic environments. An even more serious issue is "Benchmark Contamination"—since test questions appear extensively on the internet, models may have already "seen" the answers during pre-training, meaning high scores don't necessarily represent genuine generalization and reasoning capabilities. Tetris's real-time dynamic states expose precisely this shortcoming.
O3 Pro's Stunning Performance
O3 Pro's opening looked somewhat odd, but with patience, you'd notice it clearing lines one after another. More critically, it appeared to be the first model truly "planning ahead"—not simply placing the current piece, but reserving space for subsequent pieces.
O3 Pro achieves this thanks to its underlying architecture. It belongs to OpenAI's "o-series" reasoning models, whose core feature is executing extensive internal Chain-of-Thought reasoning steps before generating a final answer. This architecture is called Test-Time Compute Scaling—improving answer quality by investing more computational resources during the inference phase, similar to how a human chess player thinks deeply before making a move rather than relying on instinct. This is precisely why O3 Pro's decision-making is extremely slow—it internally simulates and evaluates multiple possible future states before each operation. Throughout the entire experiment, O3 Pro never failed, making it unique among all tested models.
Super Mario Bros: The Evolution from Cliff-Jumping to Level Completion
GPT-4o's performance in Super Mario Bros can only be described as "disastrous." Claude 3.5 appeared slightly smarter, even finding hidden blocks, but then inexplicably jumped into an abyss.
Claude 3.7 was noticeably better: stomping Goombas, bravely leaping over pits, discovering the invincibility star and rushing toward it. It was almost at the finish line—then disaster struck. On retry, it sailed smoothly toward completion, only to fail at the simplest spot. The researchers remarked: "This is the first time watching AI play games felt like watching a human play—pulling off god-tier moves, then failing at the easiest thing."

Final results showed the O3 series leading across Super Mario Bros, Sokoban, and Candy Crush, often by a crushing margin.
Sokoban: The Ultimate Test of Planning Ability
Why Sokoban Is the Litmus Test for AI Planning
Sokoban is a classic logic game: push boxes to designated positions. It seems simple, but in computational complexity theory it's proven to be a PSPACE-complete problem, meaning its solving difficulty grows exponentially with level size, posing extreme challenges even for classical algorithms. In AI research, Sokoban has long served as a standard environment for testing heuristic search, constraint satisfaction, and reinforcement learning algorithms. Its core challenge lies in "irreversible operations"—once a box is pushed into a corner it cannot be retrieved, requiring planners to simulate multiple future states before acting, similar to look-ahead search in chess but with a sparser state space and more hidden traps. This is precisely why Sokoban serves as an ideal litmus test for distinguishing "pattern matching" from "genuine planning" capabilities.
Gemini 2.5 Flash successfully completed the first level but fell into a classic trap on level two: it pushed the first box to the wrong position, making it impossible to place the second box.
O3's Strategic Thinking
Facing the same second level, O3 demonstrated genuine planning ability: it recognized that pushing a box onto a certain marker first would prevent the second box from being placed. So it chose the correct sequence, and the level practically solved itself. However, O3 also stalled after level four.
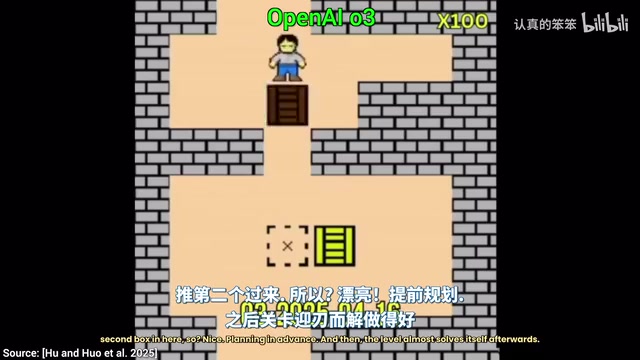
O3 Pro went further—successfully completing all six levels. Although decision time for each move was extremely long (the video demonstration is sped up), the systematic planning ability it displayed was deeply impressive.
Three Key Findings: Deep Trends Revealed by AI Game Testing

Finding One: Genuine Planning Ability Is Emerging
Perhaps for the first time in history, we're beginning to see genuine planning and strategic thinking in large language models. While slow, the mere emergence of this capability is a milestone. AI is no longer just pattern matching—it's starting to "think" about future states. The technical driving force behind this is the test-time compute scaling architecture—by allowing models to "slow down and think" during inference, higher-quality decision outputs are achieved.
Finding Two: Games Are Better AI Evaluation Tools
Traditional benchmarks can't tell us the whole story. Game testing harnesses provide a dynamic, stateful evaluation environment requiring long-term planning. Each game session is a unique sequence that's difficult to cheat through memorization, thus more authentically reflecting a model's reasoning depth and adaptability. Games serve as an incredibly rich and challenging testing platform that demands long-term planning and dynamic adaptation—capabilities that few other benchmarks can assess. Through games, we can gain deeper understanding of AI's strengths and weaknesses.
Finding Three: Cross-Game Knowledge Transfer
This is the most exciting finding: after training on Sokoban, AI's spatial reasoning ability improved, with Tetris performance increasing by up to 8%. This phenomenon is closely related to Transfer Learning and Domain Generalization theories in machine learning. The transfer from Sokoban to Tetris likely works because both involve reasoning about object positions in 2D space and multi-step planning. A deeper explanation is that large language models have already acquired abstract spatial relationship representations from massive text during pre-training, and game training merely activates and strengthens these latent capabilities. This finding echoes a core hypothesis in AGI research: true intelligence should be able to transfer abstract rules learned in one domain to structurally similar new domains without learning from scratch. Knowledge learned in one completely different game can transfer to another—this may be the seedling of some form of general intelligence, wisdom emerging from silicon.
Conclusion and Outlook
This research reveals an important trend: AI capabilities are evolving from "memorization and matching" toward "planning and reasoning." Although O3 Pro's decision-making speed is extremely slow, the forward-thinking and cross-domain transfer capabilities it demonstrates suggest that large models are developing some deeper cognitive structure.
Of course, current AI performance in games still falls short of human players—especially in speed and adaptive flexibility. But considering these models weren't specifically designed for gaming, the general planning capabilities they demonstrate are already remarkable enough. Game testing may well become an important supplementary tool for evaluating AI's true intelligence level in the future.
Key Takeaways
- OpenAI O3 Pro demonstrates crushing planning superiority over other AIs in Tetris, Super Mario Bros, and Sokoban
- Game testing reveals AI's true reasoning and planning capabilities more effectively than traditional benchmarks, effectively circumventing the "Benchmark Contamination" problem
- After Sokoban training, AI's spatial reasoning improves with Tetris performance increasing up to 8%, demonstrating cross-domain knowledge transfer
- Most mainstream AIs (Llama 4, DeepSeek R1, Claude, etc.) struggle in games, only competing over who loses later
- Researchers use a text-based game harness to enable large language models to participate in game decision-making
- O3 Pro's slow decision-making stems from its "Test-Time Compute Scaling" architecture, trading internal chain-of-thought reasoning for higher-quality planning output
Related articles
New Species Discovered in New York's C…
New Species Discovered in New York's Central Park? Inside the Urban Insect Hunting Project
Scientists set up insect traps in NYC's Central Park and Prospect Park to discover unknown species. With 90% of Earth's species still unnamed, urban biodiversity research is becoming a new trend in ecology.
The Full Story of the Higgs Boson Disc…
The Full Story of the Higgs Boson Discovery: An Insider's Account of the 'God Particle'
A Fermilab physicist's insider account of the Higgs boson discovery: the transatlantic race with CERN, behind-the-scenes details of the 2012 announcement, 14 years of verification, and the true origin of the 'God Particle' name.
 Research
ResearchSciMDR: How a 7B Small Model Rivals GPT-5 in Scientific Reasoning
Yale and other institutions introduce SciMDR, a two-stage data synthesis pipeline enabling a 7B model to match GPT-5 level performance in scientific literature comprehension.