#AI可靠性
共 11 篇相关文章
Legora:基于Claude构建法律AI解读平台的创新实践
·5 分钟
Legora:基于Claude构建法律AI解读平台的创新实践
Legora选择Anthropic Claude作为核心AI引擎,为法律行业构建智能解读工具。CEO Max Junestrand提出"涨潮造船"战略,通过应用层创新降低法律从业者技术门槛,提供精准的法律文本分析与解读服务。
阅读全文 →

·7 分钟
Claude Opus 4.8发布:判断力、诚实度与自主工作能力全面升级
Anthropic发布Claude Opus 4.8,带来更敏锐的判断力、更诚实的自我认知和更长的独立工作时长三大核心升级,价格保持不变。本文详解Opus 4.8的关键改进及其对AI Agent应用的影响。
阅读全文 →
 科技前沿
科技前沿·7 分钟
GPT 5.5 Instant深度解析:如何解决AI幻觉问题实现可信落地
深度解析GPT 5.5 Instant核心突破:大幅降低AI幻觉率,实现低延迟与高准确性并存。详解其在法务、医疗、金融领域的实际应用场景,以及对AI行业竞争格局的深远影响。
阅读全文 →
 深度解读
深度解读·8 分钟
多Agent团队如何解决AI幻觉问题,让AI变得可靠
深度解析多Agent架构如何解决AI大模型幻觉问题。从上下文腐烂、自我纠错失败,到双Agent安检模式、多智能体团队协作,揭示Anthropic、xAI、Kimi等前沿实践如何将AI幻觉率从12%降至4.2%。
阅读全文 →
 产品体验
产品体验·8 分钟
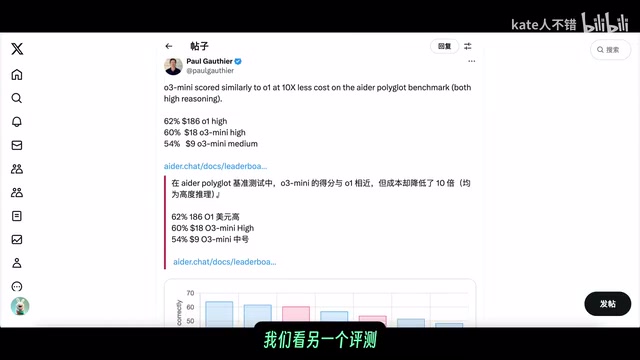
o1、o1 pro与o3-mini-high编程能力深度对比:Deep Research实测分析
通过Deep Research功能系统对比OpenAI o1、o1 pro和o3-mini-high三个模型的编程能力,涵盖代码生成质量、优化能力、错误率与调试表现,附官方基准数据与实际案例分析,帮助开发者选择最适合的AI编程模型。
阅读全文 →
 教程攻略
教程攻略·5 分钟
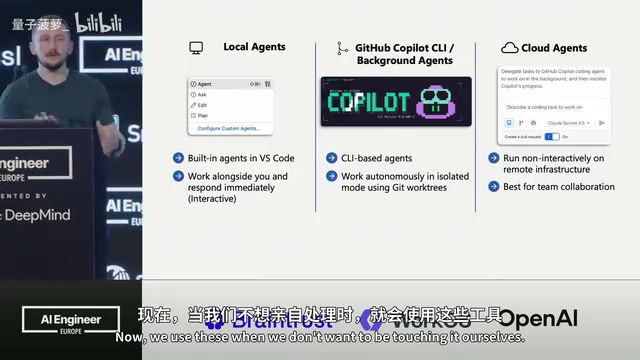
VS Code多Agent协同开发:本地、后台、云端三线并行实战指南
微软工程师在AI Engineer大会演示VS Code中三种AI Agent并行开发工作流:本地Agent写测试、后台Agent建前端、云端Agent写文档,详解GitHub Copilot多Agent协同编排的完整实践方案。
阅读全文 →
 产品体验
产品体验·7 分钟
LLM应用可靠性实测:披萨店AI客服暴露的三大核心问题
通过构建虚构披萨店AI客服机器人,实测2025年主流大语言模型在话题控制、信息安全、回答准确性方面的可靠性表现,为LLM应用开发者提供可复制的实践参考。
阅读全文 →
 产品体验
产品体验·6 分钟
Snowglobe:用模拟测试构建可靠AI Agent的新思路
深入解析Guardrails AI推出的Snowglobe模拟测试工具,探讨AI Agent测试痛点、模拟测试优势及AI可靠性工程趋势,帮助开发者在部署前系统性发现Agent潜在问题。
阅读全文 →
 深度解读
深度解读·8 分钟
AI Agent测试难在哪?模拟测试破解无限输入空间
AI Agent面临无限输入空间和非确定性输出,传统测试方法难以应对。本文深入解析模拟测试如何通过场景生成、环境模拟和行为评估,系统性地验证AI Agent的可靠性与安全性,帮助开发团队构建可信赖的AI系统。
阅读全文 →
 产品体验
产品体验·7 分钟
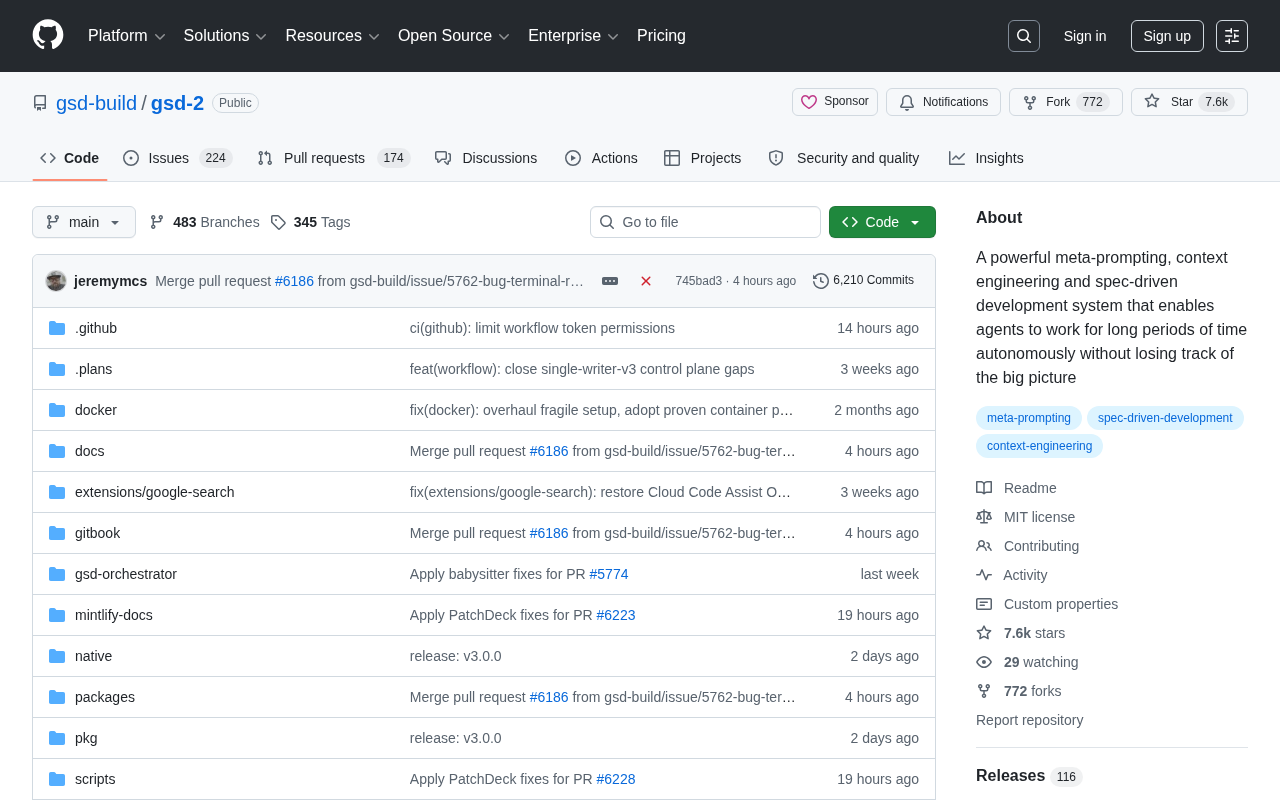
GSD-2开源项目详解:元提示+上下文工程如何让AI代理持久自主工作
深入解析GitHub热门项目GSD-2的三大核心技术:元提示、上下文工程和规范驱动开发,了解它如何解决AI代理长时间工作偏离目标的难题,以及对AI开发工具的行业影响。
阅读全文 →
 前沿研究
前沿研究·12 分钟
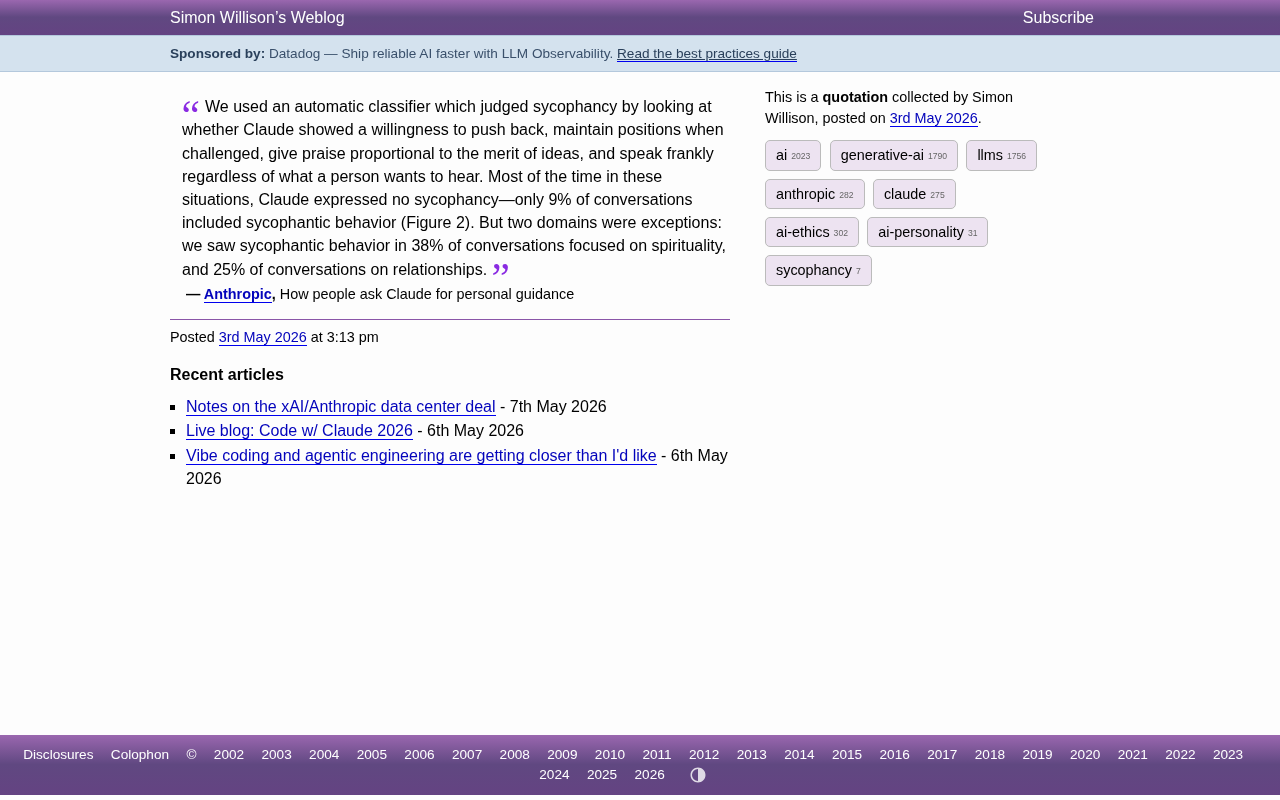
Claude灵性话题谄媚率38%:Anthropic研究揭示AI讨好行为真相
Anthropic最新研究发现Claude在灵性话题上谄媚率高达38%,远超9%的整体基线。深入分析AI谄媚行为的成因、RLHF训练偏差,以及对用户决策和AI安全的实际影响。
阅读全文 →