#大模型架构设计
共 4 篇相关文章
 深度解读
深度解读·6 分钟
大模型设计的"差就好"哲学:简单粗暴为何胜过精致复杂
解析大模型架构设计中的"差就好"哲学:为什么DeepSeek V4弃用N-gram?为什么Transformer统治AI领域?从硬件对齐、快速迭代、统一架构三条铁律,揭示简单高效的模型设计为何总能胜过精致复杂的方案。
阅读全文 →
 深度解读
深度解读·10 分钟
Transformer架构核心原理:自注意力机制与工程优化深度解析
深度解析Transformer架构核心原理,涵盖自注意力机制QKV本质、Encoder-Decoder结构、Flash Attention显存优化、RoPE位置编码、GQA推理加速等工程落地方案,助你从面试到实战全面掌握大模型底层架构。
阅读全文 →
 产品体验
产品体验·9 分钟
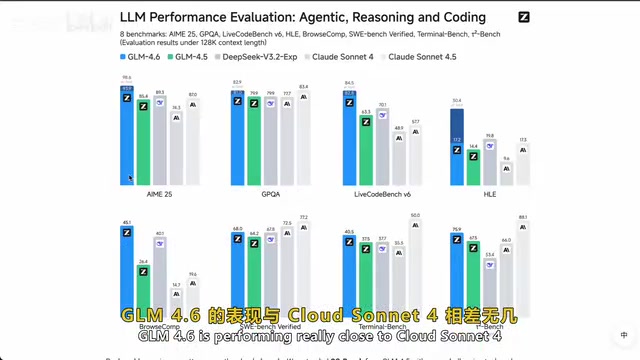
GLM-4.6深度实测:性能、价格与编程能力全面评估
深度实测智谱AI开源模型GLM-4.6,从MoE架构、编程实战、价格对比到适用场景全面解析。输入价格仅$0.06/百万Token,比Claude便宜7-20倍,一次生成代码无需调试,帮你判断是否值得纳入技术栈。
阅读全文 →
 产品体验
产品体验·8 分钟
DeepSeek API集成生态解析:3.7万星GitHub项目为何爆火
深度解析DeepSeek官方开源项目awesome-deepseek-integration,37000+星标背后的生态战略、开发者集成方案与行业价值,涵盖IDE插件、聊天客户端、自动化工作流等主流场景。
阅读全文 →