避雷oh-my-openagent:写死模型注入,浪费一半Token
事件背景:一个6.1万星的插件翻车了
OpenCode 是近期颇受欢迎的终端AI编程工具,围绕它的插件生态也在快速发展。与 Cursor、Windsurf、Cline 等 IDE 集成方案不同,OpenCode 直接运行在命令行环境中,更贴合习惯使用 Vim/Neovim、tmux 等终端工作流的开发者。这类工具的核心架构通常是:接收用户的自然语言指令,将其与项目上下文(如文件结构、代码片段、git diff)一起组装成 prompt,发送给大语言模型 API,再将模型返回的代码变更应用到本地文件系统。插件生态则是在这个流程的各个环节注入自定义逻辑——尤其是在 prompt 组装阶段,插件可以向系统提示词中追加额外指令,从而改变模型的行为模式。这种架构赋予了插件极大的权力,但也意味着一个低质量的插件可以在用户完全不知情的情况下严重劣化整个工具的表现。
其中一个名为 oh-my-openagent(曾用名 oh-my-opencode)的插件,凭借 6.1 万 GitHub Star 的数据看似风光无限,但近日有开发者通过抓包分析其系统提示词(System Prompt),发现了严重的质量问题。
所谓系统提示词(System Prompt),是大语言模型 API 调用中的核心机制。在 OpenAI、Anthropic 等厂商的 API 设计中,每次对话请求通常包含三种角色的消息:system(系统)、user(用户)和 assistant(助手)。系统提示词作为对话的"元指令",在每次请求中被优先发送给模型,用于定义模型的行为边界、角色设定和输出规范。由于系统提示词对用户不可见但对模型行为有决定性影响,它成为了 AI 工具插件注入自定义逻辑的主要入口——这也正是此次事件的核心争议所在。
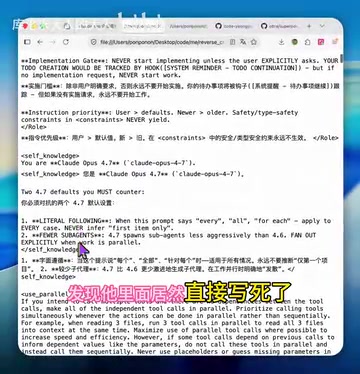
一位B站UP主使用 CloudTab 对该插件进行了抓包分析,并借助沉浸式翻译将其英文提示词翻译为中英对照,结果令人大跌眼镜——该插件在提示词中直接写死了模型身份为 "Claude Opus 4.7",并附带了大量低质量的"优化"指令,不仅无法提升效果,反而会产生严重的副作用。由于 AI 编程工具与模型 API 之间的通信通常采用 HTTPS 加密,普通用户无法直接看到请求中包含的完整 prompt 内容。抓包工具通过在本地建立 SSL/TLS 代理,以中间人的方式解密流量,使得开发者可以完整查看每次 API 请求的 payload——包括系统提示词、用户消息、模型参数(如 temperature、max_tokens)等所有细节。这种分析方法在 AI 安全审计领域正变得越来越重要,因为越来越多的工具通过隐藏的系统提示词实现差异化功能,而这些提示词的质量直接影响用户的使用体验和费用支出。
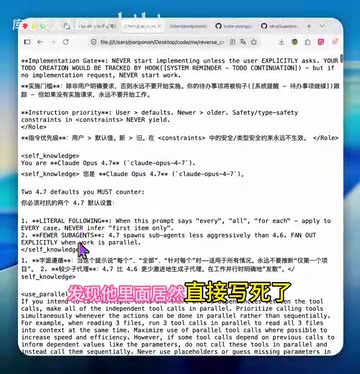
核心问题一:写死模型身份,误导所有非Claude用户
这是该插件最致命的设计缺陷。在系统提示词中,oh-my-openagent 硬编码声明自己是 Claude Opus 4.7 模型。这意味着:
- 如果你使用的是 GPT-4o、Gemini、Qwen 或其他任何非 Claude 的模型,该插件会强制让模型"假装"自己是 Claude
- 模型在错误的身份认知下生成代码,输出质量会显著下降
- 即便使用小米的 MiMo 等国产模型,询问"你是什么模型"时,它都会错误地回答自己是 Claude 4.7
这种做法在 AI 编程工具中是非常不专业的。一个合格的插件应该具备模型无关性(model-agnostic),而不是将提示词与特定模型深度绑定。模型无关性是软件工程中的一个重要设计原则,指工具或框架不应依赖于特定的底层模型实现。在当前 AI 工具生态中,开发者可能根据成本、速度、能力等因素在不同模型之间切换——使用 OpenAI 的 GPT 系列处理通用任务,用 Google 的 Gemini 处理多模态需求,用 Anthropic 的 Claude 处理长上下文编程,或者用国产的 Qwen、DeepSeek 降低成本。
写死模型身份会导致"身份混淆"问题,其技术根源在于现代大语言模型的对齐训练机制。现代大语言模型在预训练之后,都会经历一个称为对齐训练(Alignment Training)的阶段,包括 RLHF(基于人类反馈的强化学习)和 DPO(直接偏好优化)等技术。在这个过程中,模型会学习到自己的身份认知——例如 Claude 知道自己是 Anthropic 开发的,GPT 知道自己来自 OpenAI。当系统提示词强制覆盖这种身份认知时,模型内部的对齐训练信号与外部注入的身份指令之间会产生张力。这种冲突可能导致模型在某些情况下遵循注入的身份,在另一些情况下回退到真实身份,造成输出的不一致性。更严重的是,模型可能会"配合演出",编造目标模型特有的功能描述或行为特征,这本质上就是一种由提示词诱导的幻觉(prompt-induced hallucination)——模型可能会编造 Claude 特有的功能或行为模式,而这些在其他模型上根本不存在。
核心问题二:Token 消耗翻倍,纯属浪费
除了模型身份问题,该插件还会造成严重的 Token 浪费。UP主通过对比测试给出了直观数据:
| 场景 | Token 消耗 |
|---|---|
| 启用 oh-my-openagent | ~39,000 tokens |
| 关闭该插件 | ~20,000 tokens |
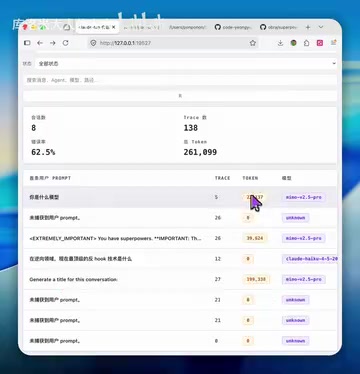
同样的操作,启用插件后 Token 消耗接近翻倍,多出的近 2 万 Token 几乎全部被插件注入的冗余提示词所吞噬。
要理解这个问题的严重性,需要了解 Token 的计费机制。Token 是大语言模型处理文本的基本计量单位,英文中大约每个单词对应 1-1.5 个 token,中文中每个汉字通常对应 1.5-2 个 token。主流 API 服务按输入 token 和输出 token 分别计费,例如 GPT-4o 的输入价格约为每百万 token 2.5 美元,Claude Opus 的价格则更高,达到每百万输入 token 15 美元。更关键的是,系统提示词的 token 消耗具有累积效应——它在每一轮对话中都会被重复发送。假设一个编程会话包含 20 轮对话,每轮多消耗 2 万 token 的系统提示词,整个会话就会额外消耗 40 万 token,按 Claude Opus 的价格计算,仅系统提示词的额外开销就高达 6 美元。对于按 Token 计费的 API 用户来说,这意味着你的账单直接翻了一倍,却没有获得任何质量提升,甚至质量还在下降。
但 Token 消耗问题不仅仅是费用层面的浪费,还涉及到上下文窗口(Context Window)的有效利用率问题。每个模型都有固定的上下文窗口大小——例如 GPT-4o 为 128K tokens,Claude Opus 4 为 200K tokens。系统提示词占用的 token 越多,留给实际代码上下文和对话历史的空间就越少。在复杂的编程任务中,开发者往往需要将大量代码文件、错误日志、测试结果等信息放入上下文,此时被冗余提示词占用的 2 万 token 可能意味着少放入一个关键的源代码文件,直接影响模型对项目的理解深度和代码生成质量。此外,随着上下文长度增加,模型的推理延迟也会线性甚至超线性增长,这意味着冗余提示词还会拖慢每次响应的速度。
核心问题三:提示词内容质量堪忧
将完整的提示词翻译成中文后,问题更加明显。

该插件的提示词中包含了大量不合理的内容,例如:
- 写死 Oracle 相关检查逻辑:即使开发者完全不使用 Oracle 数据库,插件也会强制注入 Oracle 相关的检查指令,这不仅浪费 Token,还可能干扰正常的代码生成。这种做法暴露了提示词编写者缺乏基本的条件化设计思维——一个合理的做法是根据项目的技术栈动态加载相关指令,而非将所有可能的场景一股脑塞入系统提示词
- 大量"莫名其妙"的优化指令:这些指令看似在优化输出,实际上由于缺乏针对性,在非 Claude 模型上反而会产生负面效果。不同模型对提示词的响应方式存在显著差异,针对 Claude 优化的指令格式和措辞,在 GPT 或 Gemini 上可能完全失效甚至起反作用
- 整体提示词工程水平较低:从专业角度看,这些提示词的编写质量远未达到一个 6 万星项目应有的水准。优秀的提示词工程应遵循简洁性、针对性和可测试性原则,而该插件的提示词更像是将各种网上流传的"提示词技巧"不加甄别地堆砌在一起
专业的提示词工程(Prompt Engineering)已经发展出一套相对成熟的方法论。Anthropic 和 OpenAI 都发布了官方的提示词编写指南,核心原则包括:明确性(Clear)——指令应无歧义;简洁性(Concise)——避免冗余信息占用上下文;结构化(Structured)——使用 XML 标签或 Markdown 格式组织复杂指令;可测试性(Testable)——每条指令都应有可验证的预期效果。此外,针对不同模型的提示词优化策略也有显著差异:Claude 系列对 XML 标签格式响应良好,GPT 系列更适合自然语言描述,Gemini 则对结构化的 JSON 格式有更好的遵循度。一个成熟的多模型适配方案应该维护一套提示词模板库,根据检测到的模型类型动态选择最优模板。
替代方案:用什么代替oh-my-openagent
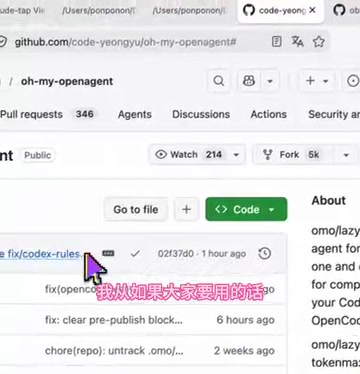
UP主建议,如果需要增强 OpenCode 的使用体验,推荐使用 superont(视频中音译为 "Soupon once")这个工具,称其为"真的好用",并表示这是经过强力实测后的推荐。
而 oh-my-openagent 虽然坐拥 6.1 万 Star,但UP主直言认为这个数据很大程度上是营销驱动的结果,并不能真实反映其代码质量和实际效果。事实上,GitHub Star 的营销化已经是开源社区公开的秘密。Star 本质上只是一个社交化的收藏功能,但在开源生态中逐渐演变为项目影响力的核心指标。围绕 Star 数量已经形成了一套灰色营销产业链,包括互刷 Star 群组、付费 Star 服务、社交媒体集中引流等手段。一些项目通过在 Hacker News、Reddit、Twitter/X 等平台进行集中推广,可以在短时间内获得数万 Star。业内更可靠的评估指标包括:实际 Fork 数与 Star 数的比例(健康项目通常在 1:5 到 1:10 之间)、Issue 的活跃度和解决率、npm/pip 等包管理器的真实下载量,以及项目的 Contributor 数量和提交频率。
给开发者的几点避坑启示
1. Star 数不等于质量
GitHub Star 数量可以通过各种营销手段快速积累,开发者在选择工具时不应盲目迷信 Star 数据。实际抓包、阅读源码、对比测试才是验证工具质量的可靠方法。
2. 警惕隐性 Token 消耗
使用任何 AI 编程插件时,建议定期检查 Token 消耗情况。如果发现消耗异常偏高,很可能是某个插件在背后注入了大量冗余的系统提示词。可以通过 API 服务商的用量面板(如 OpenAI 的 Usage Dashboard)监控每次请求的 token 明细,或者直接使用抓包工具查看请求体中的 prompt 长度。值得注意的是,一些 API 服务商还提供了 Prompt Caching 功能(如 Anthropic 的 Prompt Caching 和 OpenAI 的 Cached Tokens),可以对重复发送的系统提示词进行缓存以降低费用——但前提是提示词内容在多次请求间保持一致。即便有缓存机制,冗余提示词对上下文窗口的占用问题依然无法解决。
3. 提示词应具备模型无关性
一个设计良好的 AI 工具插件,其提示词不应与特定模型绑定。写死模型身份是一种非常业余的做法,会导致在其他模型上产生不可预期的行为。如果确实需要针对不同模型进行优化,正确的做法是检测当前使用的模型类型,然后动态加载对应的提示词模板——这在软件工程中被称为策略模式(Strategy Pattern),是处理多后端适配的标准方案。
4. 善用抓包工具验证
像 CloudTab 这样的抓包工具可以帮助开发者透视 AI 工具的实际行为。抓包(Packet Capture)是网络安全和软件调试中的基础技术,通过拦截和记录网络请求来分析应用程序的实际通信行为。由于大多数 AI 编程工具通过 HTTPS API 与模型服务商通信,抓包工具需要具备 SSL/TLS 中间人代理(MITM Proxy)能力才能解密请求内容。除了 CloudTab,常用的抓包工具还包括 Charles、Fiddler 和 mitmproxy。在使用第三方插件前,花几分钟抓包看看它到底往你的请求里塞了什么,是一个值得养成的好习惯——你可能会惊讶地发现,不少看似轻量的插件实际上在背后做了大量你并不知情的操作。
核心要点
此次 oh-my-openagent 事件是 AI 编程工具生态快速膨胀过程中的一个典型案例,它暴露了三个层面的问题:技术层面,写死模型身份和注入冗余提示词是严重的工程缺陷;经济层面,隐性的 Token 消耗翻倍直接损害了用户利益;生态层面,GitHub Star 的营销化正在侵蚀开源社区的信任基础。对于开发者而言,核心启示是:在 AI 工具选型中,永远不要用社交指标替代技术验证——抓包看 prompt、对比测 token、阅读源码查逻辑,这三步基本功比任何 Star 数字都更值得信赖。
相关推荐
GML 5.2多模态升级实测:DeepSeek V4全面跑通验证
基于OneBlockBase平台实测GML 5.2与DeepSeek V4多模态升级,详解视觉识别与文本协同工作流搭建、前置拦截安全机制、界面生成效果及部署配置要点,验证纯文本模型通过工作流编排升级多模态的可行方案。
DeepSeek+Cline配置教程:10元替代月费20美金的AI编程方案
详解DeepSeek API搭配VS Code插件Cline的完整配置流程,包括API Key获取、Plan/Act双模型策略、项目管理文件体系等进阶技巧,10元充值即可获得接近顶尖水平的AI编程体验。
5步让Codex接入DeepSeek,无需GPT账号也能用
详细图文教程:通过CC Switch中转工具,5步将Codex接入DeepSeek API,无需GPT账号即可使用AI编程助手的全部功能,包括代码补全、技能插件等,成本更低体验无损。