大模型设计的"差就好"哲学:简单粗暴为何胜过精致复杂

DeepSeek V4弃用N-gram,因为大模型架构的核心法则是训练速度优先于理论精巧。
DeepSeek V4放弃N-gram技术,体现了大模型圈"差就好"的潜规则:简单、能跑、快比精致复杂更重要。文章提出三条铁律——架构要与GPU硬件对齐以最大化MFU、快速迭代比理论正确更重要(Scaling Law加持)、统一架构比拼凑组件更高效。Transformer统治AI领域的根本原因不是理论最优,而是矩阵乘法与GPU完美匹配,训练速度最快。
DeepSeek V4为何弃用N-gram?一个反直觉的选择
很多人注意到DeepSeek V4明明拥有N-gram技术,却选择不用,走了一条看似"笨拙"的路线。这背后隐藏着大模型圈的一条潜规则——差就好。
N-gram是自然语言处理中的经典统计方法,其核心思想是用连续的N个词(或token)组成的序列来建模语言的局部依赖关系。例如,bigram(N=2)关注相邻两个词的共现概率,trigram(N=3)则考虑三个词的组合。在现代大模型中,N-gram技术常被用于推测解码(Speculative Decoding)等加速推理的场景——通过一个轻量级的N-gram模型快速预测候选token,再由主模型验证,从而减少自回归生成的延迟。DeepSeek此前在V3/R1中曾探索过Multi-token Prediction(MTP)结合N-gram的方案,但V4最终选择放弃这一路线,背后的考量正是本文讨论的核心。
这不是说技术真的差,而是在大模型的世界里,比起精致复杂的设计,简单、能跑、快才是核心追求。理解了这个逻辑,你就能看懂当下几乎所有主流大模型的架构选择。
大模型架构设计的两大流派
做大模型的团队,大致可以分为两个流派:
- 学院派:追求精致摆盘,每一个设计都要有理论支撑,力求参数效率最优
- 野兽派:追求快速出锅,结构简单统一,能充分利用硬件算力

曾经有位博士做了一个非常精巧的模型,号称只用别人十分之一的参数就能达到同样效果。但当被问到这个模型在A100显卡上能发挥多少实力时,答案是——大概5%。
这里涉及一个关键指标:MFU(Model FLOPs Utilization,模型浮点运算利用率),它衡量的是模型训练时实际消耗的算力占GPU理论峰值算力的比例。以NVIDIA A100为例,它拥有6912个CUDA核心和432个Tensor Core,理论峰值算力达到312 TFLOPS(BF16)。业界顶尖团队通常能将MFU优化到50%-65%,而设计不当的模型可能只有个位数。以一个拥有数千张GPU的训练集群为例,MFU从5%提升到60%,意味着同样的硬件投入下训练速度提升12倍,或者说原本需要一年的训练周期可以缩短到一个月。考虑到大模型训练的GPU租赁成本动辄数千万甚至上亿美元,MFU的差异直接决定了一个项目的经济可行性。
这就好比你有一口顶级大锅,结果每次只敢放一点点食材,还煮得特别慢。而野兽派的做法是把显卡65%的算力都用上,一天就能消化几个TB的数据。学院派的精致在"跑得快"面前,就是硬伤——数据喂不进去,再完美的设计也没用。
"差就好"的三条铁律
铁律一:简单不等于简陋,而是与GPU硬件对齐
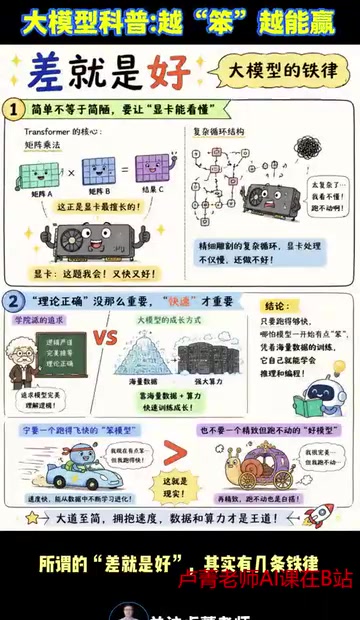
Transformer的核心计算就是矩阵乘法,这恰好是GPU最擅长的运算。GPU之所以成为深度学习的核心硬件,关键在于其大规模并行计算架构。以A100的Tensor Core为例,它可以在单个时钟周期内完成一个4×4矩阵的乘加运算。Transformer的自注意力机制和前馈网络本质上都是大规模矩阵乘法(GEMM),这与GPU的硬件特性完美匹配。相比之下,包含复杂条件分支、递归依赖或不规则内存访问模式的结构(如传统RNN的逐步递推),会导致GPU大量核心闲置,实际利用率可能低至个位数百分比。
如果你设计一套精细雕刻的复杂循环结构,显卡处理起来不仅慢,还做不好。好的架构设计,本质上是与硬件对齐。不是为了理论上的优雅,而是为了让每一块显卡都能满负荷运转。
铁律二:理论正确没那么重要,快速迭代才重要
学院派追求模型完美理解逻辑,但大模型的成长靠的是海量数据和算力。这一观点的理论基础是Scaling Law(缩放定律)。2020年OpenAI发表的研究表明,大语言模型的性能(以交叉熵损失衡量)与模型参数量、训练数据量和训练计算量之间存在幂律关系,且这种关系在多个数量级上保持稳定。这意味着,只要能持续增加计算量和数据量,模型性能就会可预测地提升。在这一框架下,模型架构的"精巧程度"对最终性能的贡献远不如训练规模的扩大。
只要跑得够快,哪怕模型一开始有点"笨",凭着海量数据的训练,它自己就能学会推理。因此,一个能以更高吞吐量消化更多数据的"简单"架构,在Scaling Law的加持下,最终会超越一个训练缓慢但理论上更优雅的复杂架构。
宁要一个跑得飞快的"笨"模型,也不要一个精致但跑不动的"好"模型。 这就是大模型训练的现实逻辑。
铁律三:统一架构比拼凑组件更高效

别总想着把各种先进的小结构拼在一起。那就像把不同品牌的零件拼成一辆车,看起来全是大牌,实际根本不兼容。
野兽派坚持统一标准,所有计算遵循同一个逻辑——就像批量生产的汽车,组装简单,跑起来又快又稳。而且野兽派很务实:搞定80%的场景就够了,剩下的20%等硬件升级、算力堆上去,自然就解决了。
DeepSeek V4的架构选择正是这一理念的体现。其核心创新包括对MoE(Mixture of Experts,混合专家)架构的持续优化和对训练流水线的深度工程调优。MoE架构通过在每一层设置多个"专家"子网络,每次推理只激活其中一部分,从而在不显著增加计算量的前提下大幅扩展模型参数量。V4放弃N-gram等辅助模块,正是为了保持MoE主干架构的纯净性和训练流水线的高效性——任何额外的分支结构都可能打破精心优化的计算图,导致通信开销增加和流水线气泡(Pipeline Bubble),最终拖累整体训练速度。
本质:大模型对训练效率的绝对崇拜
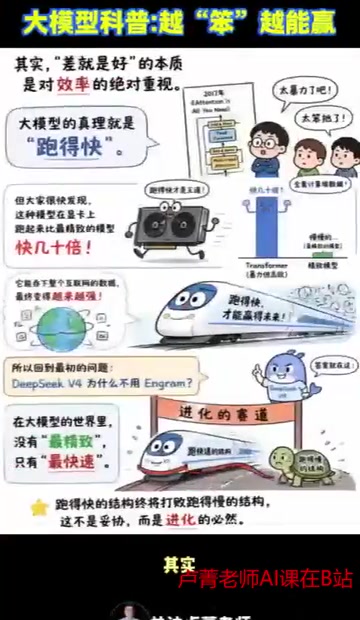
"差就好"的本质,是对效率的绝对重视。大模型的信仰就是跑得快。
回顾2017年那篇划时代的论文《Attention Is All You Need》,刚发表时很多人觉得它太暴力、太笨拙,全靠计算堆数据。在此之前,序列建模的主流方案是LSTM和GRU等循环神经网络,它们虽然理论上能捕捉长距离依赖,但由于时间步之间的串行依赖,无法充分利用GPU的并行计算能力。Transformer用自注意力机制(Self-Attention)替代了循环结构,使得序列中所有位置的计算可以同时进行。虽然自注意力的计算复杂度为O(n²),看似"暴力",但由于其运算本质是矩阵乘法,在GPU上的实际吞吐量远超理论上更"高效"的循环结构。
但事实证明,Transformer这种结构在GPU上跑起来比最精致的模型快几十倍,它能吞下整个互联网的数据,最终变得越来越强。这一架构后来催生了GPT、BERT、LLaMA等一系列里程碑模型,成为当今几乎所有大语言模型的基础骨架。
这就是为什么Transformer统治了整个AI领域——不是因为它理论最优美,而是因为它最快。
结论:最快的架构终将胜出
回到最初的问题:DeepSeek V4为什么不用N-gram?
答案很清晰:N-gram虽然精巧,但只要拖累了训练速度,就不符合"跑得快"的生存法则。在大模型的世界里,没有最精致,只有最快速。最快的结构终将打败跑得慢的结构,这不是妥协,而是进化的必然。
对于正在学习AI的同学来说,这个认知非常重要:不要迷恋论文里那些花哨的trick,要关注哪些设计能真正在大规模训练中跑起来。工程能力和系统思维,往往比理论创新更决定一个模型的成败。
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。