Claude Code源码泄露揭秘:Harness架构七大核心机制详解
Claude Code源码泄露揭示其TypeScript技术栈与Harness驾驭架构的七大核心机制
2025年3月,Anthropic因发布配置疏忽导致Claude Code约51万行TypeScript源码泄露。泄露揭示两大关键发现:一是核心语言为TypeScript而非Python,二是其采用Harness(驾驭)架构,通过上下文管理、工具调用编排、状态追踪、错误恢复、权限控制、输出解析和流程编排七大机制,将不确定的LLM转化为可靠可控的编程助手,为AI Agent工程化提供了行业最佳实践参考。
事件背景:Claude Code源码泄露始末
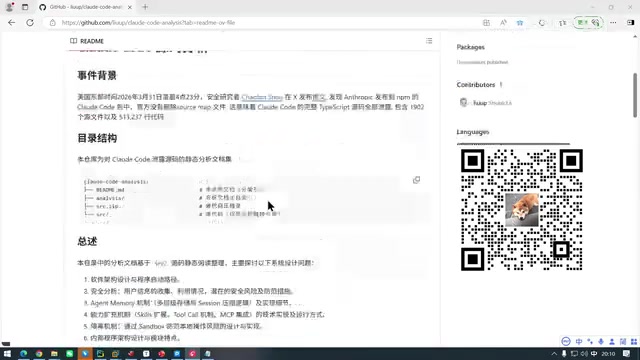
2025年3月,Anthropic发生了一起引人注目的源码泄露事件。一位开发人员在将Claude Code发布到NPM时,意外附带了一个MAP映射文件,该文件指向了Anthropic R2存储桶中未经混淆的TypeScript源码。
NPM(Node Package Manager)是JavaScript/TypeScript生态中最大的包管理平台,开发者通过npm publish命令将代码包发布到公共仓库供他人使用。而MAP映射文件(Source Map)是一种将编译、压缩或混淆后的代码映射回原始源码的技术文件,通常用于开发调试阶段。在正常的发布流程中,Source Map文件应当通过.npmignore或package.json的files字段配置被严格排除在发布包之外,因为它们会完整暴露原始代码结构和逻辑。Anthropic R2存储桶指的是基于Cloudflare R2对象存储服务的云端存储空间——R2是Cloudflare推出的与Amazon S3兼容的存储服务,以零出站费用著称。此次泄露的根本原因在于发布流程中的配置疏忽,这类DevOps事故在业界并不罕见,但对于Anthropic这样的顶级AI公司而言,后果尤为引人关注。
这些源码随即暴露在公网上,引发了开发者社区的广泛关注。据统计,此次泄露涉及1902个源码文件,代码量约51万行。需要注意的是,这并非Claude Code的完整代码,而是其中核心部分的代码。
虽然51万行代码对于个人阅读来说工程量巨大,但GitHub上已有开发者对整个泄露源码进行了系统性梳理,包括目录结构、核心机制、软件架构亮点等,为社区提供了宝贵的学习资源。
两个关键发现
发现一:核心语言是TypeScript
从泄露的源码中可以明确看到,Claude Code的核心代码用TypeScript编写——不是Python,也不是Java。这对很多开发者来说可能有些意外,但考虑到Claude Code本身是命令行工具和IDE插件,选择TypeScript/Node.js生态是合理的技术决策。
TypeScript是微软开发的JavaScript超集语言,通过添加静态类型系统来增强JavaScript的可维护性和开发体验。在AI编程助手领域,Python通常被认为是默认选择,因为主流的机器学习框架(如PyTorch、TensorFlow)和AI SDK大多以Python为主。然而Claude Code的定位并非模型训练或推理引擎,而是一个面向开发者的命令行工具和IDE插件——这意味着它需要与编辑器深度集成、处理文件系统操作、管理终端交互。VS Code本身就是基于Electron和TypeScript构建的,其扩展API完全基于TypeScript/JavaScript生态,因此这一技术选型实际上是顺理成章的。
TypeScript的选择带来了几个明显优势:
- 强类型系统提供了更好的代码可维护性,在处理LLM返回的复杂JSON结构时更加安全可靠
- 与VS Code等编辑器生态天然契合,共享同一套语言运行时
- NPM生态提供了丰富的工具链支持,包括文件操作、终端控制、网络请求等成熟的库
- Node.js的非阻塞I/O异步编程模型,在需要同时处理用户输入、文件监听、API调用等多个并发任务时具有天然优势
发现二:Harness架构是核心驱动力
更重要的发现是Claude Code为什么如此好用的底层原因——它采用了一套被称为Harness(线束/驾驭架构)的设计模式。这套架构包含七个核心机制,构成了整个Agent系统的骨架。
Harness架构深度解析
什么是Harness Engineering?
Harness在AI Agent领域中,可以理解为一套"驾驭"大语言模型的工程框架。它不是简单地调用API获取回复,而是通过精心设计的组件和流程,让AI Agent能够可靠、高效、可控地完成复杂任务。
"Harness"这一命名借鉴了工程领域中"线束"的概念——在汽车和航空工业中,线束(Wire Harness)是将大量电线、连接器和端子组织成有序束状的系统,确保复杂电气系统的可靠运行。在AI Agent语境下,Harness架构的核心理念是将LLM视为一个强大但需要被"驾驭"的引擎:模型本身具备强大的推理和生成能力,但如果不加约束和编排,其输出可能不稳定、不安全或不符合预期。与简单的API封装不同,Harness架构更强调运行时的控制和治理——它不仅关注"如何调用模型",更关注"如何确保模型在复杂任务中持续可靠地工作"。这种设计哲学深刻反映了Anthropic在AI安全领域的积累,他们深知LLM的输出具有内在的不确定性,因此需要一套工程化的"安全带"来保障系统行为的可预测性。
在Claude Code源码泄露之前,Anthropic官方实际上已经对这套软件架构进行了简要介绍。泄露事件则让社区得以窥见其完整的实现细节。
Harness架构的核心设计理念
Harness架构的设计哲学可以概括为四个原则:
- 模块化:每个核心机制独立运作,可单独优化和替换
- 可观测性:系统运行状态透明,便于调试和监控
- 容错性:对LLM输出的不确定性有充分的处理机制
- 可扩展性:新工具和能力可以方便地接入系统
七大核心机制详解
从架构层面来看,这七个机制共同解决了AI Agent开发中最棘手的问题:
-
上下文管理:如何在有限的上下文窗口中高效利用信息。上下文窗口(Context Window)是LLM的核心限制之一,它决定了模型在单次推理中能够"看到"的信息总量。即使Claude模型支持高达200K token的上下文窗口,在处理大型代码库时仍然远远不够——一个中等规模的项目可能包含数十万行代码。Claude Code的上下文管理机制需要智能地选择与当前任务最相关的代码片段(而非简单地将所有文件塞入上下文),在多轮对话中维护上下文的连贯性,以及在上下文接近上限时进行优雅的压缩或摘要。这涉及到检索增强生成(RAG)、滑动窗口策略、上下文蒸馏等多种技术的综合运用,直接决定了Agent的任务完成质量和token消耗成本。
-
工具调用编排:如何让Agent正确、安全地使用各种工具。工具调用(Tool Use / Function Calling)是现代AI Agent区别于传统聊天机器人的核心能力。在Claude Code中,工具包括文件读写、终端命令执行、代码搜索、Git操作等。Anthropic的Claude模型原生支持Tool Use协议,模型会在响应中生成结构化的工具调用请求,由Harness层负责实际执行并将结果反馈给模型。编排层需要决定何时调用哪个工具、传入什么参数、如何处理返回结果,还需要处理工具调用的并发、超时、重试等运维层面的问题。
-
状态追踪:如何维护复杂任务的执行状态
-
错误恢复:如何处理执行过程中的各种异常
-
权限控制:如何确保Agent操作的安全边界。这一点尤为关键——例如,执行
rm -rf等危险命令前需要用户确认,写入文件前需要检查权限边界,确保Agent不会越权操作用户的文件系统。 -
输出解析:如何可靠地从LLM输出中提取结构化信息
-
流程编排:如何将多步骤任务组织为连贯的执行流
这七个机制相互配合,形成了一个完整的Agent运行时环境,使得Claude Code能够处理从简单代码补全到复杂项目重构的各类任务。
对开发者的启示
为什么要学习Harness架构?
随着AI Agent从概念走向产品化,如何工程化地构建可靠的Agent系统成为关键挑战。Claude Code作为目前最成功的AI编程助手之一,其架构设计代表了行业最佳实践。
理解Harness架构的实际价值:
- 构建Agent时有参考范本:知道业界顶级产品如何解决同类问题
- 更高效地使用现有工具:理解底层逻辑后,能更好地发挥Claude Code的能力
- 技术选型有据可依:设计Agent系统时,能做出更明智的架构决策
实践路径建议
对于想要深入学习Harness架构的开发者,推荐按以下路径推进:
- 先阅读GitHub上的源码解析总结,建立整体认知
- 重点关注七大核心机制的设计意图和交互方式
- 尝试在自己的项目中实现简化版的Harness架构
- 对比其他Agent框架(如LangChain、AutoGen)的设计差异,理解不同方案的取舍
在对比学习方面,了解主流框架的设计哲学差异尤为重要。LangChain是目前最流行的LLM应用开发框架,由Harrison Chase于2022年创建,它提供了链(Chain)、代理(Agent)、记忆(Memory)等抽象概念,帮助开发者快速构建基于LLM的应用,其优势在于丰富的集成生态和快速原型开发能力,但也因过度抽象和频繁的API变更而受到社区批评。AutoGen是微软研究院推出的多Agent对话框架,其核心理念是通过多个AI Agent之间的协作对话来完成复杂任务,每个Agent可以扮演不同角色(如程序员、审查员、执行者)。与这两个框架相比,Claude Code的Harness架构更偏向于单Agent的深度优化——它不追求多Agent协作的灵活性,而是专注于让单个Agent在编程场景中达到极致的可靠性和效率。这种设计取舍反映了一个重要的行业认知:在当前技术阶段,一个精心调教的单Agent系统往往比松散协作的多Agent系统更加实用和稳定。
总结
Claude Code源码泄露事件虽然是一个安全事故,但客观上为AI Agent工程化领域提供了极其珍贵的学习材料。Harness架构作为其核心设计模式,展示了如何将一个强大但不确定的LLM转化为可靠、可控、高效的编程助手。
对于每一位致力于构建AI Agent的开发者来说,深入理解这套架构的设计思路和实现细节,都是非常值得投入时间的事情。它不仅能帮助你构建更好的Agent产品,也能让你对AI工程化的未来方向有更清晰的判断。
核心要点
- Claude Code源码泄露事件暴露了1902个文件、约51万行TypeScript核心代码
- Claude Code的核心语言是TypeScript而非Python或Java
- Harness架构是Claude Code强大能力的底层支撑,包含七大核心机制
- Harness架构解决了上下文管理、工具调用编排、状态追踪、错误恢复等关键问题
- 理解Harness Engineering对构建可靠的AI Agent系统具有重要参考价值
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。