Claude Opus 4.8深度解读:诚实比跑分更重要
Claude Opus 4.8核心升级在于更诚实可靠,并推出多Agent并行调度能力
Anthropic发布Claude Opus 4.8,价格不变,重点提升模型可靠性:代码漏洞遗漏率降低约4倍,模型更愿主动指出不确定性。同时推出Dynamic Workflows机制,支持上百个子Agent并行调度,可托管整个代码库级别的迁移任务。Claude Code额度已重置并提供促销加量,新增思考强度控制功能。Anthropic还透露更强的Miscells模型将在未来几周内开放。
文章正文
Anthropic在2025年5月28日发布了Claude Opus 4.8,距离上一代4.7仅隔41天。价格一分未涨,但这次升级的核心并不在跑分数字上——它变得更诚实了。对于所有在生产环境中使用AI的开发者和知识工作者来说,这可能是比性能提升更有价值的进化。
4.8的整体定位:修Bug比加功能更重要
Claude Opus 4.8并非一次大改架构的版本迭代,而是一次「把4.7的毛病修干净,再把能力往上推一档」的精细化升级。
4.7发布后,用户集中吐槽了两个问题:写代码时注释过于啰嗦,以及工具调用偶尔出错。这两个问题在4.8中都得到了修复。能力维度上,Anthropic表示4.8在编码、Agentic任务、推理和知识工作几个方向上均达到了同代模型的第一梯队水平。例如在OnlineMind2Web这个网页操作基准测试上,4.8拿到了84%的成绩。
OnlineMind2Web是专门评估AI模型在真实网页环境中执行操作任务能力的基准测试,源自Mind2Web数据集的在线版本。与静态问答测试不同,它要求模型在动态网页界面中完成多步骤任务,例如在电商网站搜索商品并完成购买流程、在政府网站填写表单等。84%的成绩意味着模型能够可靠地理解网页结构、识别交互元素并按序执行操作,这对于构建能够自主完成浏览器操作的AI Agent至关重要。
但跑分只是表面文章,这次版本真正的主角是一个更基础的东西——可靠性。
核心升级:模型变得更诚实了
Anthropic在公告中明确指出,Claude Opus 4.8在写完代码后,放过自己代码中漏洞的概率比4.7降低了约4倍。
这意味着什么?它更愿意主动告诉你「这里我不确定」「这个输入可能有问题」,而不是硬着头皮装作什么都懂。对于做严肃工作的人来说,这一点比多几分跑分重要得多。
对冲基金Bridgewater在内测中给出了一个非常有说服力的反馈:4.8和其他模型最大的区别,就是它会主动指出分析中输入和输出的问题,而这恰恰是其他模型经常漏掉的环节。在安全对齐的评估中,4.8的表现也创了新高,出现错位行为的比例明显低于4.7。
为什么「诚实」如此关键?
AI模型的「诚实性」在技术上对应「校准度(Calibration)」这一概念——即模型的置信度与其实际准确率的匹配程度。一个校准良好的模型在说「我80%确定」时,其实际正确率应接近80%。大语言模型普遍存在「过度自信」问题,倾向于以高置信度输出错误答案,这在学术上被称为「幻觉(Hallucination)」。Anthropic通过RLHF(基于人类反馈的强化学习)和Constitutional AI等技术,专门针对这一问题进行训练优化,使模型在不确定时更倾向于表达疑虑而非强行给出答案。
在AI辅助编程和决策的场景中,模型「不知道自己不知道」是最危险的状态。一个自信满满地给出错误答案的模型,比一个坦诚说「我不确定」的模型,造成的损失要大得多。Claude Opus 4.8在这个方向上的进步,本质上是在降低AI协作的信任成本——你不需要花那么多精力去验证模型是否在「编造」答案了。
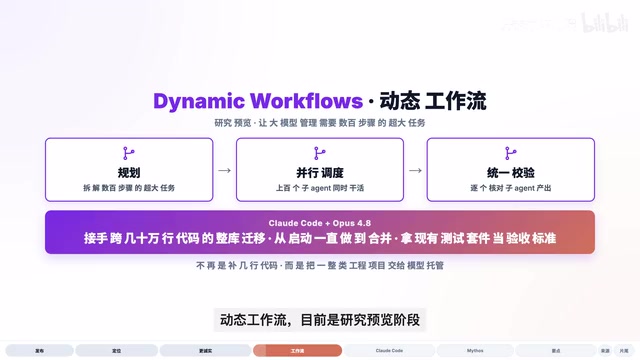
Dynamic Workflows:上百个子Agent并行调度
配合4.8的发布,Anthropic还推出了一个名为**Dynamic Workflows(动态工作流)**的新机制,目前处于研究预览阶段。
它解决的是一个非常现实的问题:像Opus这样的大模型,如何管理需要几百个步骤的超大任务?
Dynamic Workflows背后的核心是Multi-Agent系统架构。传统单一模型处理复杂任务时受限于上下文窗口长度和串行推理速度,而Multi-Agent架构将任务分解后交由多个独立Agent并行处理,每个子Agent专注于特定子任务,最终由协调器(Orchestrator)汇总结果。这种架构借鉴了分布式计算的思想,理论上可以将原本需要数小时的串行任务压缩至分钟级别。挑战在于子Agent之间的状态同步、错误传播控制以及最终结果的一致性校验,这也是Anthropic将其定位为「研究预览」而非正式功能的原因。
其工作流程分为三步:
- 规划阶段:模型先对任务进行整体规划和拆解
- 并行执行:调度上百个子Agent同时工作
- 统一校验:对每个子Agent的产出进行验证和整合
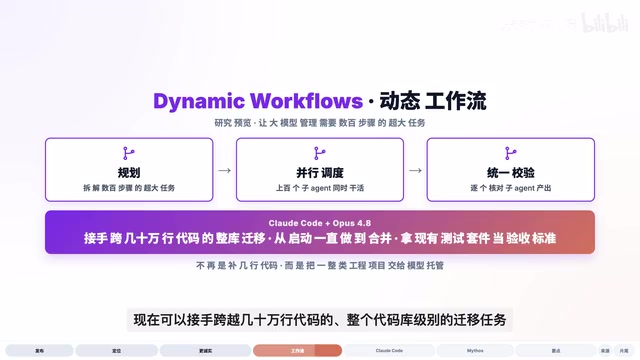
Anthropic给出的示例极具冲击力:Claude Code配合4.8,现在可以接手跨越几十万行代码的整个代码库级别的迁移任务——从启动一直做到合并,而且是拿现有的测试套件作为验收标准。这已经不是补全几行代码的层次,而是把一整类工程项目交给模型托管。
这对企业级开发场景的意义摆在眼前的事实。框架升级、语言迁移、架构重构这些过去需要团队花数周完成的工作,现在有了被AI大幅加速的可能性。
Claude Code的实际变化:额度重置与思考强度控制
对于Claude Code的订阅用户,这次有两个非常实在的变化:
1. Opus额度重置,促销加量
过去Opus的周额度卡得很紧,很多人舍不得用。这次随着4.8发布,周限额已被重置,所有用户手上的额度重新充满。而且当前还有一个50%的促销加量,一直持续到7月13日,Opus可用时长比平时更宽裕。
2. Effort Control(思考强度控制)
Effort Control功能对应AI领域近年兴起的「测试时计算扩展(Test-Time Compute Scaling)」理论。该理论由OpenAI的o系列模型验证:在推理阶段投入更多计算资源(让模型「多想一会儿」),可以显著提升复杂任务的准确率,而无需重新训练更大的模型。Anthropic的实现方式是控制模型的「扩展思考(Extended Thinking)」深度——低强度模式下模型快速给出答案,Max模式下模型会进行更多内部推理步骤再输出结果。
新增的Effort Control功能允许用户从「低」到「Max」自行选择模型投入多少算力。算力花得多,产出质量更好,但也更消耗额度。这个设计让用户可以根据任务复杂度灵活调配资源——简单任务用低强度快速完成,关键任务拉满算力确保质量。本质上是在推理质量与API成本之间提供了一个用户可控的权衡旋钮。
Dynamic Workflows也已经集成进Claude Code,面向Max、Team和企业版用户开放。
被锁着的Miscells:4.8不是终点
值得特别关注的是,Anthropic这次明确表态:4.8并不是他们手里最强的模型。
在4.8之上,还有一类被称为Miscells的模型,能力是「跳跃式领先」。此前Miscells因为网络安全方面的顾虑,只对极少数机构做了预览,不对公众开放。
Anthropic提到的「网络安全顾虑」指向其内部的AI安全评估体系——Responsible Scaling Policy(RSP)。该政策要求在模型能力达到特定阈值前,必须完成对应级别的安全评估,包括生化武器辅助能力、网络攻击能力等高风险场景的红队测试。Miscells模型因能力跳跃式提升,触发了更高级别的安全审查门槛。这种「能力越强、审查越严」的分级管控机制,是Anthropic区别于其他AI公司的核心策略之一,也是其获得大量安全导向投资者支持的重要原因。
但Anthropic在公告中透露,他们在安全防护上进展很快,预计在未来几周内就能把Miscells级别的模型开放给所有客户。
这意味着今天用到的4.8是公开可用的最强版本,而那个被锁起来的更强版本,可能很快就要解锁了。Anthropic的这种「先确保安全再开放能力」的策略,与其一贯强调的负责任AI发展路线一脉相承。
总结:可靠性才是AI进入生产环境的门票
Claude Opus 4.8这次升级的两个真正重点:
- 可靠性提升:模型更诚实,更少放过代码漏洞,更愿意主动提示风险,代码漏洞遗漏率降低约4倍
- Dynamic Workflows:将上百个子Agent的并行调度做成了能托管整个代码库迁移的工程级能力
价格没变,Claude Code里Opus的周额度刚被重置,还在促销加量期。如果你在用Claude Code或者在做AI Agent产品,现在是认真试试4.8的好时机。
而更值得期待的是,被锁着的Miscells可能就在未来几周内对所有人开放。在AI能力快速迭代的当下,4.8不是终点,只是通往下一个跳跃的台阶。
核心要点
- Claude Opus 4.8 放过代码漏洞的概率比 4.7 降低约 4 倍,模型变得更诚实、更可靠
- 新推出 Dynamic Workflows 机制,支持上百个子 Agent 并行调度,可托管跨越几十万行代码的整库迁移任务
- Claude Code 的 Opus 周限额已重置,并提供 50% 促销加量至 7 月 13 日,新增思考强度控制功能
- Anthropic 明确表示 4.8 之上还有更强的 Miscells 模型,预计未来几周内将向所有客户开放
- 价格未变,升级聚焦于修复 4.7 的注释啰嗦和工具调用出错问题,整体能力达到同代第一梯队
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。